计算机网络
计算机网络和因特网
什么是Internet?
从具体构成角度
节点
- 主机及其以上运行的应用程序
- 路由器、交换机等网络交换设备
边:通信链路
- 接入网链路:主机连接到互联网的链路
- 主干链路:路由器间的链路
数以亿计的、互联的计算设备
- 主机 = 端系统
- 运行 网络应用程序
通信链路
- 光纤、同轴电缆、无线电、卫星
- 传输速率 = 带宽(bps)
分组交换设备:转发分组(packet)
- 路由器和交换机
协议控制发送、接收消息
- 如:TCP、IP、HTTP、FTP、PPP
Internet:网络的网络
- 松散的层次结构,互联的ISP
- 公共的Internet vs,专用intranet
Internet标准
- RFC:Request for comments
- IETF:Internet Engineering Task Force
从服务角度
使用通信设施进行通信的分布式应用
- Web、VoIP、email、分布式游戏、电子商务、社交网络 ……
通信基础设施为apps提供编程接口(通信服务)
- 将发送和接收数据的apps与互联网连接起来
- 为app应用提供服务选择,类似于邮政服务:
- 无连接不可靠服务
- 面向连接的可靠服务
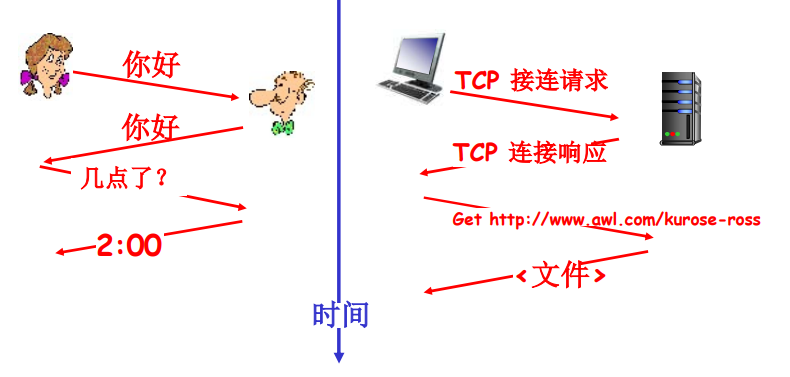
什么是协议?
人类协议
你好—> 你好 。
发送特定的消息、收到消息是采取的特定行动或其他事件
网络协议
- 类似人类协议
- 机器之间的协议而非人与人之间的协议
- Internet中所有的通信行为都受协议制约
协议定义了在两个或多个通信实体之间交换的报文格式和次序,以及在报文传输和/或接收或其他时间方面所采取的动作
人类和计算机网络协议示例:
网络结构
- 网络边缘
- 主机
- 应用程序(客户端和服务器)
- 网络核心
- 互联着的路由器
- 网络的网络
- 接入网、物理媒体
- 有线或者无线通信链路
网络边缘
端系统(主机)
- 运行应用程序
- 如Web、email
- 在 “网络的边缘”
客户/服务器模式
- 客户端向服务器请求、接收服务
- 如Web浏览器/服务器:email 客户端/服务器
对等(peer-peer)模式
- 很少(甚至没有)专门的服务器
- 如 Gnutella、KaZaA、Emule
采用网络设施的面向连接服务
目标:在端系统之间传输数据
握手:在数据传输之前做好准备
- 人类协议中:你好、你好
- 两个通信主机之间为连接建立状态
TCP - 传输控制协议(Transmission Control Protocol)
- Internet上面向连接的服务
TCP服务
- 可靠地、按顺序地传送数据
- 确认和重传
- 流量控制
- 发送方不会淹没接收方
- 拥塞控制
- 当网络拥塞时,发送方降低发送速率
采用基础设施的无连接服务
目标:在端系统之间传输数据
- 无连接服务
UDP - 用户数据报协议(User Datagram Protocol)[RFC 768]:
- 无连接
- 不可靠数据传输
- 无流量控制
- 无拥塞控制
使用TCP的应用:
- HTTP(Web)
- FTP(文件传送)
- Telnet(远程登录)
- SMTP(email)
使用UDP的应用:
- 流媒体
- 远程会议
- DNS
- Internet电话
网络核心
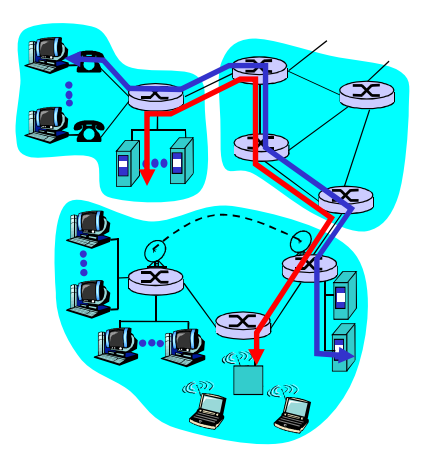
网络核心:路由器的网状网络(即由互联因特网端系统的分组交换机和链路构成的网状网络)
数据怎样通过网络进行传输?
电路交换:
为每个呼叫预留一条专有电路:如电话网
分组交换:
- 将有传送的数据分成一个个单位:分组
- 将分组从一个路由器传到相邻路由器(hop),一段段最终从源端传到目标端
- 每段:采用链路的最大传输能力(带宽)
电路交换
在电路交换网络中,在端系统键通信会话期间,预留了端系统间沿路径通过所需要的资源(缓存、链路传输速率)
端到端的资源被分配给从源端到目标端的呼叫“call”:
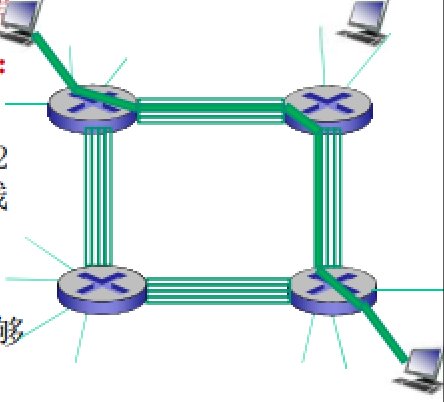
- 图中,每段链路有4条线路:
- 该呼叫采用了上面链路的第2个线路,右边链路的第1个线路(piece)
- 独享资源:不同享
- 每个呼叫一旦建立起来就能够保证性能
- 如果呼叫没有数据发送,被分配的资源就会被浪费(no sharing)
- 通常被传统电话网络采用
为呼叫预留端—端资源
- 链路带宽、交换能力
- 专用资源:不共享
- 保证性能
- 要求建立呼叫连接
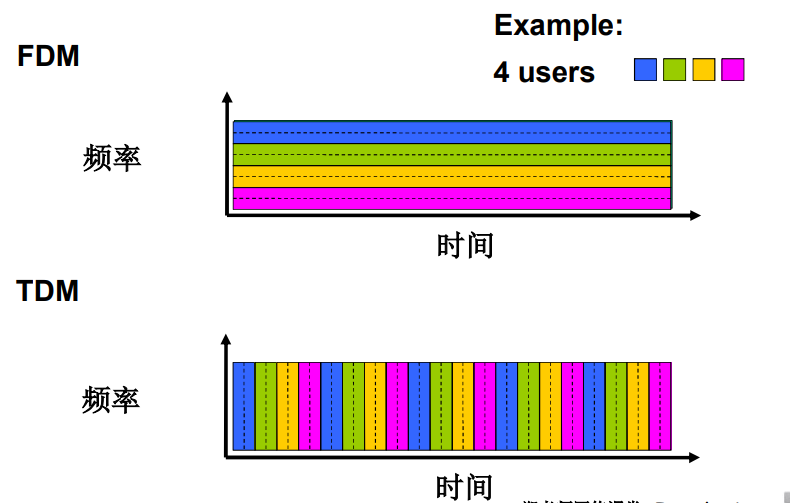
网络资源(如带宽)被分成片
- 为呼叫分配片
- 如果某个呼叫没有数据,则其资源片处于空闲状态(不共享)
- 将带宽分成片
- 频分(Frequency-division multiplexing)
- 时分(Time-division multiplexing)
- 波分(Wave-division multiplexing)
电路交换:FDM 与 TDM
计算举例:

电路交换不适合计算机之间的通信的原因:
- 连接建立时间长
- 计算机之间的通信有突发性,如果使用线路交换,则浪费的片较多
- 即使这个呼叫没有数据传递,其所占据的片也不能够被别的呼叫使用
- 可靠性不高
分组交换
分组交换
以分组为单位存储—转发方式
- 网络带宽资源不再分为一个个片,传输时使用全部带宽
- 主机之间传输的数据被分为一个个分组
资源共享,按需使用:
- 存储-转发:分组每次移动一跳(hop)
- 转发之前,节点必须收到整个分组
- 延迟比线路交换要大
- 排队时间
在源和目的地之间,每个分组都通过通信链路和分组交换机传送,交换机主要有路由器和链路层交换机两类,分组以等于该链路最大传输速率的速度通过通信链路。
统计多路复用
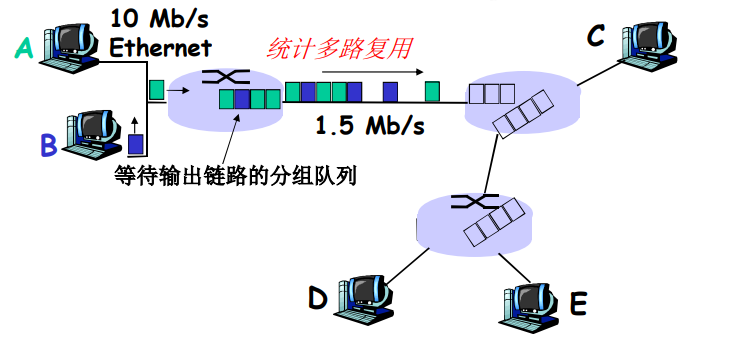
A&B 时分复用 链路资源
A&B 分组没有固定的模式 -> 统计多路复用
网络核心的关键功能
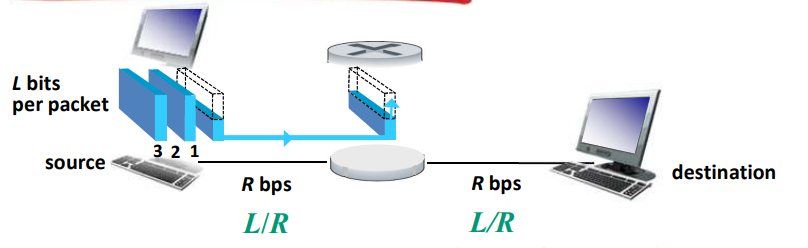
存储-转发

- 被传输到下一个链路之前,整个分组必须到达路由器:存储-转发
- 在一个速率为 R bps 的链路,一个长度为 L bits 的分组的存储转发延时: L/R s
例如:
L = 7.5 Mbits
R = 1.5Mbps
3次存储转发的延时 = 15 s
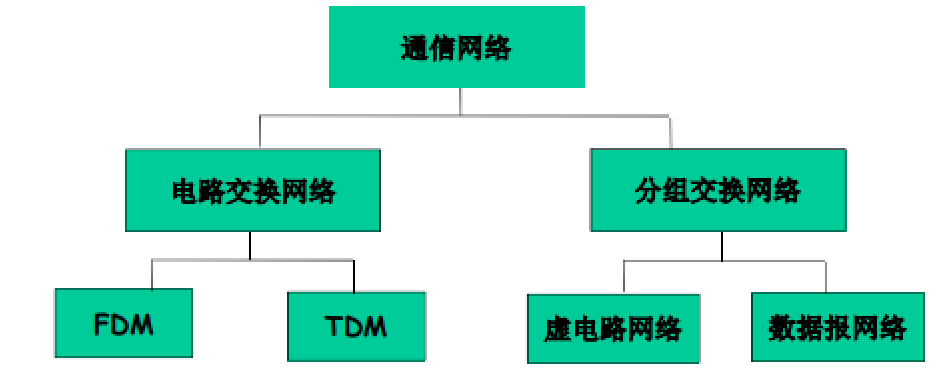
分组交换:分组的存储转发一段一段从源端传到目标端,按照有无网络层的连接,分成:
- 数据报网络:
- 分组的目标地址决定下一跳
- 在不同的阶段,路由可以改变
- 类似:问路
- Internet
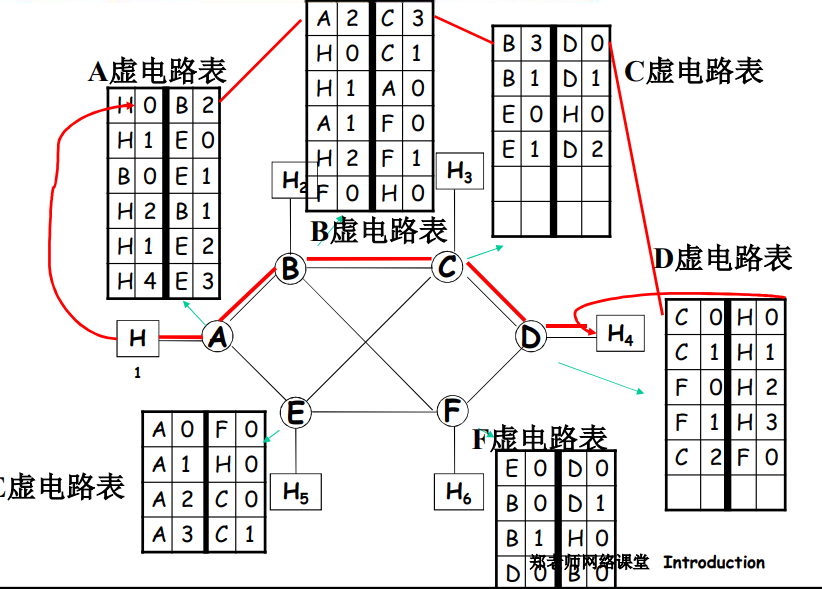
- 虚电路网络:
- 每个分组都带标签(虚电路标识 VCID),标签决定下一跳
- 在 呼叫建立时 决定路径,在整个呼叫中路径保持不变
- 路由器维持每个呼叫的状态信息
- X.25和ATM
数据报的工作原理
- 在通信之前,无需建立一个连接,有数据就传输
- 每一个分组都独立路由(路径不一样,可能会失序)
- 路由器 根据分组的目标地址进行路由
虚电路(virtual circuit)的工作原理
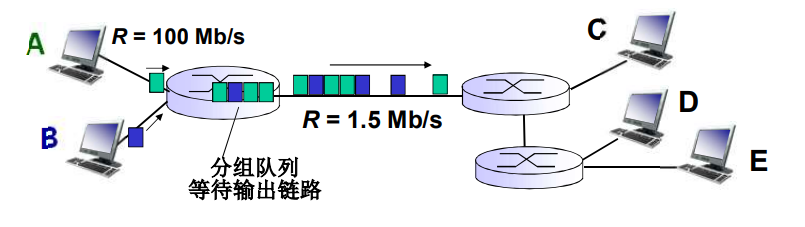
排队延迟和丢失
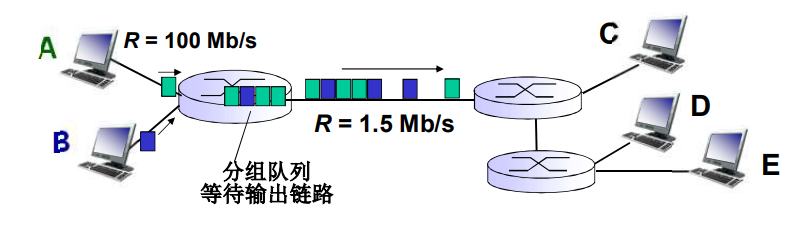
排队和延迟:
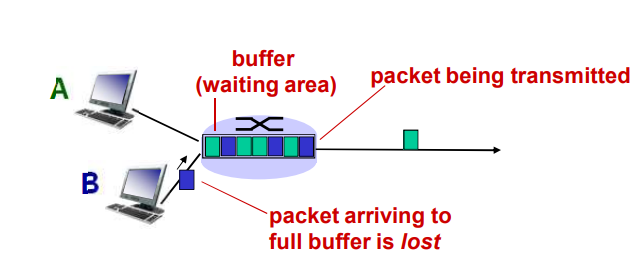
每台分组交换机有多条链路与之相连。对于每条相连的链路,该分组交换机具有一个输出缓存(output buffer,也称为输出队列(output queue)),它用于存储器准备发往哪条链路的分组。该输出缓存在分组交换中起着重要的作用。如果到达的分组需要传输到某条链路,但发现该链路正忙于传输其他分组,该到达分组必须在输出缓存中等待。因此,除了存储转发时延外,分组还要承受输出缓存的排队时延(queuing delay)。这些时延是变化的,变化的程度取决于网络的拥塞程度。因为缓存空间的大小是有限的,一个到达的分组可能发现该缓存已被其他等待传输的分组完全充满了。在此情况下,将出现分组丢失(丢包)(packet loss),到达的分组或已经排队的分组之一将被丢弃。
如果到达速率 > 链路的输出速率:
- 分组将会排队,等待传输
- 如果路由器的缓存用完了,分组将会被抛弃
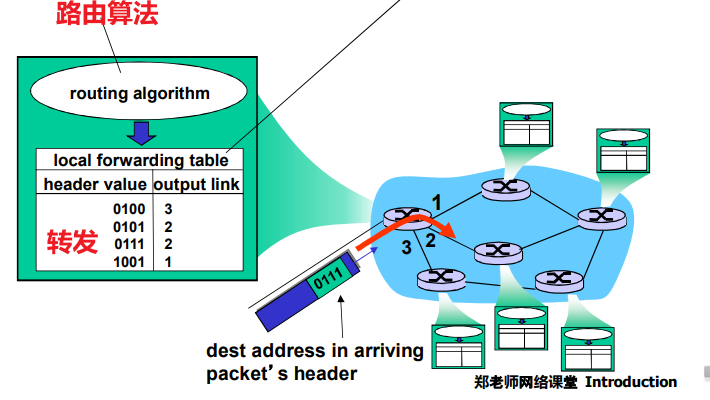
转发表和路由选择协议:
路由:决定分组采用的源到目标的路径
转发:将分组从路由器的输入链路转移到输出链路
在因特网中,每个端系统具有一个称为IP地址的地址。当源主机要向目标主机,要向目的端系统发送一个分组时,源在该分组的首部包含了目的地的 IP 地址,如同 邮政地址那样,该地址具有一种等级结构。当一个分组到达网络中的路由器是,路由器检查该分组的目的地址的一部分,并向一台相邻路由器转发该分组。特别的是,每台路由器具有一个 转发表(forwarding table),用于将目的地址(或者目的地址的一部分)映射称为输出链路。当某分组到达一台路由器时,路由器检查该地址,并用这个地址搜索其转发表,以发现适当的输出链路。路由器则将分组导向该输出链路。
以上解释了 路由器使用的分组的目的地址来索引转发表并决定适当的出链路。但是 转发表是如何进行设置的呢?
因特网具有一些特殊的 路由选择协议(routing protocol),用于自动地设置这些转发表。
例如:一个路由选择协议 可以决定从每台路由器到每个目的地的最短路径,并使用这些最短路径的结果来配置 路由器中的转发表。
电路交换 VS 分组交换
分组交换的性能优于电路交换的性能
同样的网络资源,分组交换允许更多用户使用网络
- 1 Mb/s 链路
- 每个用户:
- 活动时 100 kb/s
- 10% 的时间是活动的
- 电路交换:
- 10 用户
- 分组交换:
- 35 用户时
>= 10个用户活动的概率为 0.0004
分组交换是 ”突发数据的胜利者?“
- 适合于对突发式数据传输
- 资源共享
- 简单,不必建立呼叫
- 过度使用会造成网络拥塞:分组延时和丢失
- 对可靠地传输需要协议来约束:拥塞控制
- 怎样提供 类似电路交换的服务? * 保证音频/视频应用需要的带宽 * 一个 仍未解决的问题(chapter 7)
网络分类
接入网络和物理媒体
怎样将端系统和边缘路由器连接?
- 住宅接入网络
- 单位接入网络(学校、公司)
- 无线接入网络
注意:
- 接入网络的带宽(bits per second) ?
- 共享/专用?
接入网
考虑了位于 ”网络边缘“ 的应用程序 和 法人系统后,下面考虑 接入网,这是指将端系统物理连接到其 边缘路由器(edge route)的网络
边缘路由器是指 端系统到任何其他远程端系统的路径上的第一台路由器
住宅接入:modem
- 将上网数据调制加载音频信号上,在电话线上传输,在局端将其中的数据解调出来;反之亦然
- 调频
- 调幅
- 调相位
- 综合调制
- 拨号调制解调器
- 56 Kbps 的速率直接接入路由器(通常更低)
- 不能同时上网和打电话:不能总是在线
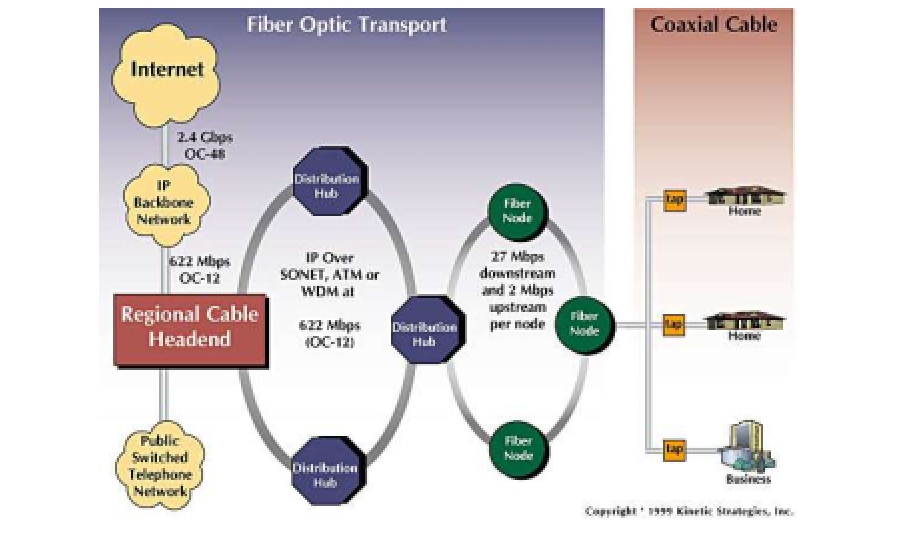
住宅接入:线缆模式
数字用户线
数字用户线(digital subscriber line (DSL))
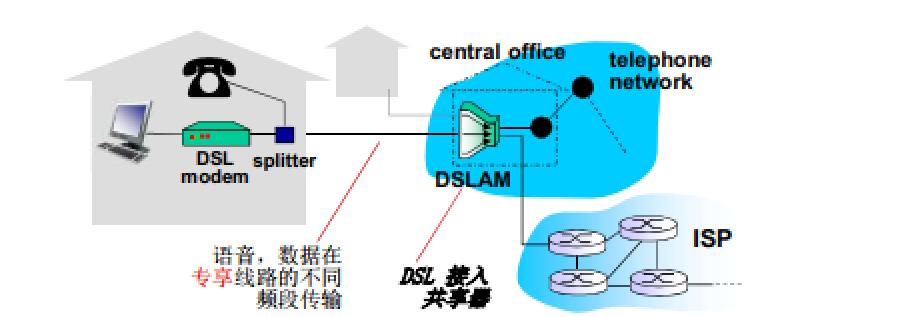
- 采用 现存的 到交换局 DSLAM(数字用户线接入复用器)的电话线
- DSL 线路上的数据被传到互联网
- DSL 线路上的语音被传到电话网
- < 2.5 Mbps 上行传输速率(typical < 1 Mbps)
- < 24 Mbps 下行传输速率 (typical < 10 Mbps)
线缆网络
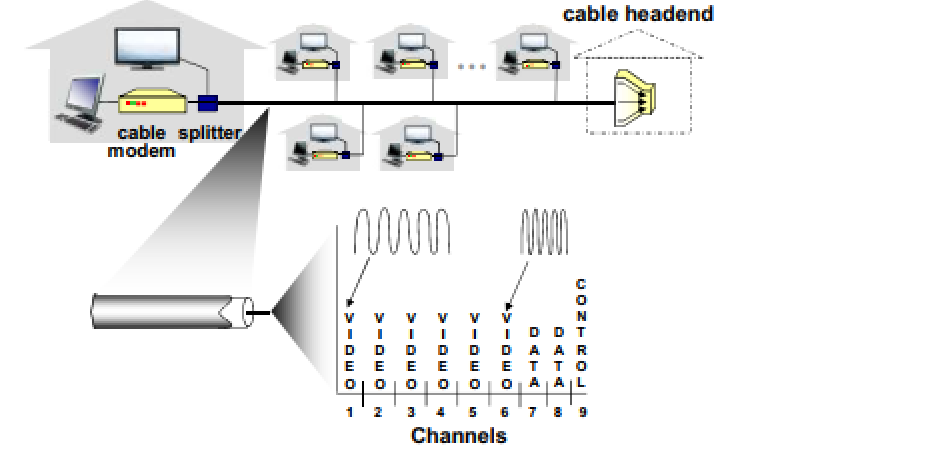
有线电视信号线缆双向改造
FDM:(频分复用)在 不同频段传输不同信道的数据,数字电视和 上网数据(上下行)
将 整个带宽(频率)分成多个频带,用户在通信过程中 始终 占用这个频带。
频分复用的所有用户在同一时间占用不同的带宽资源(频率)
频分复用是一种模拟技术,以链路带宽(以Hz为单位)大于要传输的信号的带宽之和时采用。
防护频带是指在通道之间狭长未被使用的带宽,这部分用来隔离信号,防止信号重叠
复用过程:
- 将信号调制到不同频率的载波上
- 将调制过的模拟信号叠加成复合信号
- 通过足够带宽的介质发送出去
复用分离过程:
- 使用滤波器将复合信号分解成组成它的各个信号
- 使用解调器,将信号还原
TDM:(时分复用)所有参与复用的用户在 不同的时间 占用 相同的频带宽度
时分复用是一个数字化过程,它允许多个连接共享一条高带宽链路
TDM是组合多个低俗通道为一个高速通道数据的复用技术
时隙和帧:
时隙:指的是一段时间,在这段时间内,某些网络设备或节点可以发送或接收数据。时隙通常由网络协议或协议栈中的某个组件分配或管理。时隙的长度可以是固定的,也可以是可变的,取决于网络协议或协议栈的设计。
帧:计算机网络中数据传输的基本单位。它包括了数据和一些必要的控制信息,如数据类型、原地址、目标地址、校验和等等。帧通常是由物理层或数据链路层协议定义的,以便在网络中传输数据。帧的长度也可以是固定的或可变的,取决于协议的设计。
FDM和TDM的优缺点
FDM(Frequency Division Multiplexing,频分复用)和TDM(Time Division Multiplexing,时分复用)都是多路复用技术,用于将多个信号合并在一条通信线路上进行传输。它们各自具有优点和缺点:
FDM的优点:
- 可以同时传输多个信号,且信号彼此独立,不会相互干扰。
- 在不同的频带上分配不同的信号,可以避免不同信号之间的干扰。
- FDM技术已经得到广泛的应用,在广播、电视、电话和计算机网络等领域都有应用。
FDM的缺点:
- 频带宽度有限,需要有足够的频带宽度才能支持多个信号的传输。
- 频带的利用率不高,因为不同信号之间的频带可能会有空闲,但不能用于传输其他信号。
TDM的优点:
- 可以使用相同的通信线路传输多个信号,提高了通信线路的利用率。
- 通过时间片的方式分配信号传输时间,可以避免不同信号之间的干扰。
- TDM技术具有较高的灵活性,可以根据需要调整不同信号的传输速率和优先级。
TDM的缺点:
- 对于传输速率较高的信号,需要分配更多的时间片,可能会导致其他信号的传输受到影响。
- 在传输过程中,如果某个信号的数据量过大,可能会导致其他信号的传输延迟。
总的来说,FDM适用于需要传输的信号数量较少且带宽较大的情况,而TDM适用于需要传输的信号数量较多且带宽较小的情况。在实际应用中,FDM和TDM也可以结合使用,以充分利用通信线路的带宽资源。
家庭网络
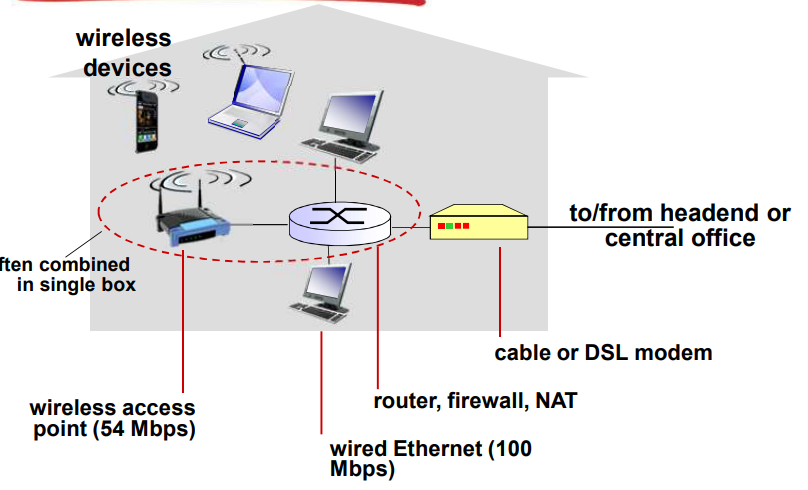
企业接入网络
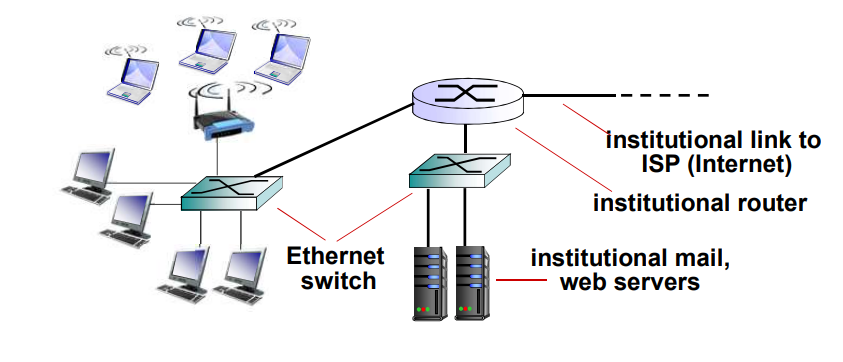
- 经常被企业或者大学等机构采用
- 10 Mbps,100 Mbps,1 Gbps,10 Gbps 传输率
- 现在,端系统经常直接接到以太网络交换机上
无线接入网络
各无线端系统共享无线接入网络(端系统到无线路由器)
- 通过基站或者叫接入点
无线LANs:
- 建筑物内部(100 ft)
- 802.11 b/g(WiFi):11,54 Mbps 传输速率
广域无线接入:
- 由电信运营商提供(cellular),10‘ s km
- 1 到 10 Mbps
- 3G,4G:LTE
物理媒体
概述
Bit:在发送-接收对间传播
物理链路:连接每个发送-接收对之间的物理媒体
导引型媒体:
- 信号沿着固体媒介被导引:同轴电缆、光纤、双绞线
非导引型媒体:
- 开放的空间传输电磁波或者光信号,在电磁或者光信号中承载数字数据
双绞线(TP)
两根绝缘铜导线拧合
- 5类:100 Mbps 以太网,Gbps千兆以太网
- 6类:10Gbps 万兆以太网
无屏蔽双绞线(UTP)
- 常用在建筑物内的计算机网络中(即局域网)
- 目前局域网中双绞线的数据速率为 10 Mbps 到 10Gbps,所能达到的数据传输速率取决于导线线径以及传输方和接收方之间的距离
DSL技术通过双绞线使住宅用户以超过数十 Mbps的速率接入因特网
关于DSL技术,DSL是“数字用户线”(Digital Subscriber Line)的缩写,它是一种基于电话线传输数据的技术,可以实现高速的互联网接入。DSL技术通过利用电话线的高频段传输数据,从而实现高速的数据传输。
DSL技术有多种类型,其中最常见的是ADSL和VDSL。ADSL是“异步数字用户线”(Asymmetric Digital Subscriber Line)的缩写,它可以实现下行速度较快、上行速度较慢的传输方式。VDSL是“高速数字用户线”(Very-high-bit-rate Digital Subscriber Line)的缩写,它可以实现更高的传输速度,同时也具有更高的成本。
DSL技术具有以下优点:
高速传输:DSL技术可以实现高速的数据传输,比传统的拨号上网方式要快得多。
实现网络和电话同时使用:DSL技术可以同时使用电话和网络,不会相互干扰。
稳定性较高:DSL技术的稳定性较高,因为它使用的是电话线这样的传输介质,信号不容易受到干扰。
不受距离限制:DSL技术不受距离限制,可以通过电话线在较远的距离内传输数据。
支持多种应用:DSL技术可以支持多种应用,包括互联网接入、视频流媒体、VoIP电话等。
尽管DSL技术有着许多优点,但它也有一些缺点。例如,DSL技术的传输速度和稳定性受到传输距离、线路质量和网络拥塞等因素的影响。此外,DSL技术的传输速度和稳定性也比不上光纤等其他传输介质。
总之,DSL技术是一种基于电话线传输数据的技术,可以实现高速的互联网接入。它具有高速传输、实现网络和电话同时使用、稳定性较高、不受距离限制和支持多种应用等优点,但也有一些缺点。
同轴电缆、光纤
同轴电缆:
- 两根同轴的铜导线
- 双向
- 基带电缆
- 电缆上一个单个信道
- Ethernet
- 宽带电缆
- 电缆上由多个信道
- HFC
光纤和光缆:
- 光脉冲,每个脉冲表示一个bit,在玻璃纤维中传输
- 高速:
- 点到点的高速传输(如 10 Gps - 100 Gbps 传输速率)
- 低误码率:在两个中继器之间可以由很长的距离,不受电磁噪声的干扰
- 安全
无线链路
- 开放空间传输电磁波,携带要传输的数据
- 无需物理 “线缆”
- 双向
- 传播环境效应:
- 反射
- 吸收
- 干扰
无线链路类型:
- 地面微波
- e.g. up to 45 Mbps channels
- LAN (e.g.,WiFi)
- 11 Mbps,54 Mbps,540Mbps …..
- wide-area (e.g.,蜂窝)
- 3G cellular:~几Mbps
- 4G 10Mbps
- 5G 数Gbps
- 卫星
- 每个信道 Kbps 到 45Mbps(或者多个聚集信道)
- 270 msec端到端延迟
- 同步精致卫星和地轨卫星
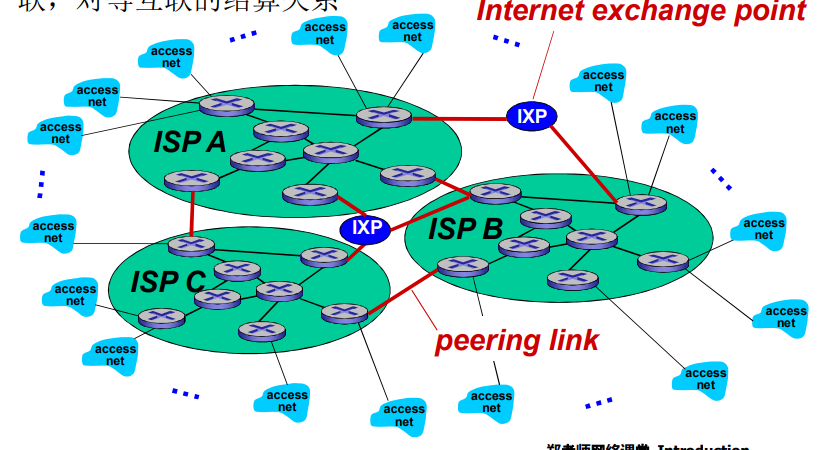
Internet结构和ISP
互联网络结构:网络的网络
- 端系统通过接入ISP(Internet Service Providers)连接到互联网
- 该接入ISP能够提供有线或无线连接,使用了DSL、电缆、FTTH(光纤到户)、WiFi和蜂窝等多种技术
- 住宅,公司和大学的ISP
- 接入ISPs相应的必须是互联的
- 因此任何2个端系统可相互发送分组到对方
- 导致的 “网络的网络” 非常复杂
- 发展和演化是通过经济的和国家的政策来驱动的
- 让我们采用渐进方法来描述当前互联网的结构
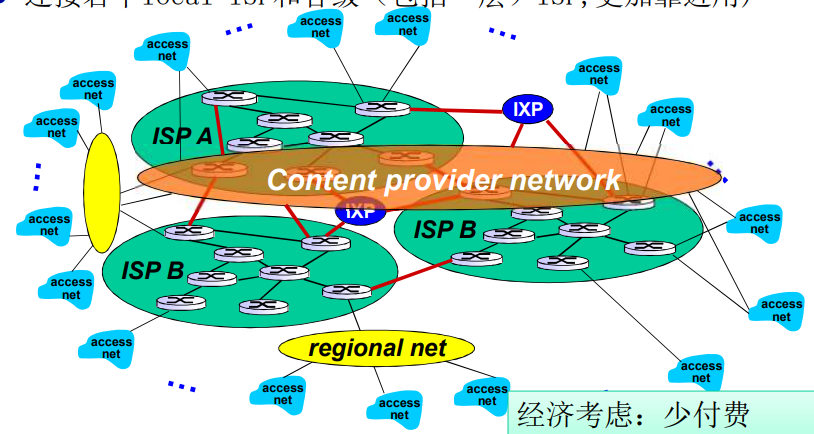
- 在网络的最中心,一些为数不多的充分连接的大范围网络(分布广、节点有限、但是之间有着多重连接)
- “ tier-1” commercial ISPs ,国家或者国际范围的覆盖
- content provider network : 将他们的数据中心接入 ISP,方便周边用户的访问;通常私有网络之间用专网绕过第一层 ISP 和
竞争:但如果全局ISP是有利可为的业务,那会有竞争者
合作:通过ISP之间的合作可以完成业务的扩展,肯定会有互联,对等互联的结算关系
ISP是“互联网服务提供商”(Internet Service Provider)的缩写,它是为用户提供互联网接入服务的企业或组织。ISP通常提供互联网接入、电子邮件、网站托管和虚拟主机等服务。
ISP可以分为两种类型:一种是接入ISP,它为用户提供互联网接入服务;另一种是内容ISP,它为用户提供互联网上的内容和服务。接入ISP是用户接入互联网的关键,因为它提供了用户接入互联网的技术和设备。
ISP通常提供多种互联网接入方式,包括拨号上网、DSL、光纤、卫星、无线等。用户可以根据自己的需要和预算选择合适的接入方式。在选择ISP时,用户需要考虑ISP提供的服务、价格、服务质量、技术支持等方面的因素。
ISP需要遵守法律和规定,包括网络安全、用户隐私、版权保护等方面的规定。ISP还需要保护网络的安全和稳定性,防止网络攻击和滥用。
总之,ISP是为用户提供互联网接入服务的企业或组织,它提供多种互联网接入方式和其他服务。在选择ISP时,用户需要考虑服务、价格、服务质量、技术支持等方面的因素。
network of network
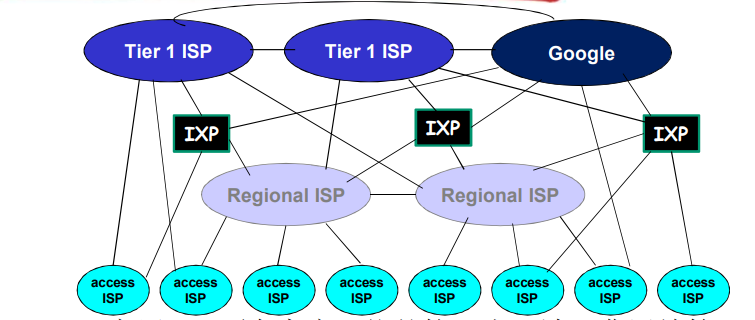
松散的层次模型
中心:第一层ISP(如UUNet,BBN/Genuity,Sprint,AT&T)国家/国际覆盖,速率极高
- 直接与其他第一层ISP相连
- 与大量的第二层ISP和其他客户网络相连
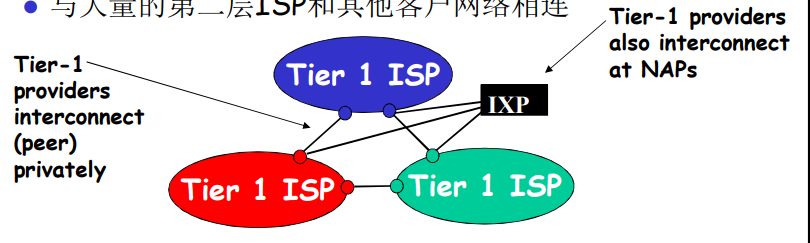
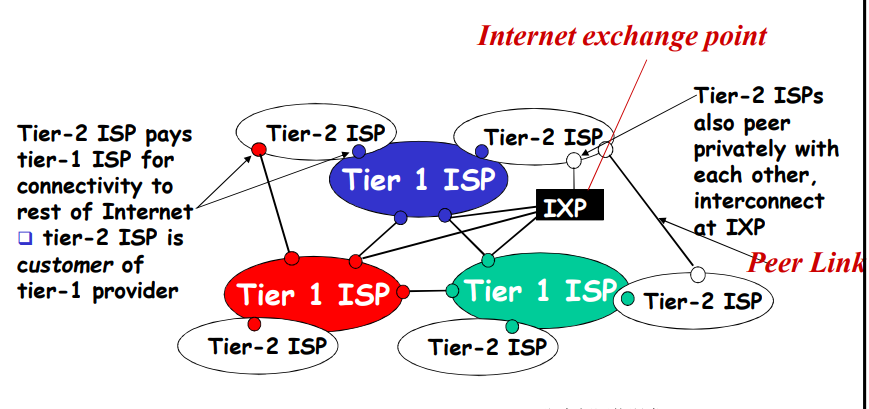
第二层ISP:更小些的(通常是区域性的)ISP
- 与一个或多个第一层ISPs,也可能与其他第二层ISP
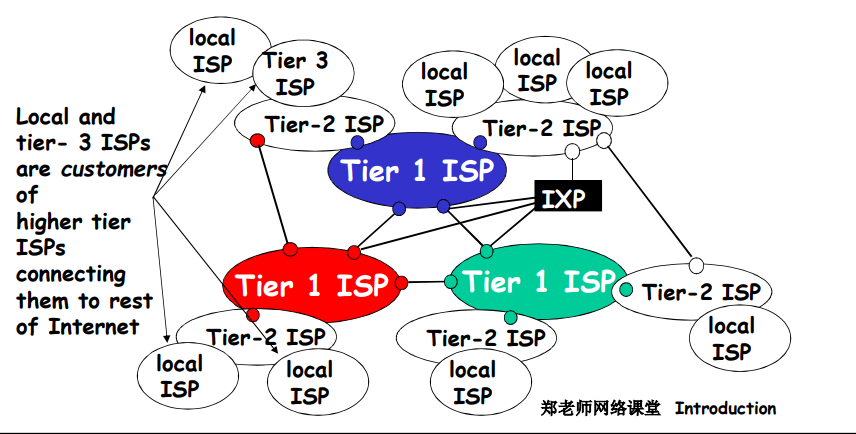
第三层ISP与其他本地ISP
- 接入网(与端系统最近)
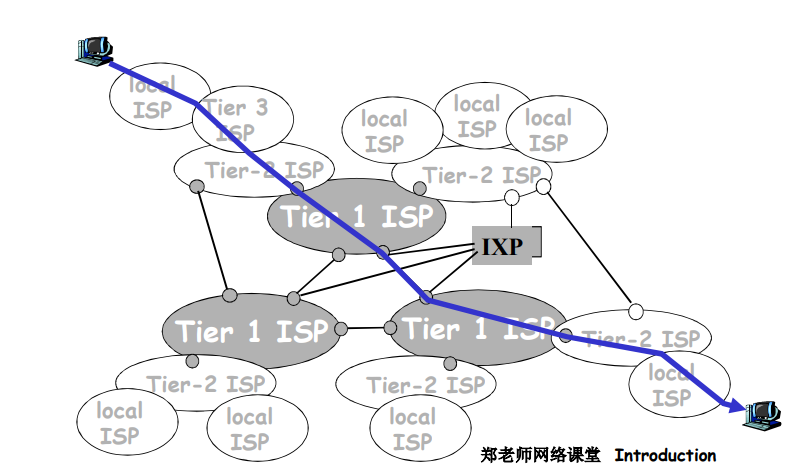
一个分组要经过许多网络!
- 许多内容提供商(如 Google) 可能会部署自己的网络,连接自己在各地的 DC (数据中心),走自己的数据
- 连接若干 local ISP 和各级(包括一层)ISP,更加靠近用户
ISP之间的连接
POP:(Point of Presence)存在点,高层ISP面向客户网络的接入点,涉及费用结算
- 如一个低层ISP接入多个高层ISP,多宿(multi home)
对等接入:2个ISP对等互接,不涉及费用结算
IXP:(因特网交换点)多个对等 ISP 互联互通之外,通常不涉及费用结算
- 对等接入,IXP是一个汇合点,多个ISP能够在这里一起对等
ICP 自己部署专用网络,同时和各级ISP连接
分组交换网中的时延、丢包和吞吐量
可将因特网看成一种基础设施,该基础设施为运行在端系统上的分布式应用提供服务。
在理想情况下,我们希望因特网服务能够在热议两个端系统之间随心所欲地瞬间移动数据而没有任何数据丢失。然而这是一个极高的目标,实践中难以达到。与之相反,计算机网络必定要显示在端系统之间的吞吐量(每秒能够传送的数据量),还会在端系统之间引入时延,而且实际上也会丢失分组。
在路由器缓冲区的分组队列
- 分组到达链路的速率超过了链路输出的能力
- 分组等待排到队头、被传输
四种分组时延
分组从一个主机(host 源)出发,通过一系列的路由器传输,在另一台主机(目的地)中结束它的历程。当分组从一个节点(主机或路由器)沿着这条路径到后继节点(主机或路由器),该分组在沿途的每个节点经受了几种不同类型的时延。这些时延最为重要的是
- 节点处理时延(nodal processing delay )
- 排队时延(queuing delay)
- 传输时延(transmission delay)
- 传播时延(propagation delay)
这些时延总体累加起来是 节点总时延
节点处理时延
- 检查 bit 级差错
- 检查分组首部和决定将分组导向何处
排队时延
- 在输出链路上等待传输的时间
- 依赖于路由器的拥塞程度
通常,到达队列的过程是随机的,即到达并不遵循任何模式,分组之间的时间间隔是随机的。
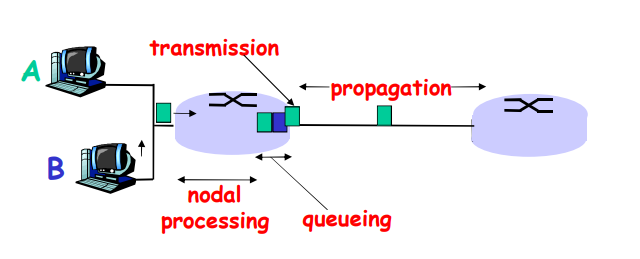
- 传输时延
- R = 链路带宽(bps)
- L = 分组长度(bits)
- 将分组发送到链路上的时间 = L / R
- 存储转发延时
- 传播时延
- d = 物理链路的长度
- s = 在媒体上的传播速度(~2x10^8 m/sec)
- 传播延时 = d / s
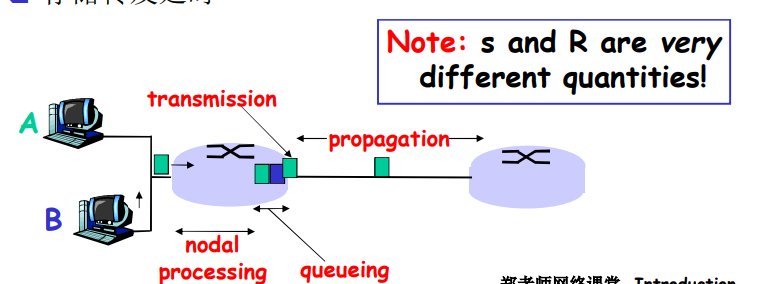
传输时延和传播时延
- 传输时延是路由器推出分组所需要的时间,它是分组长度和链路传输速率的函数,而与两台路由器之间的距离无关。
- 传播时延是一个bit从一台路由器传播到另一台路由器所需要的时间,它是两台路由器之间距离的函数,与分组长度或链路传输速率无关。
传输时延和传播时延是计算机网络中的两个重要概念,它们是评估网络性能的重要指标之一。
传输时延是指数据从发送端到接收端所需的时间。传输时延由数据包的大小和网络带宽决定,其计算公式为传输时延=数据包大小 ÷ 带宽。
传播时延是指数据从发送端到接收端所需的时间,主要由信号在传输介质中传播所需的时间决定。传播时延由传输介质的长度和传播速度决定,其计算公式为传播时延=传输介质长度 ÷ 传播速度。
在实际应用中,传输时延和传播时延都会影响网络性能。传输时延越小,网络传输速度越快,用户体验越好。传播时延越小,网络响应速度越快,用户体验也越好。因此,网络管理员需要在设计和优化网络时,尽可能减小传输时延和传播时延,以提高网络性能和用户体验。
除了传输时延和传播时延,网络还受到了其他因素的影响,例如网络拥塞、路由器和交换机的性能等。网络管理员需要全面地考虑这些因素,以保证网络的高性能和稳定性。
总之,传输时延和传播时延是计算机网络中的两个重要概念,它们是评估网络性能的重要指标之一。网络管理员需要全面考虑网络的各种因素,以优化网络性能和提高用户体验。
时延的类型
作为源和目的地之间的端到端路由的一部分,一个分组从上游节点通过路由器 A 向路由器B 发送。A 具有 通往 B 的出链路。该链路 前面有一个 队列 (也称缓存)。当 分组从上游节点到达路由器 A 时,路由器 A 检查该分组的首部以决定它的适当 出链路,并将该分组导向该链路。
在此例子中,对该分组的出链路是通向路由器 B 的那条链路。 仅当 在该链路没有其他分组正在传输并且没有其他分组排队在该队列之前时,才能在该链路上传输该分组
如果 该链路当前正繁忙或有其他分组已经在该链路上排队,则 新到达的分组将加入排队
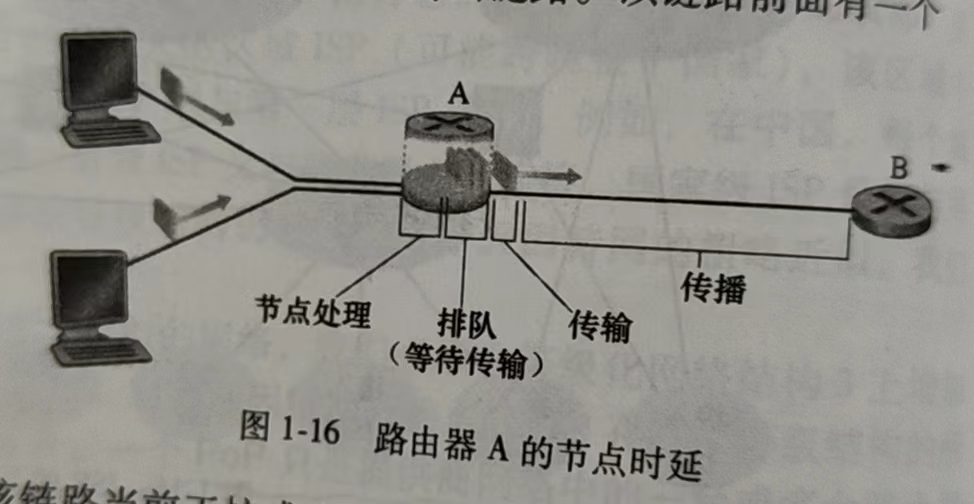
排队延时
R = 链路带宽(bps)
L = 分组长度(bits)
a = 分组到达队列的平均速率
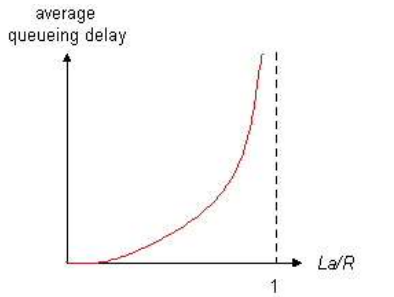
流量强度 = La / R
La / R ~ 0 :平均排队延时很小
La / R ->1 :延时变得很大
La / R > 1 :比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋向无穷大!
设计系统时流量强度不能大于1
Internet的延时和路由
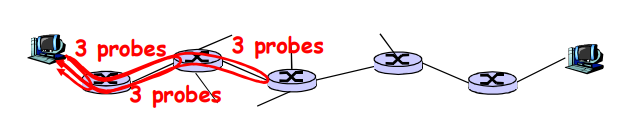
Traceroute 诊断程序:提供从源端,经过路由器,到目的的延时测量
- For all i:
- 沿着目的的路径,向每个路由器发送3个探测分组
- 路由器 i 将向发送方返回一个分组
- 发送方对发送和回复之间间隔计时
traceroute是一种用于确定数据包在互联网上的路径的网络诊断工具。它通过向目标主机发送数据包,并记录经过的路由器的IP地址,从而确定数据包在互联网上的路径。
在使用traceroute工具时,用户需要指定目标主机的IP地址或域名。traceroute会向目标主机发送一系列数据包,并记录每个数据包通过的路由器的IP地址和响应时间。通过这些信息,用户可以了解数据包在互联网上的路径,以及每个路由器的响应时间。
在使用traceroute工具时,需要注意以下几点:
需要有足够的权限:在某些操作系统中,使用traceroute需要有足够的权限,例如管理员权限。
数据包丢失和延迟:因为互联网上的路由器和服务器数量众多,数据包在传输过程中可能会出现丢失或延迟的情况。因此,在使用traceroute时,用户需要考虑这些因素。
防火墙和安全设置:某些防火墙和安全设置可能会阻止traceroute的操作,因此在使用traceroute时,需要确保网络设置合适并且没有阻止traceroute的操作。
在实际应用中,traceroute工具通常用于网络故障排除和优化。例如,当用户遇到互联网连接问题时,可以使用traceroute工具来确定连接问题的具体原因,以便更好地解决问题。此外,traceroute工具还可以帮助网络管理员优化网络路由,提高网络响应速度和性能。
总之,traceroute是一种用于确定数据包在互联网上的路径的网络诊断工具。它通过向目标主机发送数据包,并记录经过的路由器的IP地址,从而确定数据包在互联网上的路径。
丢包
在现实中,一条链路前的队列只有有限的容量,尽管排队容量极大地依赖于路由器设计和成本。因为该排队容量是有限的,随着流量强度接近1,排队时延并不真正趋向无穷大。相反,到达的分组将发现一个满队列。由于没有地方存储这个分组,路由器将丢弃该分组,即丢包。
上述丢包现象看起来是一个分组已经传输到网络核心,但它绝不会从网络发送到目的地。分组丢失的比例随着流量强度增加而增加。
因此,一个节点的性能常常不仅根据时延来度量,而且根据丢包的概率来度量。
- 链路的队列缓冲区容量有限
- 当分组到达一个满的队列时,该分组将会丢失
- 丢失的分组可能会被前一个节点或源端系统重传,或者根本不重传
吞吐量
在源端和目标端之间传输的速率(数据量/单位时间)
- 瞬时吞吐量:在一个时间点的速率
- 平均吞吐量:在一个长时间内平均值
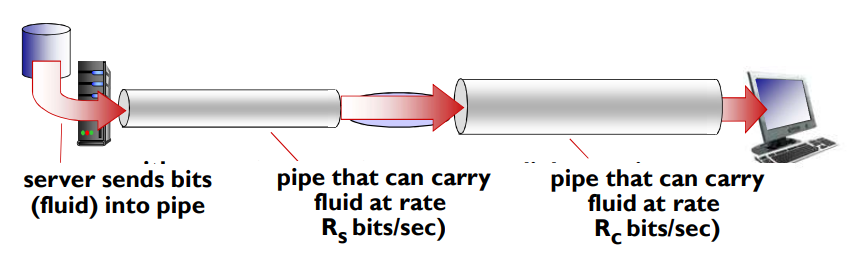
吞吐量取决于数据流过的链路的传输速率。我们看到当没有其他干扰流量时,其吞吐量能够近似为沿着源和目的地之间路径的最小传输速率。
吞吐量不仅取决于沿着路径的传输速率,而是取决于干扰流量。特别是,如果许多其他的数据流也通过这条链路流动,一条具有高传输速率的链路仍然可能成为文件传输的瓶颈链路。
吞吐量是计算机网络中的一个重要概念,它指的是在单位时间内通过网络传输的数据量。吞吐量是评估网络性能的一个重要指标之一,通常用于评估网络的数据传输速度。
在计算机网络中,吞吐量可以通过不同的方式来衡量。例如,可以通过数据包数量、数据字节数量、传输速率等方式来衡量。通常,吞吐量越大,表示网络传输速度越快,数据传输效率越高。
吞吐量受到多种因素的影响,例如网络带宽、传输介质、网络拥塞等。网络管理员需要全面考虑这些因素,以优化网络性能和提高吞吐量。
在实际应用中,吞吐量通常用于评估网络的性能和优化网络的性能。例如,在设计和优化网络时,网络管理员可以通过增加带宽、采用更快的传输介质、优化路由等方式,来提高网络的吞吐量。此外,在进行网络压力测试时,也会使用吞吐量来评估网络的性能。
总之,吞吐量是计算机网络中的一个重要概念,它指的是在单位时间内通过网络传输的数据量。吞吐量是评估网络性能的一个重要指标之一,通常用于评估网络的数据传输速度。
协议层次及其服务模型
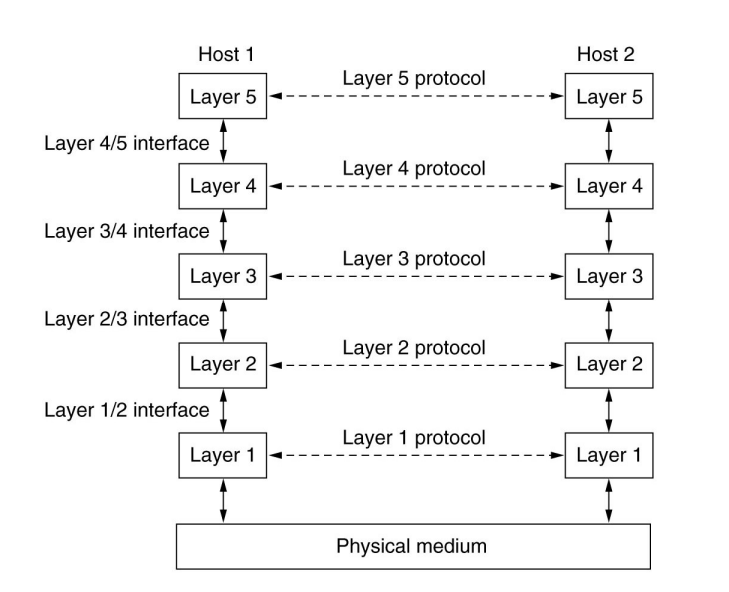
协议层次
网络是一个复杂的系统
网络功能繁杂:数字信号的物理信号承载、点到点、路由、rdt、进程区分、应用等
现实来看,网络的许多构成元素和设备:
- 主机
- 路由器
- 各种媒体的链路
- 应用
- 协议
- 硬件,软件
层次化方式实现复杂网络功能:
- 将网络复杂的功能分成功能明确的层次,每一层实现其中一个或一组功能,功能中有其上层可以使用的功能:服务
- 本层协议实体相互交互执行本层的协议动作,目的是实现本层功能,通过接口为上层提供更好的服务
- 在实现本层协议的时候,直接利用了下层所提供的服务
- 本层的服务:借助下层服务实现的本层协议实体之间交互带来的新功能(上层可以利用的) + 更下层所提供的服务
- 只要该层对其上面的层提供相同的服务,并且使用来自下面的层的相同服务,当某层的实现变化时,该系统的剩余部分就可以保持不变。
对于大而复杂且需要不断更新的系统,改变服务的实现而不影响该系统其他组件是分层的一个重要优点。
潜在缺点:
- 一层可能冗余较低层的功能
- 例如:许多协议栈在基于每段链路和基于端到端两种情况下,都提供了差错恢复。
- 某层的功能可能需要仅在其他某层才出现的信息(如时间戳值),这违反了层次分离的目标。
协议栈:各层的所有协议被称为协议栈。
服务
服务和服务访问点
服务(Service):低层向上层实体提供它们之间的通信的能力
- 服务用户(service user)
- 服务提供者(service provider)
原语(primitive):上层使用下层服务的形式,高层使用低层提供的服务,以及低层向高层提供服务导师通过服务访问原语来进行交互 —– 形式
服务访问点 SAP(Services Access Point):上层使用下层提供的服务通过层间的接口—地点;
- 例子:邮箱
- 地址(address):下层的一个实体支撑着上层的多个实体,SAP 有标志不同上层实体的作用
- 可以有不同的实现,队列
- 例子:传输层的SAP:端口(port)
服务的类型
面相连接的服务-方式
- 面向连接的服务(Connection-oriented Service)
- 连接(Connection):两个通信实体为进行通信建立的一种结合
- 面向连接的服务通信的过程:建立连接,通信,拆除连接
- 面相连接的服务的例子:网络层的连接被称为虚电路
- 适用范围:对于大的数据块要传输;不适合小的零星报文
- 特点:保序
- 服务类型:
- 可靠的信息流 传送页面(可靠的获得,通过接收方的确认)
- 可靠的字节流 远程登录
- 不可靠的连接 数字化声音
面向无连接的服务
- 无连接的服务(Connectionless Service)
- 无连接服务
- 两个对等层实体在通信前不需要建立一个连接,不预留资源;不需要通信双方都是活跃(eg: 寄信)
- 特点
- 不可靠
- 可能重复
- 可能失序
- IP 分组,数据包
- 使用范围
- 适合 传送零星数据
- 服务类型
- 不可靠的数据报 电子方式的函件
- 有确认的数据报 挂号信
- 请求回答 信息查询
- 无连接服务
虚电路是计算机网络中的一个概念,它是一种面向连接的通信方式,与无连接通信方式相对应。虚电路在数据传输之前需要建立连接,传输完成后需要释放连接。
虚电路通常分为两个阶段:建立阶段和数据传输阶段。在建立阶段,通信双方需要通过一系列握手操作来建立虚电路连接,并分配一些资源,例如缓存空间、带宽等。在数据传输阶段,数据包沿着已建立的虚电路传输,数据传输完成后需要释放虚电路连接,释放之后分配的资源也会被释放。
虚电路有以下优点:
提高网络传输效率:虚电路在数据传输之前需要建立连接,建立连接时可以分配资源,这样可以提高网络传输效率。
可靠性较高:虚电路在数据传输之前需要建立连接,通信双方可以进行一些检查和配置,从而提高通信的可靠性。
提供服务质量保证:虚电路可以为数据传输提供一定的服务质量保证,例如带宽保障、延迟保证等。
支持流量控制和拥塞控制:虚电路可以支持流量控制和拥塞控制,从而避免数据传输过程中出现拥塞和数据丢失等问题。
虚电路也有一些缺点。例如,建立虚电路需要一定的开销,会增加网络传输的延迟。同时,虚电路的资源分配也会对网络的利用率产生一定的影响。
总之,虚电路是计算机网络中的一种通信方式,它是一种面向连接的通信方式,与无连接通信方式相对应。虚电路在数据传输之前需要建立连接,传输完成后需要释放连接。
服务和协议
服务和协议的区别
- 服务(Service):低层实体向上层实体提供它们之间通信的能力,是通过原语(primitive)来操作的,垂直
- 协议(protocol):对等层实体(peer entity)之间在相互通信的过程中,需要遵循的规则的集合,水平
服务与协议的联系
- 本层协议的实现要靠下层提供的服务来实现
- 本层实体通过协议为上层提供更高级的服务
数据单元(DU)
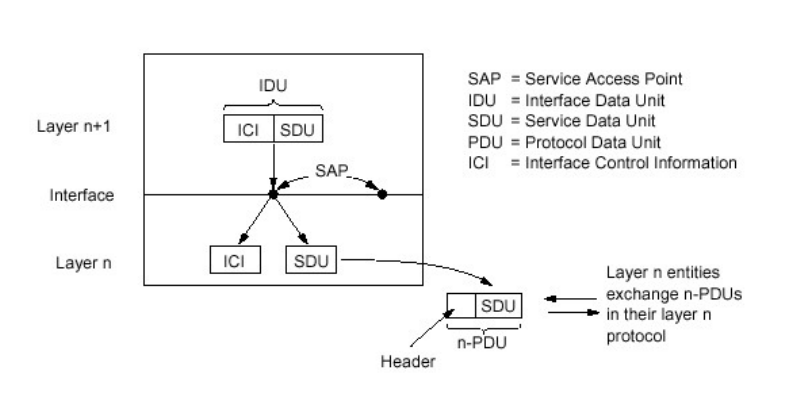
分层处理和实现复杂系统的好处
对于复杂的系统
概念化:结构清晰,便于表示网络组件,以及描述其相互关系
结构化:模块化更易于维护和系统升级
- 改变某一层服务的实现不影响系统中的其他层次
- 对于其他层次而言是透明的
- 如改变登机程序并不影响系统的其他部分
- 改变2个秘书使用的通信方式不影响2个翻译的工作
- 改变2个翻译使用的语言也不影响上下2个层次的工作
Internet 协议栈
应用层:网络应用
应用层是网络应用程序及它们的应用层协议存留的地方。
- 为人类用户或者其他应用进程提供网络应用服务
- FTP(文件传输协议,端到端)、SMTP(简单邮件传输协议)、HTTP(超文本传输协议)、DNS(域名系统)
传输层:主机之间的数据传输
因特网的运输层在应用程序端点之间传送应用层报文
- 在网络层提供的端到端通信基础上,细分为进程到进程,将不可靠的通信变成可靠的通信
- TCP、UDP
网络层:为数据报从源目的选择路由
因特网的网络层负责将称为数据报的网络层分组从一台主机移动到另一台主机
- 主机主机之间的通信,端到端通信,不可靠
- IP,路由协议
- 该协议定义了在数据报中的各个字段以及端系统和路由器如何作用于这些字段。
- IP只有一个,所有具有网络层的因特网组件必须运行IP。
链路层:相邻网络节点间的数据传输
因特网的网络层通过和源和目的地之间的一系列路由器路由数据报,网络层将数据报下传给链路层,链路层沿着路径将数据报传递给下一个节点。在下一个节点,链路层将数据报上传给网络层。
- 2个相邻2点的通信,点到点通信,可靠或不可靠
- 点对点协议(PPP:用于在两个点之间建立可靠的数据传输连接),802.11(WiFi),Ethernet
物理层:在线路上传送bit
链路层的任务是将整个帧从一个网络元素一到邻近的网络元素,而物理层的任务是将该帧中的一个个比特从一个节点移动到下一个节点
ISO/OSI 参考模型

表示层:允许应用解释传输的数据,e.g. ,加密,压缩,机器相关的表示转换
会话层:数据交换的同步,检查点,恢复
互联网协议栈没有这两层!
- 这些服务,如果需要的话,必须被应用实现
封装和解封装
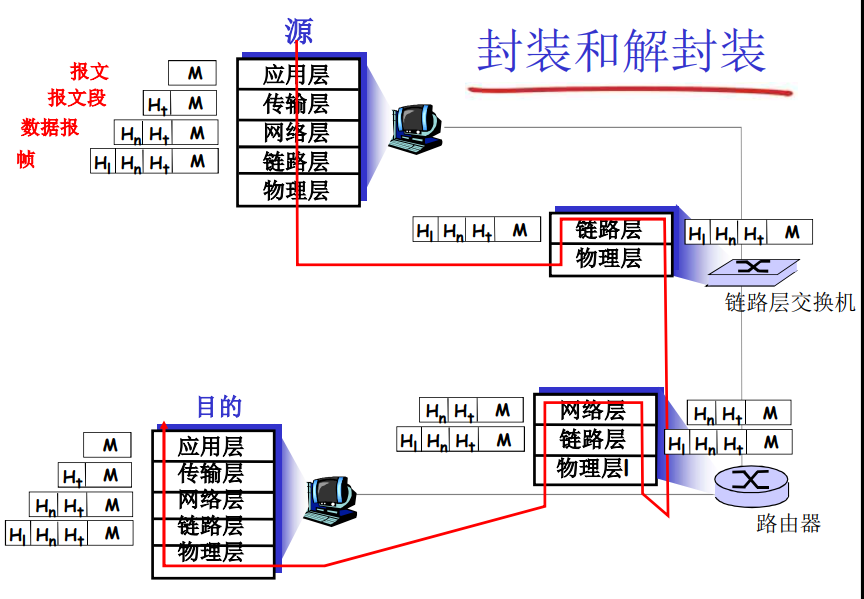
计算机网络协议层次的封装是指在数据传输过程中,将数据按照协议层次进行封装和解封装的过程。计算机网络通常按照OSI参考模型或TCP/IP协议族进行分层,每个层次都有自己的协议和功能。
在数据传输过程中,每个层次都会添加自己的协议头和协议尾,从而形成一个完整的数据包。发送方在发送数据时,会按照协议层次将数据进行封装,将上层数据添加到下层协议头之后,形成一个完整的数据包。接收方在接收数据时,会按照协议层次将数据进行解封装,将下层协议头和尾去掉,提取出上层数据。
计算机网络协议层次的封装具有以下优点:
提高数据传输的可靠性:通过分层的方式,每个层次都只负责自己的功能,从而减少了不必要的冗余信息,提高了数据传输的可靠性。
提高网络的灵活性和可扩展性:通过分层的方式,网络可以根据不同的需求和应用场景进行定制,提高了网络的灵活性和可扩展性。
便于实现和维护:通过分层的方式,每个层次都有自己的协议和功能,便于实现和维护。
在实际应用中,计算机网络协议层次的封装通常用于数据传输和通信等方面。例如,在TCP/IP协议族中,每个层次都有自己的协议和功能,例如HTTP、FTP、SMTP等应用层协议,TCP和UDP传输层协议,IP网络层协议和以太网物理层协议等。
需要注意的是,计算机网络协议层次的封装也存在一些问题,例如在分层的过程中可能会增加延迟和开销,网络安全性和隐私性也需要得到保护。为了解决这些问题,用户可以使用一些安全机制,例如加密、数字签名等,来保护数据的安全性和隐私性。
总之,计算机网络协议层次的封装是指将数据按照协议层次进行封装和解封装的过程。这种封装方式具有提高数据传输可靠性、提高网络的灵活性和可扩展性、便于实现和维护等优点。
各层次的协议数据单元
应用层:报文(message)
- 报文:应用层协议分布在多个端系统上,而一个端系统中的应用程序使用协议域另一个端系统中的应用程序交换信息分组。我们把这种位于应用层的信息分组称为报文。
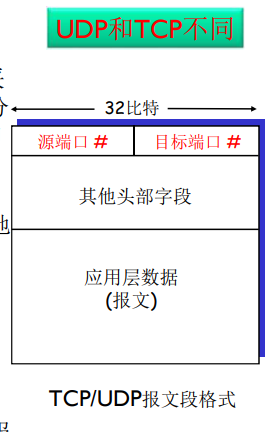
传输层:报文段(segment):TCP段,UDP数据报
网络层:分组(packet)(如果无连接方式:数据报 datagram)
数据链路层:帧(frame)
物理层:位(bit)
计算机网络按照OSI七层模型分为七层,每一层都有自己的协议和协议数据单元。下面是各层次的协议数据单元:
物理层:物理层主要负责传输比特流,常见的协议有Ethernet、SONET和DSL等,它们的协议数据单元是比特(bit)。
数据链路层:数据链路层主要负责将比特流组装成帧,并进行错误检测和纠正。常见的协议有以太网、PPP和HDLC等,它们的协议数据单元是帧(frame)。
网络层:网络层主要负责进行逻辑寻址和路由选择,将数据包从源主机传输到目的主机。常见的协议有IP、ICMP和ARP等,它们的协议数据单元是数据包(packet)。
传输层:传输层主要负责提供端到端的可靠数据传输服务,常见的协议有TCP和UDP等,它们的协议数据单元是报文段(segment)和用户数据报(datagram)。
会话层:会话层主要负责建立和管理应用程序之间的会话,常见的协议有RPC和NetBIOS等,它们的协议数据单元是会话数据单元(SDU)。
表示层:表示层主要负责数据的格式转换、加密和解密等处理,常见的协议有JPEG和MPEG等,它们的协议数据单元是表示数据单元(PDU)。
应用层:应用层主要负责提供各种不同的应用程序,常见的协议有HTTP、FTP和SMTP等,它们的协议数据单元是应用数据单元(ADU)。
总之,不同层次的协议都有自己的协议数据单元,它们按照一定的协议规范进行交互和传输,从而实现了计算机网络的功能和应用。
小结
- 组成角度看 什么是互联网
- 边缘 : 端系统(包括应用) + 接入网
- 核心 : 网络交换设备 + 通信链路
- 协议 : 对等层实体通信过程中遵守的规则的集合
- 语法,语义,时序
- 为了实现复杂的网络功能,采用分层方式设计、实现和调试
- 应用层、传输层、网络层、数据链路层、物理层
- 协议数据单位
- 报文、报文段、分组、帧、位
- 从 服务角度 看互联网
- 通信服务基础设施
- 提供的通信服务: 面向连接 无连接
- 应用
- 通信服务基础设施
- 应用之间的交互
- C/S 模式
- P2P 模式
- 数据交换
- 分组数据交换
- 线路交换
- 比较 线路交换和 分组交换
- 分组交换的 2 中方式
- 虚电路
- 数据报
- 接入网和物理媒介
- 接入网技术
- 住宅:ADSL,拨号,cable modem
- 单位:以太网
- 无线接入方式
- 物理媒介
- 光纤,同轴电缆,以太网,双绞线
- 接入网技术
- ISP 层次结构
- 分组交换网络中 延迟和丢失是如何发生的
- 延迟的组成:
- 处理
- 传输
- 传播
- 排队
- 延迟的组成:
- 网络的分层体系结构
- 分层体系结构
- 服务
- 协议数据单元
- 封装与解封装
- 历史
应用层
在本章中,我们学习有关网络应用的原理和实现方面的知识。我们从定义关键的应用层概念开始,其中包括应用程序所需要的网络服务、客户和服务器、进程、运输层接口。
应用层是我们学习协议非常好的起点,它最为我们熟悉。
目标
- 网络应用的原理:网络应用协议的概念和实现方面
- 传输层的服务模型
- 客户-服务器模式
- 对等模式(peer-to-peer)
- 内容分发网络
- 网络应用的实例:互联网流行的应用层协议
- HTTP
- FTP
- SMTP/POP3/IMAP
- DNS
- 编程:网络应用程序
- Socket API
创建一个新的网络应用
编程
- 在不同的端系统上运行
- 通过网络基础设施提供的服务,应用进程彼此通信
- 如 WEB
- web 服务器软件与浏览器软件通信
网络核心中没有应用层软件
- 网络核心没有应用层功能
- 网络应用只在端系统上存在,快速网络应用开发和部署
应用层协议原理
网络应用的体系结构
可能的应用架构:
- 客户-服务器模式(C/S:client/server)
- 对等模式(P2P:Peer To Peer)
- 混合体:客户-服务器和对等体系结构
客户-服务器(C/S)体系结构
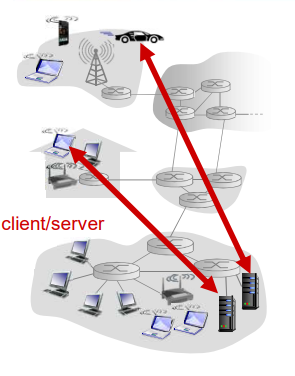
在 客户-服务器体系结构 中,有一个总是打开的主机,称为服务器,它服务于来自许多其他称为客户的主机请求。
服务器:
- 一直运行
- 固定的IP地址和周知的端口号(约定)
- 扩展性:服务器场
- 数据中心进行扩展
- 扩展性差
客户端:
- 主动与服务器通信
- 与互联网有间歇性的连接
- 可能是动态IP地址
- 不直接与其它客户端通信
对等体(P2P)体系结构
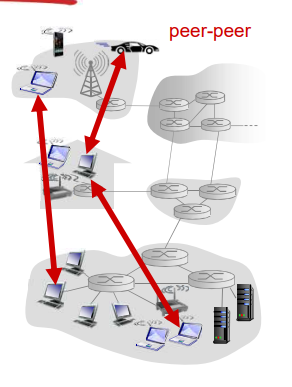
- 几乎没有一直运行的服务器
- 任意端系统之间可以进行通信
- 每一个节点既是客户端又是服务器
- 自扩展性:新peer节点带来新的服务能力,当然也带来新的服务请求
- 参与的主机间歇性连接且可以改变IP地址
- 难以管理
- 例子:Gnutella,迅雷
P2P体系结构是指一种点对点的计算机网络架构,它将节点连接在一起,形成一个自组织的网络。P2P网络中的每个节点都可以充当客户端和服务器,节点之间可以直接交换信息和资源,而不需要通过中心化的服务器进行交互。
P2P体系结构通常分为两种类型:纯P2P和混合P2P。纯P2P体系结构中,每个节点都具有相同的功能和贡献,每个节点都可以直接与其他节点进行通信和交换资源。混合P2P体系结构中,除了节点之间的直接交互外,还包括一些中心化的服务器,用于提供一些服务,例如索引、查找等。
P2P体系结构具有以下优点:
分布式:P2P体系结构不需要中心化的服务器,节点之间可以直接交互和通信,从而提高了网络的灵活性和可扩展性。
自组织:P2P体系结构可以根据节点的加入和退出,自动组织和调整网络拓扑结构。
可靠性:P2P体系结构具有较高的容错性和可靠性,节点之间可以互相备份和恢复数据,从而减少了数据丢失的风险。
需要注意的是,P2P体系结构也存在一些问题,例如版权侵权、恶意软件等。为了保护P2P网络的安全性,用户需要注意资源的合法性和安全性,不要下载和分享非法或者有害的资源。
在实际应用中,P2P体系结构通常用于文件共享、流媒体传输和在线游戏等方面。例如,用户可以使用P2P网络共享文件和音乐,从而实现快速的文件传输和资源共享。另外,一些流媒体服务也使用P2P网络来传输视频和音频流,以提高传输效率和减轻服务器负载。此外,P2P网络还可以用于在线游戏中,实现多人游戏的联机功能,从而提高游戏的互动性和趣味性。
总之,P2P体系结构是一种点对点的计算机网络架构,它将节点连接在一起,形成一个自组织的网络。P2P体系结构具有分布式、自组织、可靠性等优点,在文件共享、流媒体传输和在线游戏等方面有着广泛的应用。
C/S和P2P体系结构的混合体
Napster
- 文件搜索:集中
- 主机在中心服务器上注册其资源
- 主机向中心服务器查询资源位置
- 文件传输:P2P
- 任意peer节点之间
即时通信
- 在线检测:集中
- 当用户上线时,向中心服务器注册其IP地址
- 用户与中心服务器联系,以找到其在线好友的位置
- 两个用户之间聊天:P2P
进程通信
进程:在主机上运行的应用程序
- 客户端进程:发起通信的进程
- 服务器进程:等待连接的进程
在同一个主机内,使用进程间通信机制通信(操作系统定义)
不同主机,通过交换报文(Message)来通信
- 使用OS提供的通信服务
- 按照应用协议交换报文
- 借助传输层提供的服务
注意:P2P架构的应用也有客户端进程和服务器进程之分
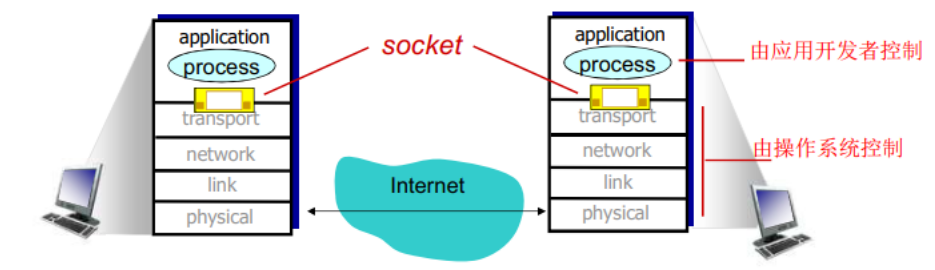
多数应用程序由通信进程对组成,每对中的两个进程互相发送报文。从一个进程向另一个进程发送的报文必须通过下面的网络。进程通过一个称为套接字(socket)的软件接口向网络发送报文和从网络接收报文。
套接字是同一台主机内应用层与运输层之间的接口。应用程序开发者可以控制套接字在应用层端的一切,但是对该套接字的运输层端几乎没有控制权。
应用程序开发者对于运输层的控制仅限于:
- 选择运输层协议
- 也许能设定几个运输层参数,如最大缓存和最大报文段长度等
分布式进程通信需要解决的问题

- 问题1 : 进程标示和寻址问题(服务用户)
- 问题2 : 传输层 - 应用层提供服务是如何(服务)
- 位置: 层间页面 的 SAP(TCP/IP :Socket)
- 形式:应用程序接口 API (TCP/IP:socket API)
- 问题3:如何使用传输层提供的服务,实现应用进程之间的报文交换,实现应用(用户使用服务)
- 定义应用层协议:报文格式,解释,时序等
- 编制程序,使用 OS 提供的 API,调用网络基础设施提供通信服务传报文,实现应用时序等
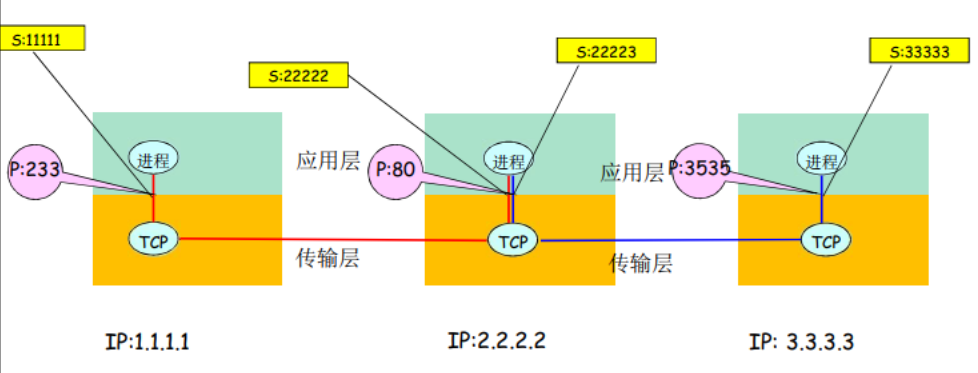
问题1:对进程进行编址(addressing)
进程为了接收报文,必须有一个标识,即:SAP(发送也需要标识)
- 主机:唯一的 32位 IP地址
- 仅仅有IP地址不能够唯一标识一个进程:在一台端系统上有很多应用进程在运行
- 所采用的传输层协议:TCP or UDP
- 端口号(Port Numbers)
一些知名端口号的例子:
- HTTP: TCP 80 Mail: TCP25 ftp: TCP 2
一个进程:用IP + port标示 端节点
本质上,一对主机进程之间的通信由2个端节点构成
问题2:传输层提供的服务-需要穿过层间的信息

- 层间接口必须要携带的信息
- 要传输的报文(对于本层来说:SDU)
- 谁传的:对方的应用进程的标示:IP + TCP(UDP)端口
- 传给谁:对方的应用进程的标示:对方的 IP+TCP(UDP)端口号
- 传输层实体(tcp或者udp实体),根据这些信息进行TCP报文段(UDP数据报)的封装
- 源端口号,目标端口号,数据等
- 将IP地址往下交IP实体,用于封装IP数据报:源IP,目标IP
传输层实体是指计算机网络中传输层的数据传输实体,通常包括TCP(Transmission Control Protocol)实体和UDP(User Datagram Protocol)实体。
TCP是一种面向连接的协议,它提供可靠的数据传输和流量控制,保证了数据的可靠性和完整性。TCP实体在数据传输之前需要建立连接,通过三次握手协议来确保连接的可靠性。在数据传输过程中,TCP实体还可以进行数据分段和重传,从而保证数据的可靠性和流量控制。
UDP是一种无连接的协议,它提供了快速的数据传输和简单的错误检测,但不保证数据的可靠性和完整性。UDP实体在数据传输之前不需要建立连接,数据也不需要进行分段和重传。UDP实体通常用于实时性要求比较高的应用,例如网络游戏、语音通信等。
需要注意的是,TCP实体和UDP实体的选择取决于不同的应用场景和需求。如果数据传输的可靠性和完整性比较重要,通常选择TCP实体;如果数据传输的实时性比较重要,通常选择UDP实体。
总之,传输层实体是指计算机网络中传输层的数据传输实体,通常包括TCP实体和UDP实体。TCP实体提供可靠的数据传输和流量控制,而UDP实体提供快速的数据传输和简单的错误检测。实际使用时需要根据不同的应用场景和需求来选择合适的传输层实体。
问题2:传输层提供的服务-层间信息的代表
如果Socket API每次传输报文,都携带如此多的信息,太繁琐易错,不便于管理
用个代号标示通信的双方或者单方:socket
就像OS打开文件返回的句柄一样
- 对句柄的操作,就是对文件的操作
TCP socket:
- TCP服务,两个进程之间的通信需要之前要建立连接
- 两个进程通信会持续一段时间,通信关系稳定
- 可以用一个整数表示两个应用实体之间的通信关系,本地标示
- 穿过层间接口的信息量最小
- TCP socket:源IP,源端口,目标IP,目标IP,目标端口
- TCP服务,两个进程之间的通信需要之前要建立连接
TCP之上的套接字(socket)
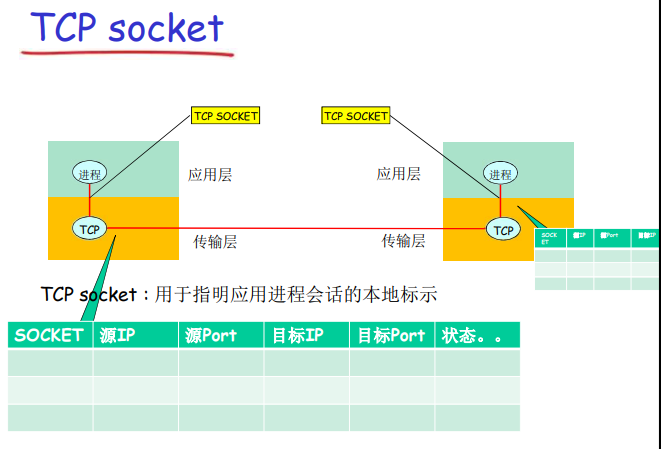
对于使用面向连接服务(TCP)的应用而言,套接字是4元组的一个具有本地意义的标示
- 4元组:源IP,源port,目标IP,目标port
- 唯一的指定一个会话(2个进程之间的会话关系)
- 应用使用这个标示,与远程的应用进程通信
- 不必再每一个报文的发送都要指定这 4元组
- 就像使用操作系统打开一个文件,OS返回一个文件句柄医用,以后使用这个文件句柄,而不是使用这个文件的目录名、文件名
- 简单,便于管理
问题2:传输层提供的服务-层间信息代码
UDP socket:
UDP服务,两个进程之间的通信需要之前无需建立连接
每个报文都是独立传输的
前后报文可能给不同的分布式进程
因此,只能用一个整数表示本应用的实体的标示
- 因为这个报文可能传给另外一个分布式进程
穿过层间接口的信息大小最小
UDP socket:本IP,本端口
但是传输 报文 时:必须要提供对方IP,port
- 接收报文时:传输层需要上传对方的IP,port
UDP之上的套接字(socket)
- 对于使用无连接服务(UDP)的应用而言,套接字是2元组的一个具有本地意义的标示
- 二元组:IP,port(源端指定)
- UDP套接字指定了应用所在的一个端节点(end point)
- 在发送数据报时,采用创建好的本地套接字(标示ID),就不必在发送每个报文中指明自己所采用的 ip 和 port
- 但是在发送报文时,必须要指定对方的 IP 和 UDP port(另外一个 端节点)
套接字(socket)
- 进程向 套接字 发送报文 或从 套接字接收报文
- 套接字 < - > 门户
- 发送 进程将报文推出门户,发送进程依赖于传输层设施在 另外一侧的门将报文交付给接受进程
- 接受进程从门的另外一侧的门户 收到 报文(依赖于传输层设施)
问题3:如何使用 传输层提供的服务实现应用
- 定义应用层协议:报文格式,解释,时序等
- 编制程序,通过API 调用 网络基础设施提供的通信服务传报文,解析报文,实现应用时序等
应用层协议
定义了:运行在不同端系统上的应用进程如何相互交换报文
- 交换的报文类型:请求和应答报文
- 各种报文类型的语法:报文中的各个字段及其描述
- 字段的语义:即字段取值的含义
- 进程何时、如何发送报文即对报文进行响应的规则
应用协议仅仅是应用的一个组成部分
- Web应用:HTTP协议,web客户端,web服务器,HTML
公开协议:
- 由RFC文档定义
- 允许互操作
- 如HTTP、SMTP
专用(私有)协议:
- 协议不公开
- 如:Skype
运输服务
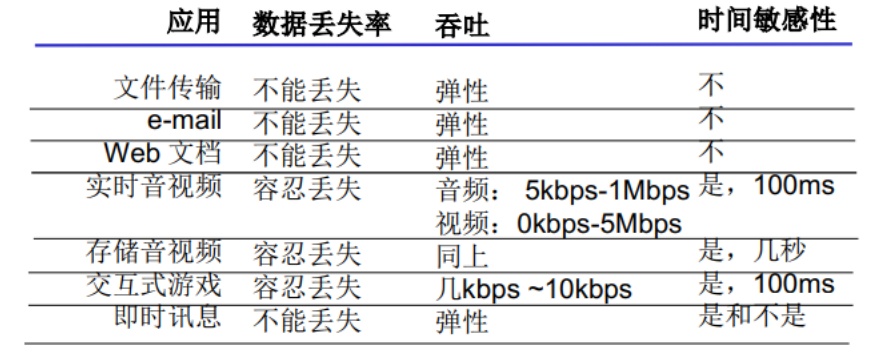
如何描述传输层的服务
数据丢失率
- 有些应用在要求 100% 的可靠数据传输(如 文件)
- 有些应用(如 音频)能容忍一定比例下的数据丢失
运输层协议能够潜在地向应用程序提供的一个重要服务是进程到进程的可靠数据传输。当一个运输协议提供这种服务时,发送进程只要将其数据传递进套接字,就可以完全相信该数据将能无差错地到达接收进程。
吞吐
- 一些应用(如多媒体)必须需要最小限度的 吞吐,从而使得应用能够有效运转
- 一些应用能够充分理由可供使用的吞吐(弹性应用)
运输层协议能够以某种特定的速率提供确保的可用吞吐量,具有吞吐量要求的应用程序被称为带宽敏感的应用。
带宽敏感的应用具有特定的吞吐量要求,而弹性应用能够根据当时可用的带宽或多或少地利用可供使用的吞吐量。(像:电子邮件、文件传输以及Web传送都属于弹性应用。)
延迟
- 一些应用出于 有效性 考虑,对数据传输有严格时间限制
- Internet电话、交互式游戏
- 延迟、延迟差
- 一些应用出于 有效性 考虑,对数据传输有严格时间限制
安全性
- 机密性
- 完整性
- 可认证性(鉴别)
常见应用对传输服务的要求
Internet 传输层提供的服务
TCP和UDP服务
TCP服务
可靠的传输服务
- 通信进程能够依靠TCP,无差错、按适当顺序交付所有发送的数据。
- 当应用程序的一端将字节流传进套接字时,它能够依靠TCP将相同的字节流交付给接收方的套接字,而没有字节的丢失和冗余。
流量控制:发送方不会淹没接收方
拥塞控制:当网络出现拥堵时,能抑制发送方
不能提供的服务:时间保证、最小吞吐量保证和安全
面向连接:要求在客户端进程和服务器进程之间建立连接
在应用层数据报文开始流动之前,TCP让客户和服务器相互交换运输层信息。这个所谓的握手过程提醒客户和服务器,让它们为大量分组的到来做好准备。当应用程序结束报文发送时,必须拆除该连接。
TCP还具有拥塞控制机制,这种服务不一定能为通信进程带来直接好处,但能为因特网带来整体好处。当发送方和接收方之间的网络出现拥塞时,TCP的拥塞控制机制会抑制发送进程(客户或服务器)。TCP拥塞控制也试图限制每个TCP连接,使它们达到公平共享网络带宽的目的。
UDP服务
- 不可靠的数据传输
- 不提供的服务:可靠,流量控制,拥塞控制,带宽保证,建立连接
UDP是一种不提供不必要服务的轻量级运输协议,它仅提供最低限度的服务。UDP是无连接的,因此在两个进程通信前没有握手过程。UDP提供一种不可靠的数据传输服务,不仅如此,到达接收进程的报文也可能是乱序到达的。
UDP不包括拥塞控制机制,所以UDP的发送端可以用它选定的任何速率向其下层(网络层)注入数据,(然而,值得注意的是:实际端到端吞吐量可能小于该速率,这可能是由中间链路的带宽受限或拥塞而造成的。)
UDP存在的必要性
能够区分不同的进程,而 IP 服务不能
- 在 IP 提供的主机到主机 端到端功能的基础上,区分了 主机的应用进程
无需建立连接:省去了建立连接的时间,适合事务性的应用
不做可靠性的工作。例如 检错重发,适合那些对实时性要求比较高而对正确性要求不高的应用
- 因为为了实现可靠性(正确性、保序等),必须付出时间代价(检错重发)
没有了 拥塞控制和流量控制,
应用能够按照设定的速度发送数据
- 而在 tcp 上面的应用,应用发送数据的速度和主机向网络发送的实际速度是不一致的,因为有流量限制和拥塞限制
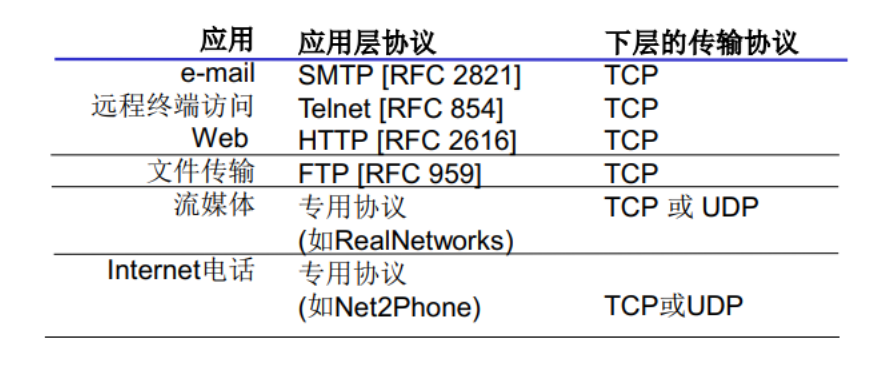
Internet 应用及其应用层协议和传输协议
安全TCP(SSL)
TCP&UDP
- 都没有加密
- 明文通过互联网传输,甚至密码
SSL(安全套接字协议)
- 在TCP上实现,提供加密的TCP连接
- 私密性
- 数据完整性
- 端到端的鉴别
SSL在应用层
- 应采用SSL库,SSL库采用TCP通信
SSL socket api
- 应用通过 API 将明文交给socket,SSL将其加密在互联网上传输
SSL协议(安全套接字协议)在保证网络通信安全方面有以下优点:
机密性:SSL协议可以使用公钥加密和对称加密相结合的方式来保证数据的机密性,防止数据被窃听和窃取。
完整性:SSL协议可以使用数字签名和消息认证码来保证数据的完整性,防止数据被篡改和伪造。
可靠性:SSL协议可以使用证书认证和安全通道来保证数据传输的可靠性,防止数据丢失和损坏。
需要注意的是,SSL协议也存在一些缺点,例如握手过程的延迟、证书认证的复杂性、加密算法的漏洞等。为了提高SSL协议的安全性和可靠性,需要不断更新和升级SSL协议,使用更加安全的加密算法和认证方式。
在实际应用中,SSL协议通常用于网站的安全认证和加密传输等方面。例如,网站可以通过SSL协议来使用HTTPS(Hyper Text Transfer Protocol Secure)协议进行安全加密传输,从而保证用户的个人信息和交易数据的安全性。同时,SSL协议也可以用于电子邮件、即时通讯、远程访问等方面,保护网络通信的安全性。
总之,SSL协议是一种用于保护网络通信安全的加密协议,它可以保证数据的机密性、完整性和可靠性。在实际应用中,SSL协议通常用于网站的安全认证和加密传输等方面,是保护网络通信安全的重要手段。
Web and HTTP
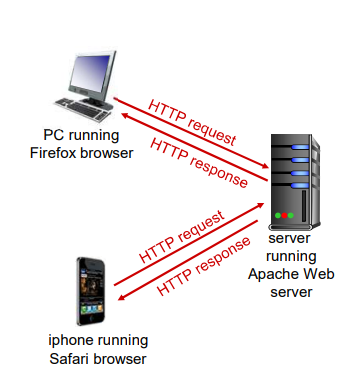
Web 与 HTTP
Web的应用层协议是HTTP,它定义了在浏览器和Web服务器之间传输的报文格式和序列。
Web服务器实现了HTTP的服务器端,它用于存储Web对象,每个对象由URL寻址
Web页:由一些对象组成
对象可以是HTML文件、JPEG图像、Java小程序、声音剪辑文件等
Web页含有一个基本的HTML文件,该基本HTML文件又包含若干对象的引用(链接)
通过URL对每个对象进行引用
- 访问协议,用户名,口令字,端口等
URL格式:

HTTP
HTTP概况
HTTP:超文本传输协议
HTTP是Web的应用层协议
客户/服务器模式
- 客户:请求、接收和显示Web对象的浏览器
- 服务器:对请求进行响应,发送对象的Web服务器
客户程序和服务器程序运行在不同的端系统中,通过交换HTTP报文进行会话。HTTP定义了这些报文的结构以及客户和服务器进行报文交换的方式。即HTTP定义了Web客户向Web服务器请求Web页面的方式,以及服务器向客户传送Web页面的方式。
HTTP 1.0:RFC 1945
HTTP 1.1:RFC 2068
HTTP 2:RFC 7540
使用TCP:
- 客户发起一个与服务器的TCP连接(建立套接字),端口号为80
- 服务器接受客户的TCP连接
- 在浏览器(HTTP客户端)与 Web服务器(HTTP服务器 server)交换HTTP报文(应用层协议报文)
- TCP连接关闭
HTTP是无状态的
- 服务器并不保存和维护关于客户的任何信息
一旦客户向它的套接字接口发送了一个请求报文,该报文就脱离了客户控制并进入TCP的控制,HTTP不用担心数据丢失,也不关注TCP从网络的数据丢失和乱序故障中恢复的细节(那是TCP以及协议栈较低层协议的工作)。
假如某个特定的客户在短短的几秒内两次请求同一个对象,服务器并不会为刚刚为客户提供了该对象就不再做出反应,而是重新发送该对象。
维护状态的协议很复杂!
- 必须维护历史信息(状态)
- 如果服务器/客户端四级,它们的状态信息可能不一致,二者的信息必须是一致的
- 无状态的服务器能够支持更多的客户端
HTTP连接
HTTTP默认使用持续连接
非持久HTTP(采用非持续连接的HTTP)
- 最多只有一个对象在TCP连接上发送
- 下载多个对象需要多个TCP连接
- HTTP/1.0使用非持久连接


非持续连接的HTTP(HTTP/1.0)是一种较早的HTTP协议版本,它采用非持续连接的方式进行通信。在非持续连接的HTTP中,每个请求和响应都需要建立一个新的TCP连接,完成后立即关闭连接,不保留任何状态信息。因此,每个请求和响应都需要消耗额外的时间和资源,影响了系统的性能和可伸缩性。
非持续连接的HTTP协议存在一些问题,例如:
- 每个请求和响应都需要建立一个新的TCP连接,浪费了大量的时间和资源,降低了系统的性能和可伸缩性。
- 每个请求和响应都需要消耗额外的带宽和能源,增加了网络负担和环境成本。
- 非持续连接的HTTP协议无法处理复杂的Web应用程序,如在线交易、社交网络、流媒体等,因为它无法保持状态信息。
持久HTTP(采用持续连接的HTTP)
- 多个对象可以在一个(客户端和服务器之间的)TCP连接上传输
- HTTP/1.1默认使用持久连接
在采用HTTP1.1持续连接的情况下,服务器在发送响应后保持该TCP连接打开。在相同的客户与服务器之间,后续的请求和响应报文能够通过相同的连接进行传送。
如果一条连接经过一定时间间隔(一个可配置的超时间隔)仍未被使用,HTTP服务器就关闭该连接。HTTP的默认模式是使用带流水线的持续连接。
采用持续连接的HTTP(HTTP/1.1)是一种较新的HTTP协议版本,它引入了持久连接的概念,即可以在同一个TCP连接上发送多个请求和响应,避免了重复建立和关闭TCP连接的开销。在持续连接的HTTP中,客户端和服务器之间的TCP连接不会在每个请求和响应之后立即关闭,而是保持连接状态,直到客户端或服务器明确要求关闭连接。
持续连接的HTTP协议解决了非持续连接的HTTP协议存在的一些问题,例如:
减少了每个请求和响应之间建立和关闭TCP连接的开销,提高了系统的性能和可伸缩性。
减少了每个请求和响应消耗的带宽和能源,减轻了网络负担和环境成本。
可以处理复杂的Web应用程序,如在线交易、社交网络、流媒体等,因为它可以保持状态信息,并且可以在同一个TCP连接上发送多个请求和响应。
此外,持续连接的HTTP协议还引入了HTTP管线化的概念,即可以在同一个TCP连接上同时发送多个请求,避免了请求之间的等待时间和网络拥塞。但是,HTTP管线化存在一些问题,例如请求之间的依赖关系和服务器的响应顺序等问题,因此在实际应用中需要谨慎使用。
总之,采用持续连接的HTTP(HTTP/1.1)是一种较新的HTTP协议版本,引入了持久连接的概念,可以在同一个TCP连接上发送多个请求和响应,避免了重复建立和关闭TCP连接的开销,提高了系统的性能和可伸缩性。
HTTP/2:
HTTP/2的主要目标是减小感知时延,其手段是经单一 TCP 连接使请求与响应多路复用,提供请求优先次序和服务器推,并提供HTTP首部字段的有效压缩。HTTP/2不改变HTTP方法、状态码、URL或首部字段,而是改变数据格式化方法以及客户和服务器之间的传输方式。
HTTP/2是一种新的HTTP协议版本,它采用了一些新的技术和机制,以提高Web应用程序的性能和可伸缩性。HTTP/2的主要特点包括:
多路复用:HTTP/2可以在同一个TCP连接上同时发送多个请求和响应,避免了请求之间的等待时间和网络拥塞,提高了系统的性能和可伸缩性。
二进制分帧:HTTP/2将HTTP报文分成二进制格式的帧,可以更快地传输和解析,减少了网络负载和延迟。
头部压缩:HTTP/2使用HPACK算法对HTTP头部进行压缩,可以减少网络负载和延迟,提高了系统的性能和可伸缩性。
服务器推送:HTTP/2支持服务器主动推送资源到客户端缓存,可以提高页面加载速度和用户的体验。
安全性:HTTP/2要求使用TLS加密通信,可以提高通信的安全性和隐私性。
需要注意的是,HTTP/2的实现存在一些问题和挑战,例如对老版本HTTP协议的兼容性、头部压缩算法的安全性、服务器推送的优化等,需要采取一些策略和技术来解决。此外,HTTP/2的性能和效果也与应用程序和网络环境有关,需要对具体情况进行评估和优化。
总之,HTTP/2是一种新的HTTP协议版本,采用了多路复用、二进制分帧、头部压缩、服务器推送等新技术和机制,以提高Web应用程序的性能和可伸缩性。
响应时间模型
往返时间RTT(round-trip time):
一个小的分组从客户端到服务器,在返回到客户端的时间(传输时间忽略)
RTT包括:分组传播时延、分组在中间路由器和交换机上的排队时延、分组处理时延。
响应时间:
- 一个RTT用来发起TCP连接
- 一个RTT用来HTTP请求并等待HTTP响应
共:2RTT + 传输时间
RTT是“往返时延”(Round-Trip Time)的缩写,是网络中的一个重要指标。RTT指的是从发送方发送数据开始,到接收方接收到确认消息的时间差。
RTT的作用是评估网络的性能和可靠性。通过测量RTT可以确定网络的延迟和带宽,从而评估网络的性能和可靠性。在网络通信中,RTT也常用于控制数据传输的速率和流量控制,以及进行拥塞控制和丢包恢复等。
RTT的值取决于多个因素,包括网络拓扑结构、网络负载、传输距离、网络设备等。因此,对于不同的网络应用和场景,需要根据实际情况选择合适的RTT阈值和控制策略,以达到最佳的网络性能和可靠性。
总之,RTT是网络中的一个重要指标,用于评估网络的性能和可靠性。它可以用于控制数据传输的速率和流量控制,以及进行拥塞控制和丢包恢复等。
持久HTTP
非持久HTTP的缺点:
- 每个对象要2个RTT(往返时延)
- 操作系统必须为每个TCP连接分配资源
- 但浏览器通常打开并行TCP连接,以获取引用对象
持久HTTP
- 服务器在发送响应后,仍保持TCP连接
- 在相同客户端和服务器之间的后续请求和响应报文通过相同的连接进行传送
- 客户端在遇到一个引用对象的时候,就可以尽快发送该对象的请求
非流水方式的持久HTTP:
- 客户端只能在收到前一个响应后才能发出新的请求
- 每个引用对象花费一个RTT
流水方式的持久HTTP:
- HTTP/1.1的默认模式
- 客户端遇到一个引用对象就立即产生一个请求
- 所有引用(小)对象只花费一个RTT是可能的
HTTP请求报文
两种类型的HTTP报文:请求、响应
HTTP请求报文:
ASCII(人能阅读)
绝大部分的HTTP请求报文使用GET方法。

请求行:
3个字段:
- 方法字段
- GET
- POST
- HEAD
- PUT
- DELETE
- URL字段
- 带有请求对象的标识,该浏览器正在请求对象
/somedir/page.html
- 带有请求对象的标识,该浏览器正在请求对象
- HTTP版本字段
- 该例子中使用的HTTP版本是1.1
首部行:
- Host:www.someschool.edu
- 指明了对象所在的主机
- 该首部行提供的信息是Web代理高速缓存所要求的
- Connection:close
- 该浏览器告诉服务器不要麻烦地使用持续链接,它要求服务器在发送完被请求的对象后就关闭这条连接
- User-agent:Mozilla/5.0
- 用来指明用户代理,即向服务器发送请求的浏览器的类型。这里浏览器类型是Mozilla/5.0,即Fire-fox浏览器。
- 这个首部行是有用的,因为服务器可以有效地为不同类型的用户代理实际发送相同对象的不同版本。(每个版本都由相同的URL寻址。)
- Accept-language:fr
- 表示用户想得到该对象的法语版本(如果服务器中有这样的对象的话),否则,服务器应当发送它的默认版本。
通用格式
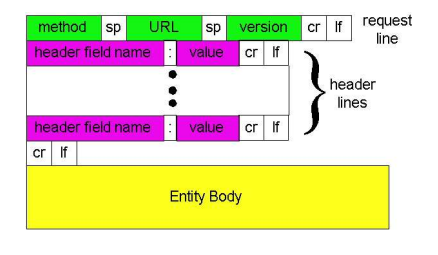
实体体:
- 使用GET方法时,实体体为空
- 使用POST方法(提交表单等)时,使用该实体体,该实体体中包含的就是用户在表单字段中的输入值。
提交表单输入
Post方式:
- 网页通常包括表单输入
- 包含在实体主体(entity body)中的输入被提交到服务器
URL方式:
- 方法:GET
- 输入通过请求行的URL字段上载
方法类型
HTTP/1.0
- GET
- POST
- HEAD
- 要求服务器在响应报文中不包含请求对象 -> 故障跟踪
- 类似于GET方法。当服务器收到一个使用HEAD方法的请求时,将会用一个HTTP报文进行响应,但是并不返回请求对象。
HTTP/1.1
- GET、POST、HEAD
- PUT
- 将实体主体中的文件上载到URL字段规定的路径
- DELETE
- 删除URL字段规定的文件
HTTP响应报文
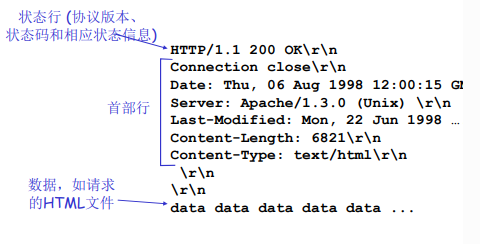
状态行:
- 协议版本字段
- 状态码
- 相应的状态信息
首部行:
- Connection:close
- 发送完成后将关闭该TCP连接
- Date:
- 服务器从它的文件系统中检索到该对象,将该对象插入响应报文,并发送该响应报文的时间。
- Server:Apache/1.3.0
- 该报文是由一台 Apache Web服务器产生的,它类似于HTTP请求报文中的 “User-agent:” 首部行。
- Last-Modified:
- 该对象创建或最后修改的时间与日期
- Last-Modified 首部行对既可能在本地客户也可能在网络缓存服务器(代理服务器)上的对象来说分厂重要。
- Content-Length:6812\r\n
- 指示了被发送对象中的字节数
- Content-Type:text/html\r\n
- 指示了实体体中的对象是HTML文本
- 该对象类型应该正式地使用 “Content-Type:” 首部行而不是文件扩展名来指示。
HTTP响应状态码
位于服务器 -> 客户端的响应报文中的首行
一些状态码的例子:
- 200 OK
- 请求成功,请求对象包含在响应报文的后续部分
- 301 Moved Permanently
- 请求的对象已经被永久转移了;新的URL在响应报文的Location 首部行中指定
- 客户端软件自动用新的URL去获取对象
- 400 Bad Request
- 一个通用的差错代码,表示该请求不能被服务器解读
- 404 Not Found
- 请求的文档在该服务上没有找到
- 505 HTTP Version Not Supported
- 服务器不支持请求报文使用的HTTP版本。
用户-服务器状态:cookies
大多数主要的门户网站使用 cookies
四个组成部分:
- 在HTTP响应报文中有一个cookie的首部行
- 在HTTP请求报文含有一个cookie的首部行
- 在用户端系统中保留有一个cookie文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
Cookies:维护状态
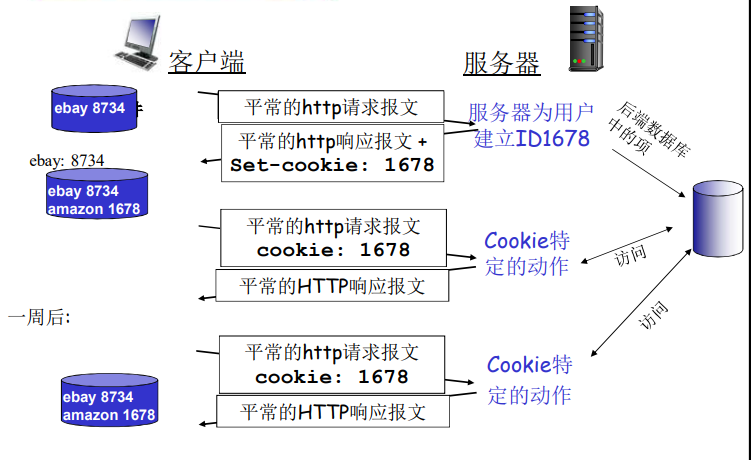
Cookies能带来什么
- 用户验证
- 购物车
- 推荐
- 用户状态(Web e-mail)
如何维持状态:
- 协议端节点:在多个事务上,发送端和接收端维持状态
- cookies:http报文携带状态信息
Cookies与隐私:
- Cookies允许站点知道许多关于用户的信息
- 可能将它知道的东西卖给第三方
- 使用重定向和cookie的搜索引擎还能知道用户更多的信息
- 如通过某个用户在大量站点上的行为,了解其个人浏览方式的大致模式
- 广告公司从站点获得信息
Web缓存(代理服务器)
Web缓存也叫代理服务器,它是能够代表初始Web服务器来满足HTTP请求的网络实体。
Web缓存
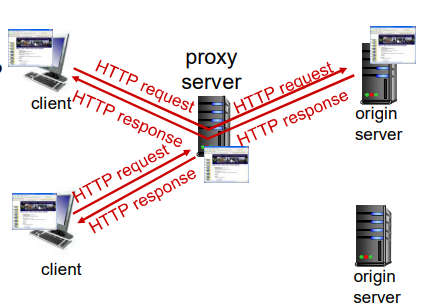
目标:不访问原始服务器,就能满足客户的请求
用户设置浏览器:通过缓存访问Web
浏览器将所有的HTTP请求发给缓存
- 在缓存中的对象:缓存直接返回对象
- 如对象不在缓存,缓存请求原始服务器,然后在将对象返回给客户端
缓存既是客户端又是服务器
通常缓存是由ISP购买并安装(大学、公司、居民区ISP)
为什么要使用Web缓存?
- 降低客户端的请求响应时间
- 可以大大减少一个机构内部网络与Internet接入链路上的流量
- 互联网大量采用了缓存,可以使较弱的ICP也能够有效提供内容
Web缓存器是一种可以缓存Web页面和资源的设备或软件,它可以在用户和服务器之间充当中间代理,提供快速访问和更高的性能。Web缓存器可以将常用的Web页面和资源存储在本地缓存中,当用户请求相同的页面或资源时,可以直接从缓存中获取,避免了重复的网络请求和服务器的响应,减少了网络流量和延迟,提高了用户的体验和系统的性能。
Web缓存器可以部署在不同的位置和层次,例如客户端缓存、代理服务器缓存、CDN缓存等,它们之间的差别主要在于缓存的位置和范围。客户端缓存通常部署在用户设备上,可以缓存一些静态资源,例如图片、样式表、脚本等,可以提高页面的加载速度和用户的体验。代理服务器缓存通常部署在本地网络或ISP上,可以缓存一些常用的Web页面和资源,可以减少网络负载和延迟,提高系统的性能和可伸缩性。CDN缓存通常部署在全球各地的服务器上,可以缓存一些大型的静态资源,例如视频、音频、图片等,可以提高全球用户的访问速度和体验。
需要注意的是,Web缓存器存在一些问题和挑战,例如缓存更新的问题、缓存一致性的问题、缓存污染的问题等,需要采取一些策略和技术来解决。例如,可以采用缓存过期时间、缓存验证机制、缓存命中率监控等技术来优化缓存策略和性能。此外,Web缓存器还需要考虑安全性、隐私性和合法性等方面的问题,避免出现缓存泄露、缓存污染、缓存劫持等安全问题。
总之,Web缓存器是一种可以缓存Web页面和资源的设备或软件,可以在用户和服务器之间充当中间代理,提供快速访问和更高的性能。Web缓存器可以部署在不同的位置和层次,例如客户端缓存、代理服务器缓存、CDN缓存等,可以采取一些策略和技术来优化缓存策略和性能。
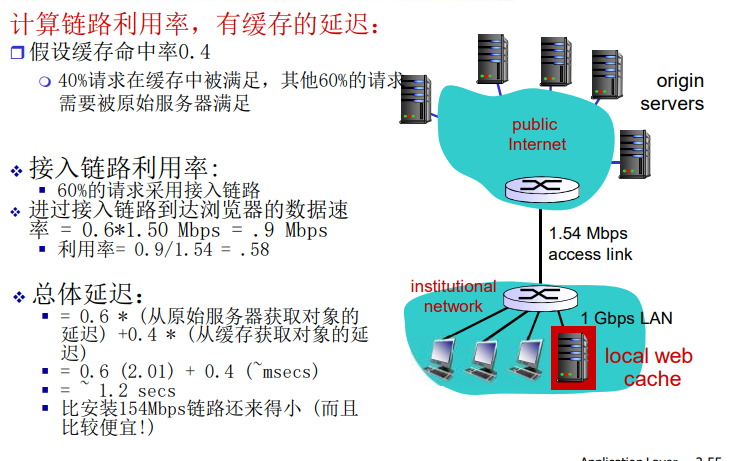
缓存示例
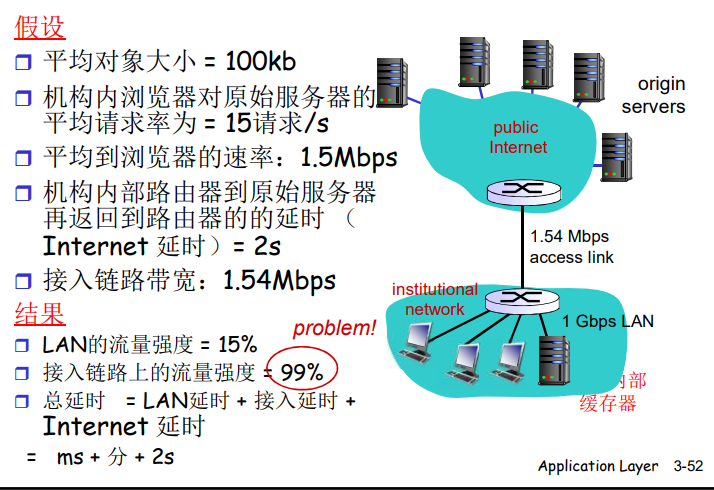
缓存示例:更快的接入链路
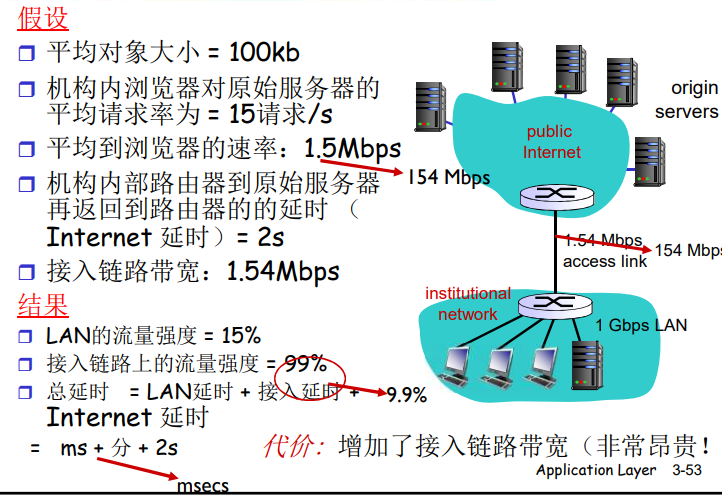
缓存示例:安装本地缓存
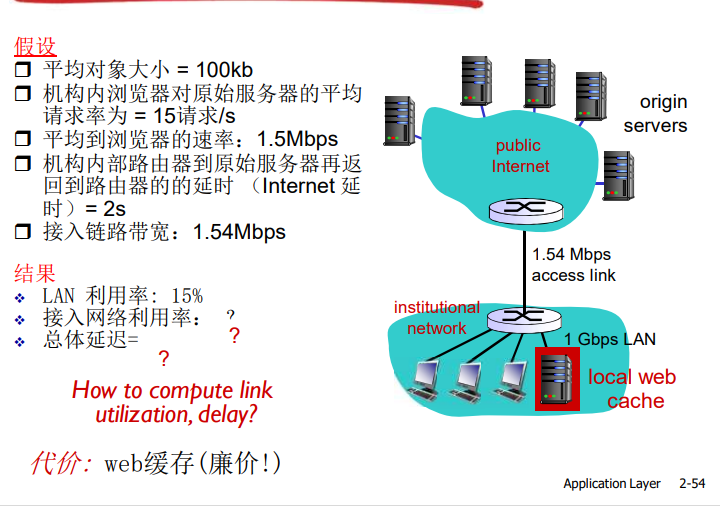
缓存示例:安装本地缓存
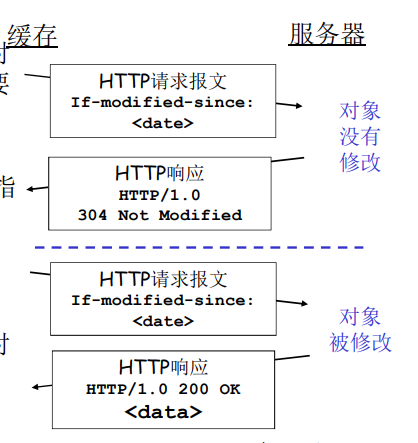
条件GET方法
HTTP有一种机制,允许缓存器证实它的对象是最新的。该缓存器通过发送一个条件GET执行最新检查。
目标:如果缓存器中的对象拷贝是最新的,就不要发送对象
缓存器:在HTTP请求中指定缓存拷贝的日期
If-modified-since:<date>服务器:如果缓存拷贝陈旧,则响应报文没包含对象:
HTTP/1.0 304 Not Modified它告诉缓存器可以使用该对象,能向请求的浏览器转发它(该代理缓存器)缓存的对象副本。
FTP
FTP:文件传输协议
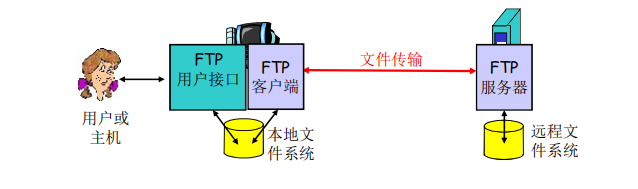
- 向远程主机上传输文件或从远程主机接收文件
- 客户/服务器模式
- 客户端:发起传输的一方
- 服务器:远程主机
- FTP:RFC 959
- FTP服务器:端口号为21
FTP:控制连接与数据连接分开

- FTP客户端与FTP服务器通过端口 21 联系,并使用TCP为传输协议
- 客户端通过控制连接获得身份确认
- 客户端通过控制连接发送命令浏览远程目录
- 收到一个文件传输命令时,服务器打开一个到客户端的数据连接
- 一个文件传输完成后,服务器关闭连接
- 控制连接:带外(“out of band”)传送
- FTP服务器维护用户的状态信息:当前路径、用户账户与控制连接对应
FTP命令、响应
命令样例:
- 在控制连接上以ASCII文本方式传送
- USER username
- PASS password
- LIST:请服务器返回远程主机当前目录的文件列表
- RETR filename:从远程主机的当前目录检索文件(gets)
- STOR filename:向远程主机的当前目录存放文件(puts)
返回码样例:
状态码和状态信息(同HTTP)
331 Username OK,
password required
125 data connection
already open;
transfer starting
425 Can’t open data
connection
452 Error writing
file
FTP(File Transfer Protocol)是一种在计算机网络中用于文件传输的协议,它可以实现将文件从一个计算机传输到另一个计算机。FTP协议通常使用客户端/服务器模型,客户端通过FTP客户端软件连接到FTP服务器,并通过FTP协议进行文件传输。
FTP协议的主要特点是可靠性、灵活性和安全性。FTP协议提供了多种传输模式和数据格式,可以灵活地适应不同场景下的文件传输需求。同时,FTP协议还支持多种身份验证和加密机制,可以确保文件传输的安全性。
在FTP协议中,文件传输通常由两个不同的端口进行控制和数据传输。FTP客户端通过控制端口与FTP服务器建立连接,并发送FTP命令进行文件传输的控制。FTP服务器通过数据端口与FTP客户端建立连接,并在数据端口上传输文件数据。
当进行FTP文件传输时,FTP客户端需要提供目标文件的路径和文件名,FTP服务器会检查是否有相应的权限,并返回文件数据的响应。FTP客户端会根据响应,向FTP服务器发送有关文件传输的命令,并在数据端口上传输文件数据。传输完成后,FTP客户端和FTP服务器会结束数据连接,并关闭控制连接。
需要注意的是,FTP协议的传输过程可能会受到网络环境、传输数据的大小和数量等因素的影响,可能会出现传输中断、传输速度慢等问题。因此,在进行FTP文件传输时,需要根据实际情况选择合适的传输模式和数据格式,并进行适当的优化和调整,以确保文件传输的成功和效率。
总之,FTP是一种在计算机网络中用于文件传输的协议,它具有可靠性、灵活性和安全性等特点,在文件传输中发挥着重要的作用。
电子邮件(EMail)
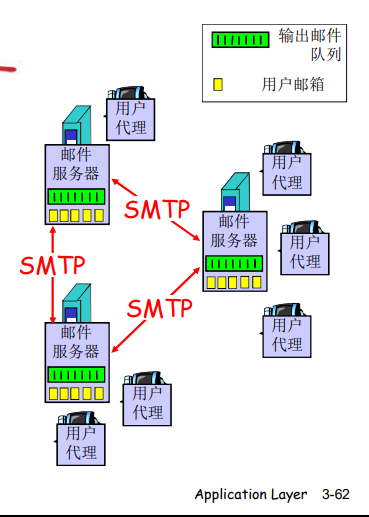
3个主要组成部分:
- 用户代理
- 邮件服务器
- 简单邮件传输协议:SMTP
用户代理:
- 又名 ”邮件阅读器“
- 撰写、编辑和阅读文件
- 如Outlook、Foxmail
- 输出和输入邮件保存在服务器上
EMail:邮件服务器
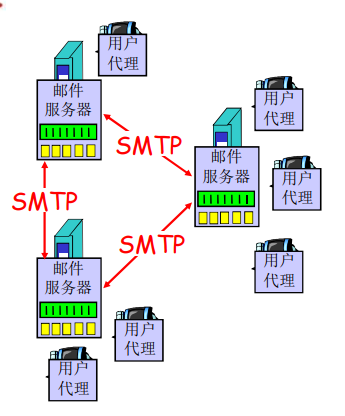
邮件服务器
- 邮箱中管理和维护发送给用户的邮件
- 输出报文队列保持发送邮件报文
- 邮件服务器之间的SMTP协议:发送email报文
- 客户:发送方邮件服务器
- 服务器:接收端邮件服务器
SMTP [RFC 2821]
- 使用TCP在客户端和服务器之间传送报文,端口号为25
- 直接传输:从发送方服务器到接收方服务器(一般不使用中间邮件服务器发送邮件)
- 传输的3个阶段
- 握手
- 传输报文
- 关闭
- 命令/响应交互
- 命令:ASCII文本
- 响应:状态码和状态信息
- 报文必须为7位ASCII码
SMTP是因特网电子邮件的核心,SMTP用于从发送方的邮件服务器发送报文到接收方的邮件服务器。但它所具有的陈旧特征表明它仍然是一种继承的技术。
在用SMTP传送邮件之前,需要将二进制多媒体数据编码为ASCII码,并且在使用SMTP传输后要求将相应的ASCII码邮件解码还原为多媒体数据。(但使用HTTP传送前不需要将多媒体数据编码为ASCII码)
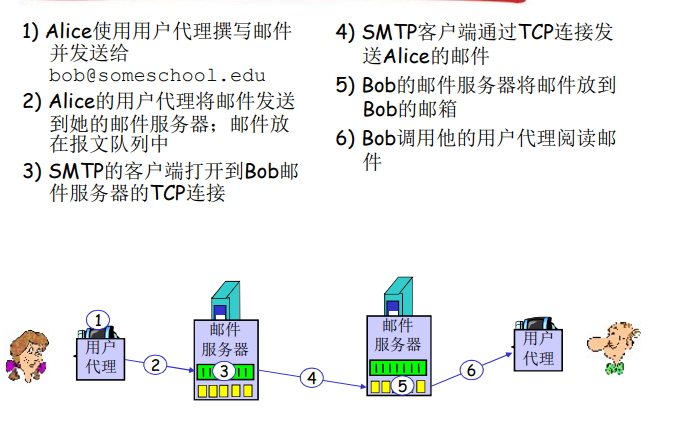
举例:Alice给Bob发送报文
SMTP是一种在计算机网络中用于电子邮件传输的协议,它可以实现将邮件从一个计算机传输到另一个计算机。SMTP协议通常使用客户端/服务器模型,客户端通过SMTP客户端软件连接到SMTP服务器,并通过SMTP协议进行电子邮件传输。
SMTP协议的主要特点是可靠性、灵活性和安全性。SMTP协议提供了多种传输模式和数据格式,可以灵活地适应不同场景下的电子邮件传输需求。同时,SMTP协议还支持多种身份验证和加密机制,可以确保电子邮件传输的安全性。
在SMTP协议中,电子邮件传输通常由两个不同的端口进行控制和数据传输。SMTP客户端通过控制端口与SMTP服务器建立连接,并发送SMTP命令进行电子邮件传输的控制。SMTP服务器通过数据端口与SMTP客户端建立连接,并在数据端口上传输电子邮件数据。
当进行SMTP电子邮件传输时,SMTP客户端需要提供目标邮件地址、邮件主题、邮件正文等信息,SMTP服务器会检查是否有相应的权限,并返回邮件数据的响应。SMTP客户端会根据响应,向SMTP服务器发送有关电子邮件传输的命令,并在数据端口上传输邮件数据。传输完成后,SMTP客户端和SMTP服务器会结束数据连接,并关闭控制连接。
需要注意的是,SMTP协议的电子邮件传输过程可能会受到网络环境、邮件大小和数量等因素的影响,可能会出现传输中断、传输速度慢等问题。因此,在进行SMTP电子邮件传输时,需要根据实际情况选择合适的传输模式和数据格式,并进行适当的优化和调整,以确保电子邮件传输的成功和效率。
总之,SMTP是一种在计算机网络中用于电子邮件传输的协议,它具有可靠性、灵活性和安全性等特点,在电子邮件传输中发挥着重要的作用。
STMP:总结
- SMTP是一个推协议
- SMTP使用持久连接
- SMTP要求报文(首部和主体)为7位ASCII编码
- SMTP服务器使用CRLF。CRLF决定报文的尾部
HTTP比较:
- HTTP:拉(pull)
- SMTP:推(push)
- 二者都是ASCII形式的命令/响应交互、状态码
- HTTP:每个对象封装在各自的响应报文中
- SMTP:多个对象包含在一个报文中
邮件报文格式
SMTP:交换email报文的协议
RFC 822:文本报文的标准:
- 首部行:如 To,From,Subject。与SMTP命令不同
- 主体
- 报文:只能是ASCII码字符
报文格式:多媒体扩展
- MIME:多媒体邮件扩展(multimedia mail extension), RFC 2045, 2056
- 在报文首部用额外的行声明MIME内容类型

邮件访问协议
Alice的用户代理用SMTP或HTTP将电子邮件报文推入她的邮件服务器,接着她的邮件服务器(作为一个SMTP客户)再用SMTP将该邮件中继(推)到Bob的邮件服务器。
这个过程分成两部:因为不通过Alice的邮件服务器进行中继,Alice的用户代理将没有任何办法到达一个不可达的目的地邮件服务器。通过首先将邮件存放在自己邮件服务器中,Alice的邮件服务器可以重复地尝试向Bob的邮件服务器发送该报文,如每30分钟一次,知道Bob的邮件服务器变得运行为止。(如果Alice的服务器关机,则她能向系统管理员进行申告!)
- SMTP:传送到接收方的邮件服务器,SMTP是一个推协议。
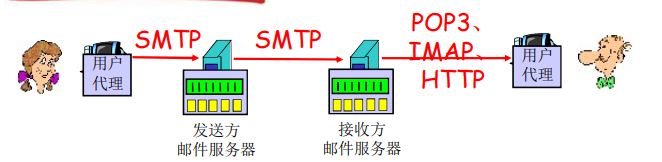
- 邮件访问协议:从服务器访问邮件
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
- 用户身份确认(代理 <–>服务器)并下载
- IMAP:Internet邮件访问协议(Internet Mail Access Protocol)[RFC 1730]
- 更多特性(更复杂)
- 在服务器上处理存储的报文
- HTTP:Hotmail,Yahoo!Mail等
- 方便
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
POP3与IMAP
POP3(本地管理文件夹)

- 先前的例子使用 ”下载并删除” 模式。
- 如果改变客户机,Bob不能阅读邮件
- “下载并保留” :不同客户机上为报文的拷贝
- POP3在会话中是无状态的
IMAP(因特网邮件访问协议)
- IMAP服务器将每个报文与一个文件夹联系起来
- 允许用户用目录来组织报文
- 允许用户读取报文组件
- IMAP在会话过程中保留用户状态:
- 目录名、报文ID与目录名之间映射
POP3和IMAP是两种在计算机网络中用于电子邮件接收的协议,它们可以实现将邮件从服务器上下载到本地计算机。POP3和IMAP的主要区别在于邮件的存储方式和访问方式。
POP3(Post Office Protocol Version 3)协议是一种将电子邮件从邮件服务器下载到本地计算机的协议,它支持在本地计算机上保存邮件,并可以离线访问已经下载的邮件。POP3协议的主要特点是简单和高效,它可以快速地将邮件下载到本地计算机,并且不需要保持与邮件服务器的连接。但是,POP3协议不支持在多台设备上同步访问邮件,也不支持对邮件进行标记、归档等操作。
IMAP(Internet Message Access Protocol)协议是一种在邮件服务器上直接操作邮件的协议,它支持在多台设备之间同步访问邮件,并且可以对邮件进行标记、归档等操作。IMAP协议的主要特点是灵活和高级,它可以在多台设备之间同步访问邮件,并且可以对邮件进行更多的操作。但是,IMAP协议需要保持与邮件服务器的连接,并且邮件数据存储在邮件服务器上,需要对邮件服务器进行定期备份和维护。
在使用电子邮件时,选择POP3或IMAP协议需要根据实际需求进行选择。如果需要在本地计算机上保存邮件,并且只在一台设备上访问邮件,可以选择POP3协议;如果需要在多台设备之间同步访问邮件,并且需要对邮件进行标记、归档等操作,可以选择IMAP协议。
总之,POP3和IMAP是两种在计算机网络中用于电子邮件接收的协议,它们具有不同的特点和用途,在使用电子邮件时需要根据实际需求进行选择。
DNS
DNS(域名系统)服务器通常是运行BIND软件的UNIX机器,DNS协议运行在UDP之上,使用53号端口。
DNS是:
- 一个由分层的 DNS服务器实现的分布式数据库
- 一个使得主机能够查询分布式数据库的应用层协议
DNS(Domain Name System)
DNS的必要性
IP地址标识主机、路由器
但IP地址不好记忆,不便人类使用(没有意义)
人类一般倾向于使用一些有意义的字符串来标识 Internet 上的设备
例如:qzheng@ustc.edu..cn所在的邮件服务器
存在着 ”字符串“ — IP地址的转换的必要性
人类用户提供要访问机器的 ”字符串“ 名称
由DNS负责转换成为二进制的网络地址
DNS系统需要解决的问题
问题1:如何命名设备
- 用有意义的字符串:好记,便于人类使用
- 解决一个平面命名的重名问题:层次化命名
问题2:如何完成名字到IP地址的转换
- 分布式的数据库维护的响应名字查询
问题3:如何维护:增加或者删除一个域,需要在域名系统中做哪些工作
DNS的历史

DNS总体思路和目标
DNS通常是由其他应用层协议所使用的,包括HTTP和SMTP,将用户提供的主机名解析为IP地址。
用户主机将一个HTTP请求报文发送到Web服务器www.someschool.edu,该用户主机必须获得www.someschool.edu的IP地址。做法如下:
- 同一台用户主机上运行着DNS应用的客户端。
- 浏览器从上述URL中抽取出主机名www.someschool.edu,并将主机名传给DNS应用的客户端。
- DNS客户向DNS服务器发送一个包含主机名的请求
- DNS客户最终会收到来自DNS的该IP地址,它就向位于该IP地址80端口的HTTP服务器进程发起一个TCP连接。
DNS的主要思路
- 分层的、基于域的命名机制
- 若干分布式的数据库完成名字到IP地址的转换
- 运行在UDP之上的端口号为53的应用服务
- 核心的 Internet 功能,但以应用层协议实现
- 在网络边缘处理复杂性
DNS主要目的
实现主机名-IP地址的转换(name/IP translate)
其它目的
主机别名到规范名字的转换:Host aliasing
应用程序可以调用DNS来获得主机别名对应的规范主机名以及主机的IP地址
邮件服务器别名到邮件服务器的正规名字的转换:Mail server aliaing
负载均衡:Load Distribution
问题1:DNS名字空间
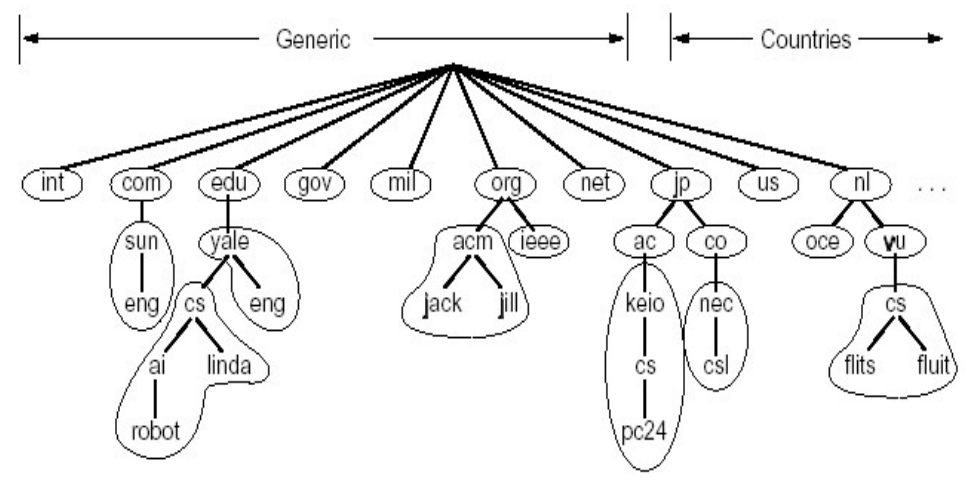
DNS域名结构
- 一个层面命名设备会有很多重名
- DNS采用层次树状结构的命名方法
- Internet 跟被划为几百个顶级域(top lever domains)
- 通用的(generic)
- .com
- .edu
- .gov
- .firm
- 国家的(countries)
- .cn
- .us
- .nl
- .jp
- 通用的(generic)
- 每个(子)域下面可划分为若干子域(subdomains)
- 树叶是主机
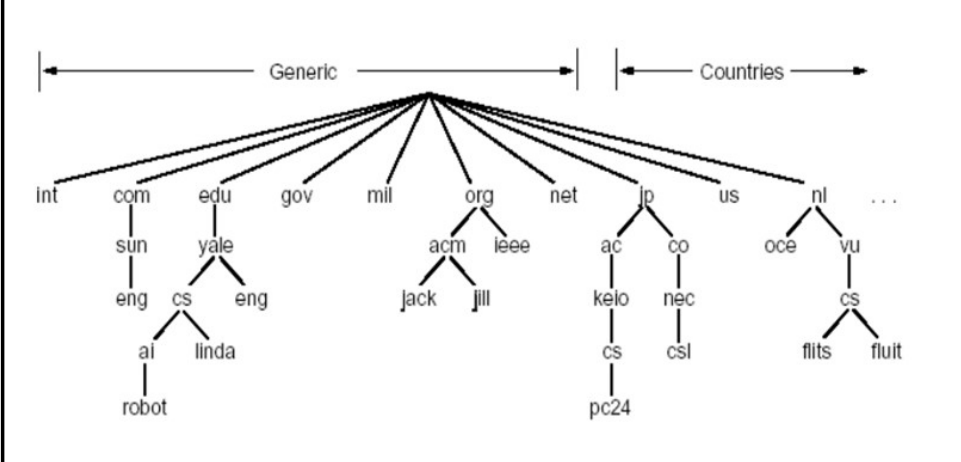
域名(Domain Name)
从本域往上,直到树根
中间使用 点(.)间隔不同的级别
例如:ustc.edu.cn
auto.ustc.edu.cn
域的域名:可以用于表示一个域
主机的域名:一个域上的一个主机
域名的管理
- 一个域管理其下的子域
- .jp 被划分为 ac.jp co.jp
- .cn 被划分为 edu.cn com.cn
- 创建一个新的域,必须征得它所属域的同意
域与物理网络无关
- 域遵从组织界限,而不是物理网络
- 一个域的主机可以不在一个网络
- 一个网络的主机不一定在一个域
- 域的划分是逻辑的,而不是物理的
DNS:根名字服务器
根名字服务器提供TLD(顶级域)服务器的IP地址。
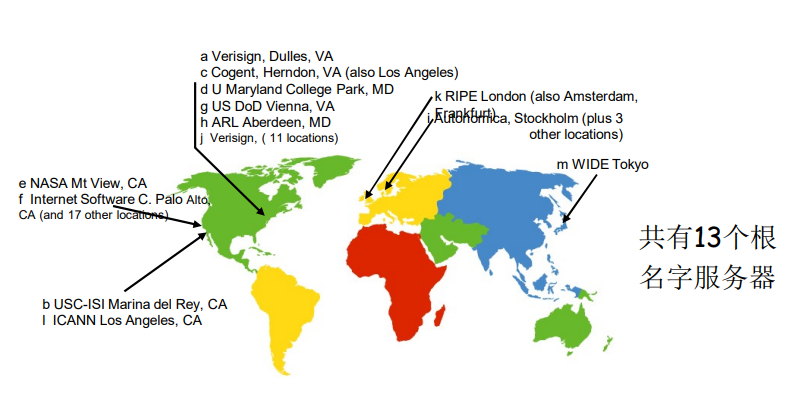
问题2:解析问题-名字服务器
一个名字服务器的问题
- 可靠性问题:单点故障
- 扩展性问题:通信容量
- 维护问题:远距离的集中式数据库
区域(zone)
- 区域的划分有区域管理者自己决定
- 将DNS名字空间划分为互不相交的区域,每个区域都是树的一部分
- 名字服务器:
- 每个区域都有一个名字服务器:维护着它所管辖区域的权威信息(authoritative record)
- 名字服务器允许被放置在区域之外,以保障可靠性
名字空间划分为若干区域:Zone
权威DNS服务器:组织机构的DNS服务器,提供组织机构服务器(如Web 和 mail)可访问的主机和IP之间的映射
组织机构可以选择实现自己维护或由某个服务提供商来维护
TLD服务器
顶级域(TLD)服务器:负责顶级域名(如com,org,net,edu和gov)和所有国家级的顶级域名(如cn,uk,fr,ca,jp)
- Network solutions 公司维护 com TLD 服务器
- Educause 公司维护 edu TLD 服务器
TLD服务器提供了权威DNS服务器的IP地址。
区域名字服务器维护资源记录
资源记录(resource records)
- 作用:维护 域名-IP地址(其他)的映射关系
- 位置:Name Server 的分布式数据库中
RR格式: (domain_name,ttl,type,class,Value)
- Domain_name:域名
- Ttl:time to live:生存时间(权威,缓冲记录)
- Class 类别:对于Internet,值为IN
- Value 值:可以是数字,域名或ASCII串
- Type 类别:资源记录的类型
DNS记录和报文
共同实现DNS分布式数据库的所有DNS服务器存储了资源记录 。
DNS:保存资源记录(RR)的分布式数据库

TTL:生存时间,用于控制DNS缓存的机制,可以指定DNS记录在缓存中存留的时间,超过这个事件后,DNS记录就会过期并从缓存中删除。
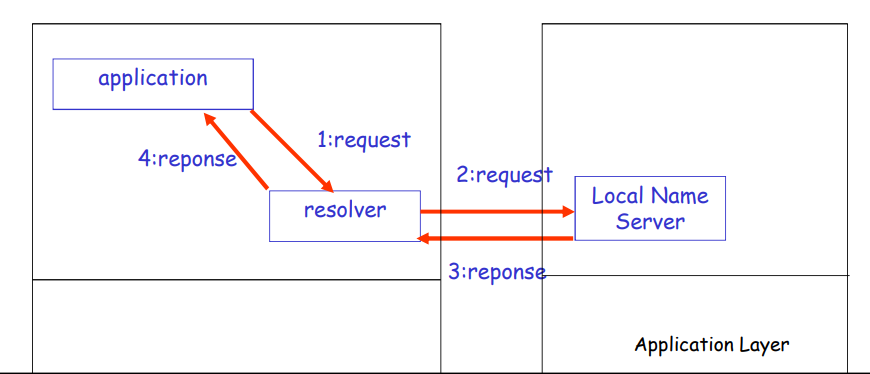
DNS大致工作过程
- 应用调用 解析器(resolver)
- 解析器作为客户 向 Name Server 发出查询报文(封装在UDP段中)
- Name Server 返回响应报文(name/ip)
名字服务器
本地名字服务器(Local Name Server)
- 并不严格属于层次结构
- 每个ISP(居民区的ISP、公司、大学)都有一个本地DNS服务器
- 也称为 “默认名字服务器”
- 当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器
- 起着代理作用,将查询转发到层次结构中
名字服务器(Name Server)
名字解析过程
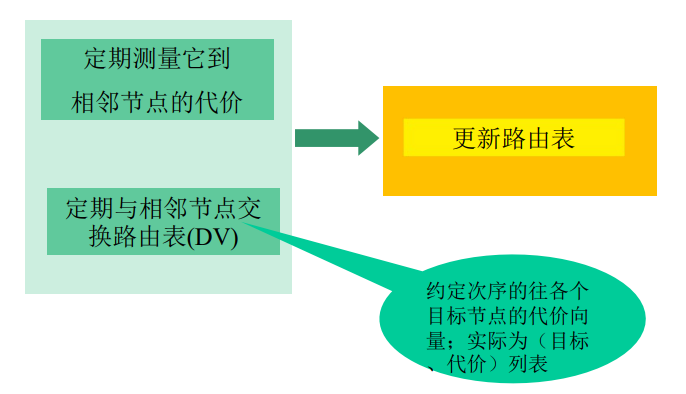
- 目标名字在 Local Name Server 中
- 情况1:查询的名字在该区域内部
- 情况2:缓存(cashing)
当与本地名字服务器不能解析名字时,联系根名字服务器顺着 根 - TLD 一直找到 权威名字服务器

通过主机名查询其IP地址
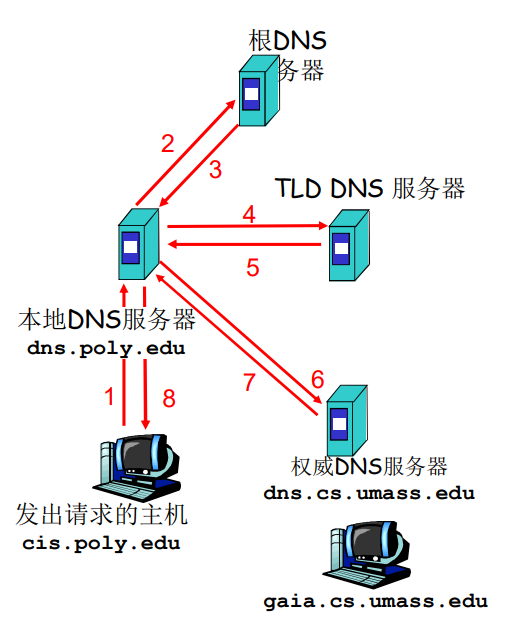
递归查询
递归查询:
- 名字解析负担都放在当前联络的名字服务器上
- 问题:根服务器的负担太重
- 解决:迭代查询(iterated queries)
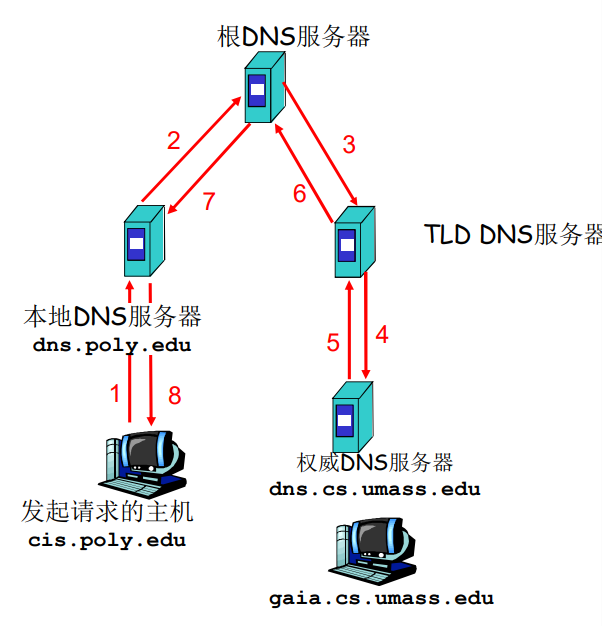
本地DNS服务器:当主机发送DNS请求时,它起着代理的作用,并将该请求转发到DNS服务器层次结构中。
本地DNS服务器是指一种在本地计算机上运行的DNS服务器,它可以加快域名解析的速度并提高域名解析的准确性。
DNS(Domain Name System)是一种将域名和IP地址相互映射的分布式数据库系统。当我们在浏览器中输入一个域名时,浏览器会向本地DNS服务器发起查询请求,本地DNS服务器会查询缓存或者向其他DNS服务器发起查询请求,最终将域名解析成IP地址并返回给浏览器,浏览器再通过IP地址访问对应的网站。
使用本地DNS服务器可以加快域名解析的速度,因为本地DNS服务器通常会缓存已解析的域名和IP地址,当再次访问已缓存的域名时,本地DNS服务器可以直接返回缓存中的IP地址,不需要再向其他DNS服务器发起查询请求。同时,本地DNS服务器还可以提高域名解析的准确性,因为它可以通过配置本地DNS记录来实现自定义的域名解析。
搭建本地DNS服务器需要安装DNS服务器软件,并进行相应的配置。常见的DNS服务器软件有BIND、dnsmasq等。在配置DNS服务器时,需要设置本地DNS记录、转发DNS请求等参数,以实现本地DNS服务器的功能。
总之,本地DNS服务器是一种可以加快域名解析速度并提高解析准确性的DNS服务器,可以通过安装DNS服务器软件并进行相应配置来实现。
迭代查询
主机 cis.poly.edu 想知道主机 gaia.cs.umass.edu 的IP地址
- 根(及各级域名)服务器返回的不是查询结果,而是下一个NS的地址
- 最后由权威名字服务器给出解析结果
- 当前联络的服务器给出可以联系服务器的名字
- ”我不知道这个名字,但可以向这个服务器请求“
DNS协议、报文
DNS协议:查询和响应报文的报文格式相同

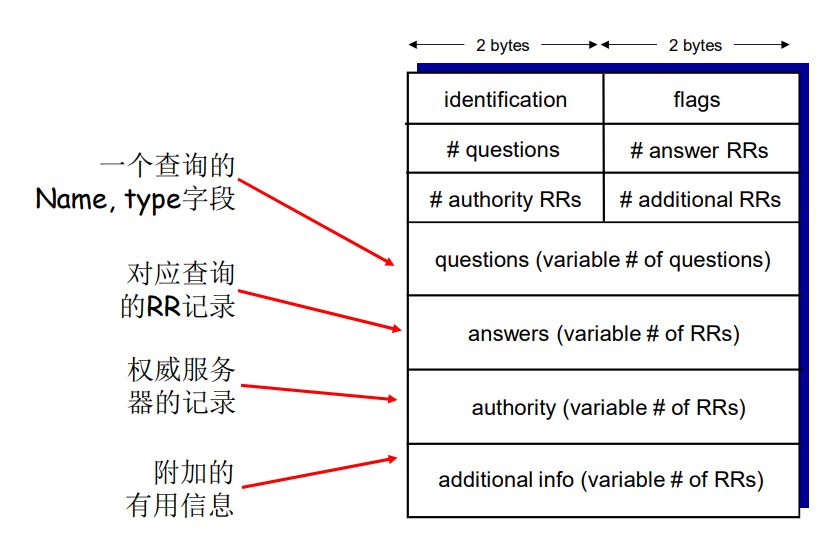
提高性能:缓存
DNS缓存:为了改善时延性能并减少在因特网上到处传输的DNS报文数量
- 一旦名字服务器得到了一个映射,就将该映射缓存起来
- 根服务器通常都在本地服务器中缓存着
- 使得根服务器不用经常被访问
- 目的:提高效率
- 可能存在的问题:如果情况变化,缓存结果和权威资源记录不一致
- 解决方案:TTL(默认2天)
- 由于主机和主机明明与IP地址间的映射并不是永久的,DNS服务器在一段时间后(通常设置为2天)将丢弃缓存的信息。
问题3:维护问题:新增一个域
在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名和域名服务器的地址
在新增子域 的 名字服务器上运行名字服务器,负责本域的名字解析:名字 –> IP地址
例子:在com域中建立一个 “Network Utopia”
到注册等级机构注册域名 networkutopia.com
需要向该机构提供权威DNS服务器(基本的、辅助的)的名字和IP地址
等级机构在 com TLD 服务器中插入两条 RR 记录:
(networkutopia.com,dns1.networkutopia.com,NS)
(dns1.networkutopia.com,212.212.212.1,A)
在networkuto pia.com的权威服务器中确保有
- 用于Web服务器的 www.networkuptopia.com的类型为A的记录
- 用于邮件服务器的mail.networkutopia.com的类型为MX的记录
攻击DNS
DDOS攻击
- 对根服务器进行流量轰炸攻击:发送大量ping
- 没有成功
- 原因1:根目录服务器配置了流量过滤器,防火墙
- 原因2:本地 DNS 服务器缓存了TLD服务器的IP地址,因此无需查询根服务器
- 向TLD服务器流量轰炸攻击:发送大量查询
- 可能更危险
- 效果一般,大部分DNS缓存了TLD
总的来说:DNS比较健壮
DDOS(Distributed Denial of Service)攻击是一种利用多台计算机对目标计算机发起攻击的网络攻击行为。DDOS攻击旨在通过占用目标计算机的网络带宽和系统资源,使其无法正常提供服务或访问网络。
DDOS攻击通常使用大量的控制计算机和代理计算机,通过向目标计算机发送大量的请求或数据包,占用其网络带宽和系统资源,导致目标计算机无法正常工作。DDOS攻击可以采用多种方式进行,包括流量攻击、协议攻击、应用层攻击等。
流量攻击是一种通过向目标计算机发送大量的网络流量来占用其网络带宽和系统资源的攻击方式。流量攻击通常使用大量的控制计算机和代理计算机,通过向目标计算机发送大量的请求或数据包,使其无法正常响应。流量攻击可以采用多种方式进行,包括UDP Flood、TCP SYN Flood、ICMP Flood等。
协议攻击是一种通过向目标计算机发送大量的协议请求来占用其网络带宽和系统资源的攻击方式。协议攻击通常使用大量的控制计算机和代理计算机,通过向目标计算机发送大量的协议请求,使其无法正常处理和响应。协议攻击可以针对不同的协议进行,包括DNS协议、NTP协议、SMTP协议等。
应用层攻击是一种通过向目标计算机发送恶意的应用层请求来占用其网络带宽和系统资源的攻击方式。应用层攻击通常针对特定的应用程序进行,通过向目标计算机发送大量的恶意请求,使其无法正常处理和响应。应用层攻击可以采用多种方式进行,包括HTTP请求攻击、HTTPS请求攻击、DNS请求攻击等。
为了防止DDOS攻击,需要采取一系列的安全措施,包括增强网络安全防护、优化网络架构、配置防火墙和入侵检测系统、使用CDN和云防护等。同时,还需要进行合理的容灾和备份,以确保在遭受DDOS攻击时可以快速恢复服务。
总之,DDOS攻击是一种危害性很大的网络攻击行为,可以采用多种方式进行。为了防止DDOS攻击,需要采取一系列的安全措施和应急措施,以确保网络安全和服务可靠。
重定向攻击
- 中间人攻击
- 截获查询,伪造回答,从而攻击某个(DNS回答指定的IP)站点
- DNS中毒
- 发送伪造的应答给DNS服务器,希望它能够缓存这个虚假的结果
- 技术上较困难:分布式截获和伪造
利用DNS基础设施进行DDOS
- 伪造某个IP进行查询,攻击这个目标IP
- 查询放大,响应报文比查询报文大
- 效果有限
重定向攻击(DNS Spoofing)是一种网络攻击行为,攻击者会伪装成DNS服务器,向目标计算机发送虚假的DNS响应,将域名解析到错误的IP地址上。这种攻击行为可能会导致用户被重定向到恶意网站或者无法访问正常网站,从而造成严重的安全风险和损失。
为了防止重定向攻击,可以采取一系列的安全措施,包括:
使用DNSSEC(DNS Security Extensions)协议,该协议可以对DNS查询和响应进行数字签名和验证,防止DNS响应被篡改。
配置防火墙和入侵检测系统,对DNS查询和响应进行监控和过滤,防止伪造的DNS响应进入网络。
使用DNS缓存服务器,对DNS查询结果进行缓存和定期更新,减少DNS查询量和降低被攻击的风险。
更新操作系统和应用程序的安全补丁,以修复可能存在的DNS漏洞和安全漏洞。
总之,重定向攻击是一种危害性很大的网络攻击行为,可以采取多种安全措施来防范和减轻攻击的影响。
P2P应用
纯P2P架构
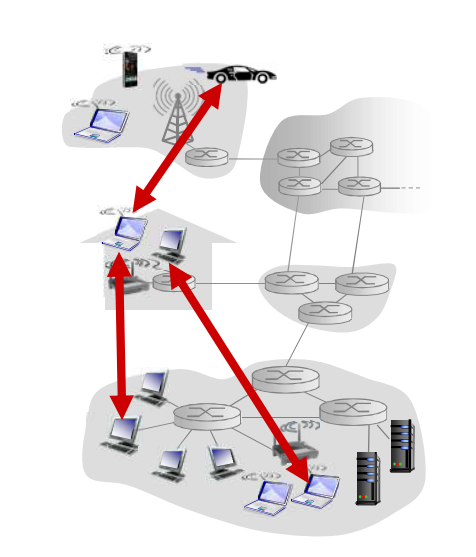
- 没有(或极少)一直运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网,每次IP地址都有可能变化
例子:
- 文件分发(BitTorrent)
- 流媒体(KanKan)
- VoIP(Skype)
使用了P2P体系结构,对总是打开的基础设施服务器依赖最少(或者没有依赖)。与之相反,成对间歇连接的主机(称为对等方)彼此直接通信。
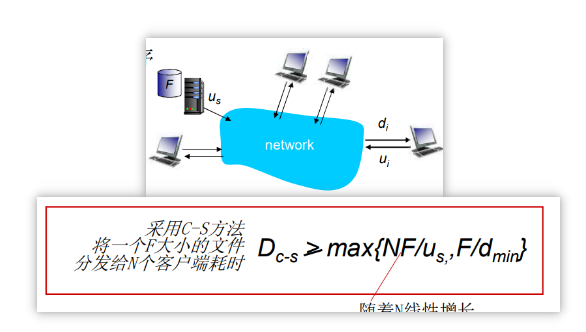
文件分发:C/S vs P2P
分发时间:所有N个对等方得到该文件的副本所需要的时间。
问题:从一台服务器分发文件(大小F)到N个peer需要多少时间?
Peer节点上下载能力是有限的资源
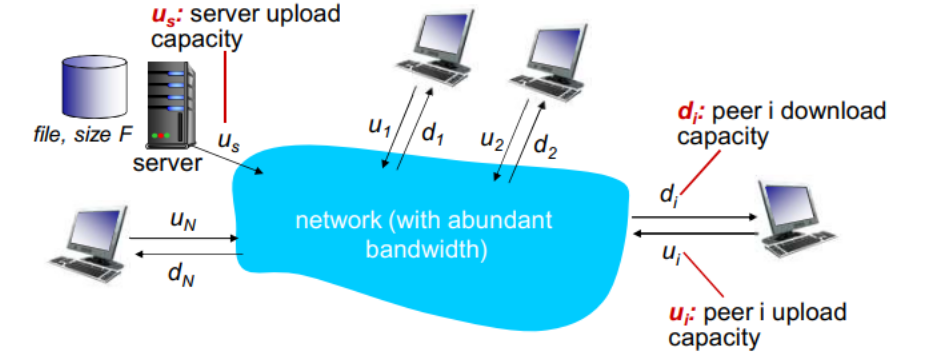
文件分发时间:C/S 模式
服务器传输:都是由服务器发送给 peer,服务器必须顺序传输(上载)N个文件拷贝:
- 发送一个 copy:F/us
- 发送N个 copy:NF/us
客户端:每个客户端必须下载一个文件拷贝
- d(min) = 客户端最小的下载速率
- 下载带宽最小的客户端下载的时间:F/d(min)
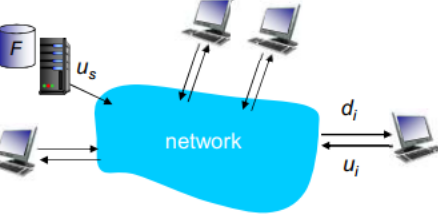
文件分发时间:P2P模式
服务器传输:最少需要上载一份拷贝
- 发送一个拷贝的时间:F/us
客户端:每个客户端必须下载一个拷贝
- 最小下载带宽客户单耗时:F/d(min)
客户端:所有客户端总体总体下载量NF
最大的上载带宽是
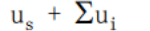
除了服务器可以上载,其他所有的 peer 节点都可以上载
因此:具有P2P体系结构的应用程序能够是自扩展的。这种扩展性的直接成因是:对等方除了是比特的消费者外还是它们的重新分发者。
例子:

P2P文件分发:BitTorrent
- 文件被分为一个个块 256KB
- 网络中的这些peers发送接收文件块,相互服务
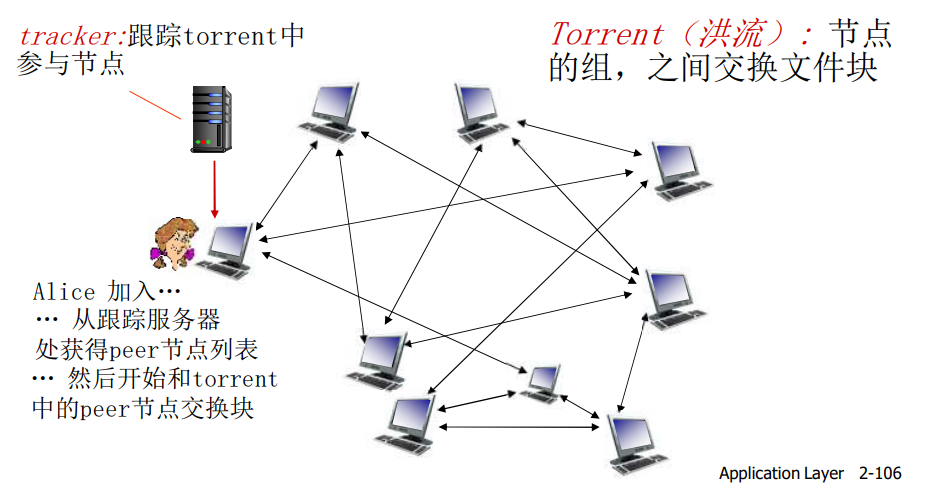
- Peer加入torrent:
- 一开始没有块,但是将会通过其他节点处累计文件块
- 向跟踪服务器注册,获得peer节点列表,和部分peer节点构成邻居关系(“连接”)
- 当peer下载时,该peer可以同时向其他节点提供上载服务
- Peer可能会变换用于交换块的peer节点
- 扰动churn:peer节点可能会上线或者下线
- 一旦一个peer拥有整个文件,它会(自私的)离开或者保留(利他主义)在torrent中
BitTorrent协议的工作原理如下:
- 发布种子文件:文件上传者需要将待传输的文件制作成种子文件,并发布到公开的种子服务器上,以便其他用户可以通过种子文件下载待传输的文件。
- 下载种子文件:其他用户可以通过P2P客户端下载种子文件,并通过种子文件获取待传输文件的信息和下载地址。
- 下载文件块:用户通过P2P客户端连接其他用户,根据文件块的需求和可用性,从其他用户处下载文件块,并在自己的计算机上保存。
- 分享文件块:下载完成的用户可以将自己的文件块上传给其他需要的用户,以帮助其他用户更快地下载文件。BitTorrent协议会优先选择上传速度较快的用户进行文件块的上传。
通过BitTorrent协议进行P2P文件分发可以有效地提高文件传输和分发的速度和效率,同时可以降低单个上传者和下载者的带宽和资源消耗。但是,P2P文件分发也存在一些风险和安全隐患,如版权侵犯、恶意软件传播等问题,需要注意相应的安全措施和风险管理。
BitTorrent:请求,发送文件块
请求块:
- 在任何给定时间,不同peer节点拥有一个文件块的自己
- 周期性的,Alice节点向邻居询问他们拥有哪些块的信息
- Alice向peer节点请求它希望的块,稀缺的块
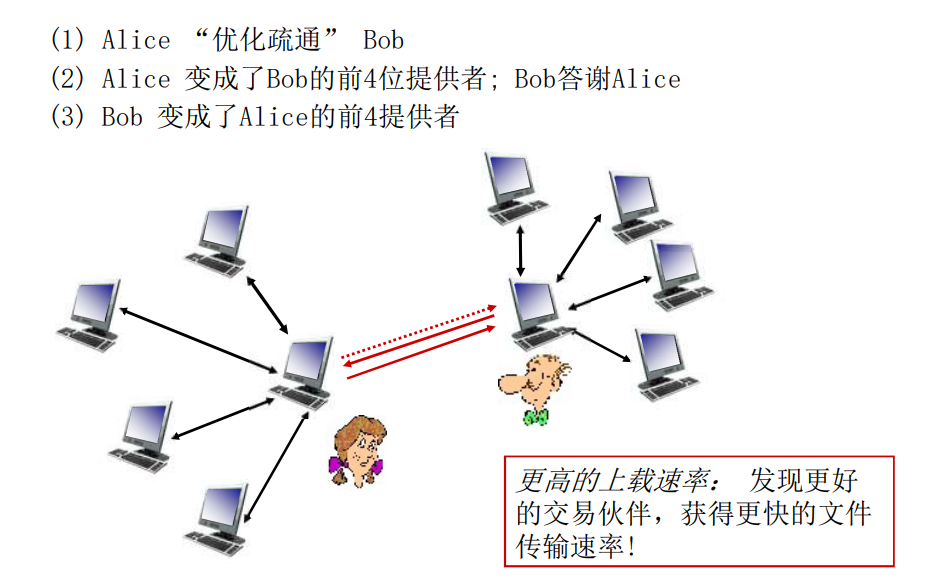
发送块:一报还一报 tit-for-tat
- Alice向4个peer发送块,这些块向他自己提供最大带宽的服务
- 其他peer被Alice阻塞(将不会从Alice处获得服务)
- 每10秒重新评估一次:前4位
- 每个30秒:随机选择其他peer节点,想这个节点发送块
- “优化疏通” 这个节点
- 新选择的节点可以加入这个top4
P2P文件共享
例子:

两大问题:
- 如何定位所需资源
- 如何处理对等方的加入与离开
可能的方案
- 集中
- 分散
- 半分散
P2P:集中式目录
最初的 “Napster” 设计
- 当对等方连接时,它告知中心服务器
- IP地址
- 内容
- Alice查询 “双节棍.MP3”
- Alice从Bob处请求文件
集中式目录存在的问题
- 单点故障
- 性能瓶颈
- 侵犯版权
文件传输是分散的,而定位内容则是高度集中的
查询洪泛:Gnutella
- 全分布式
- 没有中心服务器
- 开放文件共享协议
- 许多Gnutella客户端实现了Gnutella协议
- 类似HTTP有许多的浏览器
覆盖网络:图
- 如果X和Y之间有一个TCP连接,则二者之间存在一条边
- 所有活动的对等方和边就是覆盖网络
- 边并不是物理链路
- 给定一个对等方,通常所连接的节点少于10个
Gnutella:协议
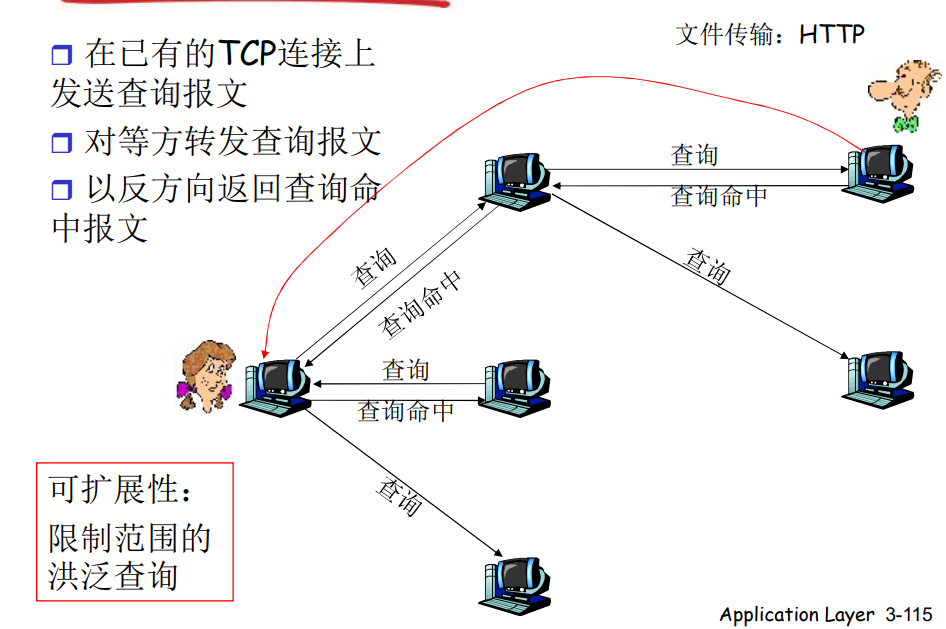
- 在已有的TCP的连接上发送查询报文
- 对等方转发查询报文
- 以反方向返回查询命中报文
可扩展性:限制范围的洪泛查询
Gnutella:对等方加入
- 对等方X必须首先发现某些已经在覆盖网络中的其他对等方:使用可用对等方列表
- 自己维持一张对等方列表(经常开机的对等方的IP)
- 联系维持列表的Gnutella站点
- X接着试图与该列表上的对等方建立TCP连接,直到与某个对等方Y建立连接
- X向Y发送一个Ping报文,Y转发该Ping报文
- 所有收到Ping报文的对等方以Pong报文响应 IP地址、共享文件的数量及总字节数
- X收到许多Pong报文,然后它能建立其他TCP连接
Gnutella是一种基于P2P协议的文件共享网络,可以在不依赖中心服务器的情况下,实现用户之间的文件共享和传输。Gnutella协议采用分布式查询和资源发现机制,用户可以通过Gnutella网络搜索和下载其他用户共享的文件。
Gnutella协议的工作原理如下:
用户加入网络:用户通过Gnutella客户端加入Gnutella网络,并与其他用户建立连接。
分布式查询:用户可以通过Gnutella客户端向其他用户发送查询请求,搜索其他用户共享的文件。查询请求会在Gnutella网络中分布式传播和扩散,直到找到匹配的文件资源。
文件下载:用户可以通过Gnutella客户端从其他用户处下载文件,并在自己的计算机上保存。文件下载过程也是基于P2P协议进行的,用户可以从多个上传者处同时下载文件块,以提高下载速度和效率。
通过Gnutella协议进行P2P文件共享和传输具有很大的优势,可以实现高速的文件传输和广泛的文件共享。但是,Gnutella网络也存在一些问题和隐患,如版权侵犯、恶意软件传播等问题,需要注意相应的安全措施和风险管理。
总之,Gnutella是一种基于P2P协议的文件共享网络,可以实现用户之间的文件共享和传输,具有很大的优势和潜力。
KaZaA
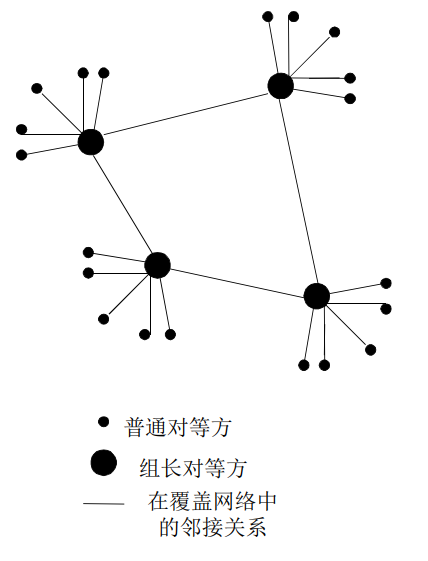
利用不匀称性:KaZaA
- 每个对等方要么是一个组长,要么隶属于一个组长
- 对等方与其组长之间有TCP连接
- 组长对之间有TCP连接
- 组长跟踪其所有的孩子的内容
- 组长与其他组长联系
- 转发查询到其他组长
- 获得其他组长的数据拷贝
KaZaA:查询
- 每个文件有一个散列标识码和一个描述符
- 客户端向其组长发送关键字查询
- 组长用匹配进行响应:
- 对每个匹配:元数据、散列标识码和IP地址
- 如果组长将查询转发给其他组长,其他组长也以匹配进行响应
- 客户端选择要下载的文件
- 向拥有文件的对等方发送一个带散列标识码的HTTP请求
KaZaA小技巧
- 请求排队
- 限制并行上载的数量
- 确保每个被传输的文件从上载节点接收一定量的带宽
- 激励优先权
- 鼓励用户上载文件
- 加强系统的扩展性
- 并行下载
- 从多个对等方下载同一个文件的不同部分
- HTTP的字节范围首部
- 更快地检索一个文件
- 从多个对等方下载同一个文件的不同部分
KaZaA是一款P2P文件共享软件,是早期P2P文件共享软件中的一种。KaZaA采用了类似Gnutella的分布式查询和资源发现机制,用户可以通过KaZaA客户端搜索和下载其他用户共享的文件。
KaZaA的工作原理如下:
用户加入网络:用户通过KaZaA客户端加入KaZaA网络,并与其他用户建立连接。
分布式查询:用户可以通过KaZaA客户端向其他用户发送查询请求,搜索其他用户共享的文件。查询请求会在KaZaA网络中分布式传播和扩散,直到找到匹配的文件资源。
文件下载:用户可以通过KaZaA客户端从其他用户处下载文件,并在自己的计算机上保存。KaZaA客户端支持多线程下载,用户可以从多个上传者处同时下载文件块,以提高下载速度和效率。
KaZaA曾经是非常受欢迎的P2P文件共享软件之一,但是由于它的版权侵犯和恶意软件传播等问题,已经逐渐退出了市场。目前,类似KaZaA的P2P文件共享软件依然存在,但是它们面临着各种各样的安全和法律问题,需要注意相应的风险管理和安全措施。
总之,KaZaA是一款早期的P2P文件共享软件,采用了类似Gnutella的分布式查询和资源发现机制,可以实现用户之间的文件共享和传输。
Distributed Hash Table(DHT)
- 哈希表
- DHT方案
- 环形DHT 以及覆盖网络
- Peer波动
CDN
视频流化服务和CDN
视频流化服务和CDN:上下文
- 视频流量:占据着互联网大部分的带宽
- Netfix,YouTube:占据37%,16%的ISP下行流量
- ~1B YouTube 用户:占据37%,16%的ISP下行流量
- 挑战:规模性-如何服务者 ~1B用户?
- 单个超级服务器无法提供服务(为什么)
- 挑战:异构性
- 不同用户拥有不同的能力(例如:有线接入和移动用户:带宽丰富和受限用户)
- 解决方案:分布式的,应用层面的基础设施
多媒体:视频
- 视频:固定速度显示的图像序列
- e. g. 24 images/sec
- 网络视频特点:
- 高码率: >10x于音频,高的网络带宽需求
- 可以被压缩
- 90%以上的网络流量是视频
- 数字化图像:像素的阵列
- 每个像素被若干bits表示
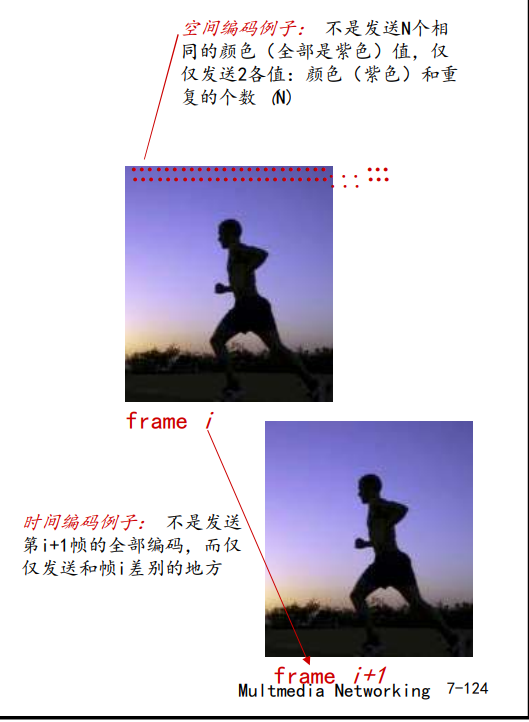
- 编码:使用图像内和图像间的冗余来降低编码的比特数
- 空间冗余(图像内)
- 时间冗余(相邻的图像间)
- CBR(constant bit rate):以固定速率编码
- VBR(variable bit rate):视频编码速率随时间的变化而变化
- 例子:
- MPEG 1 (CD-ROM) 1.5 Mbps
- MPEG2(DVD) 3-6Mbps
- MPEG4(often used in Internet,< 1Mpbs)
存储视频的流化服务:
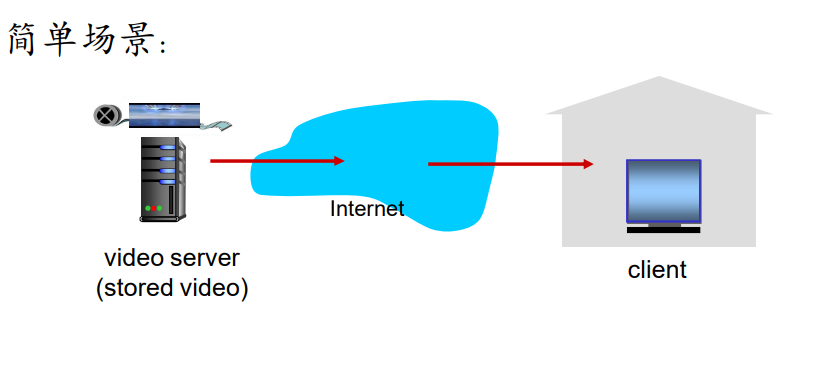
多媒体流化服务:DASH
DASH允许客户使用不同的因特网接入速率流式播放具有不同编码速率的视频。
DASH允许客户自由地在不同的质量等级之间切换。
DASH:Dynamic,Adaptive Streaming over HTTP
服务器:
将视频文件分割成多个块
每个块独立存储,编码于不同码率(8-10种)
告示文件(manifest file):提供不同块的URL
客户端:
- 先获取告示文件
- 周期性地测量服务器到客户端的带宽
- 查询告示文件,在一个时刻请求一个块,HTTP头部指定字节范围
- 如果带宽足够,选择最大码率的视频块
- 会话中的不同时刻,可以切换请求不同的编码块(取决于当时的可用带宽)
流式多媒体技术3:DASH
- “智能” 客户端:客户端自适应决定
- 什么时候去请求块(不至于缓存挨饿,或者溢出)
- 请求什么编码速率的视频块(当带宽够用时,请求高质量的视频块)
- 哪里去请求块(可以向离自己进的服务器发送URL,或者向高可用带宽的服务器请求)
Content Distribution Networks (CDN)
挑战:服务器如何通过网络向上百万用户同时流化视频内容(上百万视频内容)
选项1:单个的、大的超级服务中心 “megaserver”
- 服务器到客户端路径上跳数较多,瓶颈链路的带宽小导致停顿
- “二八规律” 决定了网络同时充斥着同一个视频的多个拷贝,效率低(付费高、带宽浪费、效果差)
- 单点故障点,性能瓶颈
- 周边网络的拥塞
评述:相当简单,但是这个方法不可扩展
选项2:通过CDN,全网部署缓存节点,存储服务内容,就近为用户提供服务,提高用户体验
- enter deep:将CDN服务器深入到许多接入网
- 更接近用户,数量多,离用户近,管理困难
- Akamai,1700个位置
- bring home:部署在少数(10个左右)关键位置,如将服务器簇安装于POP附近
- 采用租用线路将服务器簇连接起来
- Limelight
- enter deep:将CDN服务器深入到许多接入网
CDN管理分部在多个地理位置上的服务器,在它的服务器中存储视频的副本,并且所有视图将每个用户请求定向到一个将提供最好的用户体验的CDN位置。
Content Distribution Networks(CDNs)
- CDN:在CDN节点中存储内容的多个拷贝
- e. g. Netflix stores copies of MadMen
- 用户从CDN中请求内容
- 重定向到最近的拷贝,请求内容
- 如果网络路径拥塞,可能选择不同的拷贝
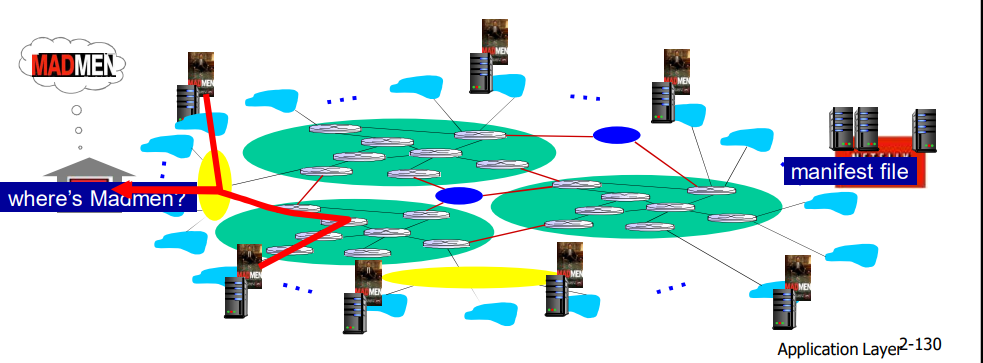

OTT 挑战:在拥塞的互联网上复制内容
- 从哪个CDN节点中获取内容?
- 用户在网络拥塞时的行为?
- 在哪些CDN节点中存储什么内容?
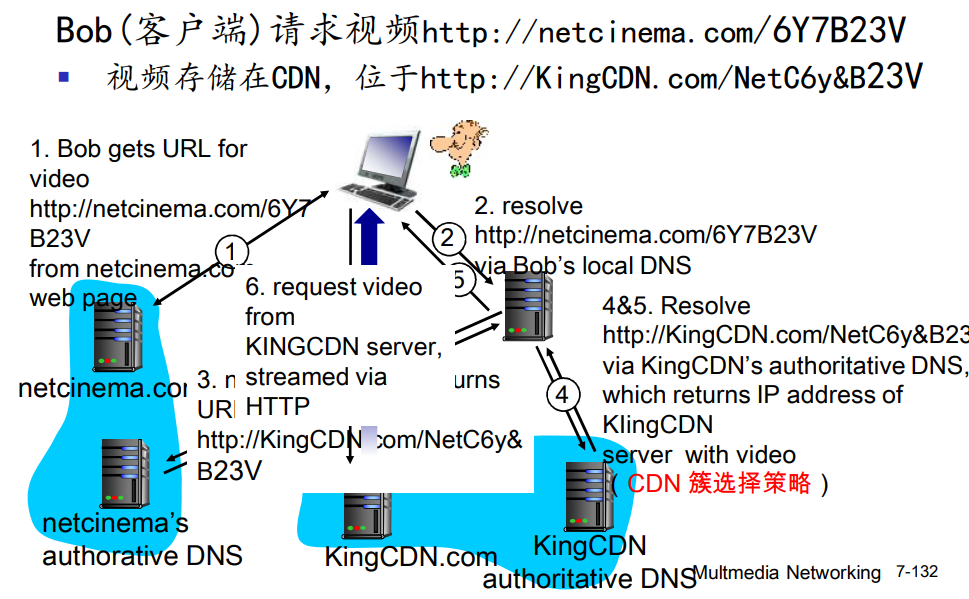
CDN:“简单” 内容访问场景
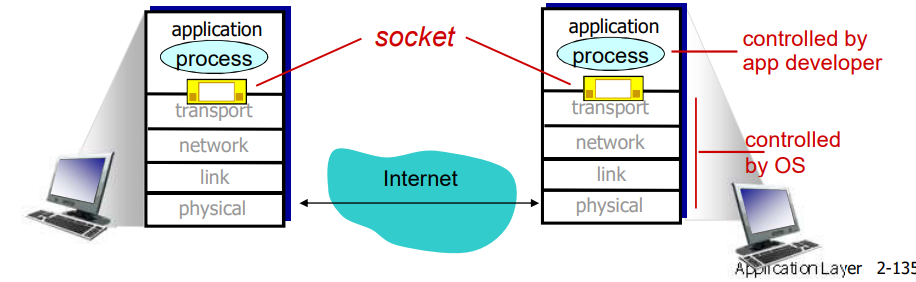
TCP套接字编程
Socket编程
应用进程使用传输层提供的服务才能够交换报文,实现应用协议,实现应用
- TCP/IP:应用进程使用 Socket API 访问传输服务
- 地点:界面上的SAP(Socket) 方式:Socket API
目标:学习如何构建能借助sockets进行通信的 C/S 应用程序
socket:分布式应用进程之间的门,传输层协议提供的端到端服务接口
2种传输层服务的socket类型:
- TCP:可靠的、字节流的服务
- UDP:不可靠(数据UDP数据报)服务
TCP套接字编程
TCP套接字编程
套接字:应用进程与端到端传输协议(TCP或UDP)之间的门户
TCP服务:从一个进程向另一个进程可靠地传输字节流
服务器首先运行,等待连接建立
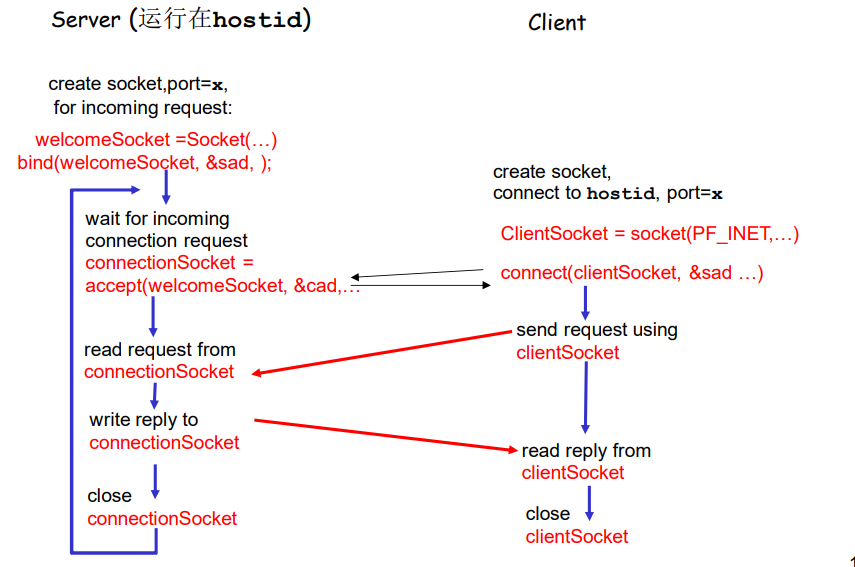
1:服务器进程必须先处于运行状态
- 创建欢迎socket
- 和本地端口捆绑
- 在欢迎socket上阻塞式等待接收用户的连接
客户端主动和服务器建立连接:
2.创建客户端本地套接字(**隐式捆绑 **到本地port)
- 指定服务器进程的IP地址和端口号,与服务器进程连接
在创建该TCP连接时,我们将其与客户套接字地址(IP地址和端口号)和服务器套接字地址(IP地址和端口号)关联起来。
3.当与客户端连接请求的到来时
- 服务器接收来自用户端的请求,解除阻塞式等待,返回一个新的socket(与欢迎socket不一样),与客户端通信
- 允许服务器与多个客户端通信
- 使用源IP和源端口号来区分不同的客户端
从应用程序的角度
TCP 在客户端与服务器进程之间提供了可靠的、字节流(管道)服务
4.连接API调用有效时,客户端P与服务器建立了TCP连接
使用创建的TCP连接,当一侧要向另一侧发送数据时,它只需讲过其套接字将数据丢进TCP连接
C/S socket交互:TCP
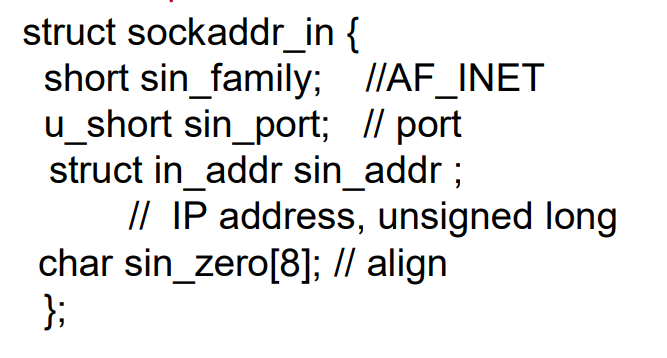
数据结构 sockaddr_in
IP地址和port捆绑关系的数据结构(标示进程的端节点)
数据结构 hostent
域名和IP地址的数据结构

例子:
C客户端(TCP)

C服务器

UDP套接字编程
UDP Socket编程
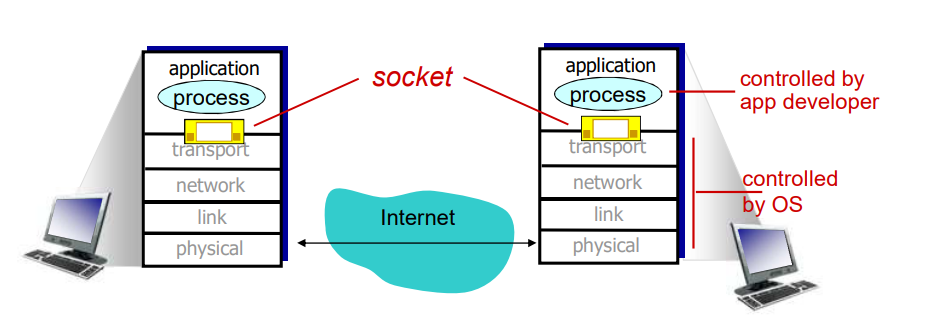
应用程序开发者在套接字的应用层一侧可以控制所有东西,然而,它几乎无法控制运输层一侧。
UDP:在客户端和服务器之间没有连接
- 没有握手
- 发送端在每一个报文中明确地指定目标的IP地址和端口号
- 服务器必须从收到的分组中提取出发送端的IP地址和端口号
将源地址附在分组之上通常并不是由UDP应用程序代码所为,而是由底层操作系统自动完成的。
从 进程角度看 UDP 服务:
UDP 为 客户端和服务器端提供 不可靠的 字节组的传送服务
UDP: 传送的数据可能 乱序,也可能丢失
C/S socket 交互:udp 

小结
- 应用程序体系结构
- 客户-服务器
- P2P
- 混合
- 应用程序需要的服务品质描述
- 可靠性
- 带宽
- 延时
- 安全
- Internet 传输层服务模式
- 可靠的、面向连接的服务:TCP
- 不可靠的数据报:UDP
- 流行的应用层协议:
- HTTP
- FTP
- SMTP、POP、IMAP
- DNS
- Socket编程
更重要的:学习协议的知识
- 应用层协议报文类型:请求/响应报文:
- 客户端请求信息或服务
- 服务器以数据、状态码进行响应
- 报文格式:
- 首部:关于数据信息的字段
- 数据:被交换的信息
- 控制报文 vs 数据报文
- 带内、带外
- 集中式 vs 分散式
- 无状态 vs 维护状态
- 可靠的 vs 不可靠的报文传输
- 在网络边缘处理复杂性
一个协议定义了在两个或多个通信实体之间交换报文的格式和次序、以及就一条报文传输和接收或其他事件采取的动作
传输层
运输层位于 应用层和网络层之间,是分层的网络体系结构的重要部分。 该层为 运行在不同主机上的应用进程提供直接的 通信服务起着至关重要的作用。
“关注运输是什么,他如何工作,为什么这么做”
目标:
- 理解传输层的工作原理
- 多路复用/解复用
- 可靠数据传输
- 流量控制
- 拥塞控制
- 学习 Internet 的传输层协议
- UDP :无连接传输
- TCP :面向连接的 可靠性传输
- TCP 的拥塞控制
概述和传输层服务
运输层协议为运行在不同主机上的应用进程之间提供了逻辑通信功能。
传输服务器和协议
为运行在不同主机上的应用进程提供逻辑通信
传输协议运行在端系统(而不是在路由器中实现的)
发送方:将应用层的报文分成报文段,然后传递给网络层
实现的方法(可能)是将应用报文划分为较小的块,并为每块加上一个运输层首部以生成运输层报文段,然后,在发送端系统中,运输层将这些报文段传递给网络层,网络层将其封装成网络层分组(即数据报)向目的地发送。
接收方:将报文段重组成报文,然后传递给应用层
有多个传输层协议可供应用选择
- Internet:TCP和UDP
网络路由器仅作用于该数据报的网络层字段;即它们不检查封装在该数据报的运输层报文段的字段。在接收端,网络层从数据报中提取运输层报文段,并将改报文段向上交给运输层。运输层在处理接收到的报文段,使该报文段中的数据为接收应用进程使用。
传输层 vs 网络层
前面讲过,在协议栈中,运输层刚好位于网络层之上。网络层提供了主机之间的逻辑通信,而运输层为运行在不同主机上的进程之间提供了逻辑通信。
- 网络层服务:主机之间的逻辑通信
- 传输层服务:进程间的逻辑通信
- 依赖于网络层的服务
- 延时、带宽
- 并对网络层的服务进行增强
- 数据丢失、顺序混乱、加密
- 依赖于网络层的服务

有些服务是可以加强的:不可靠 —> 可靠:安全,但有些服务是不可以被加强的:带宽,延迟
运输层协议只工作在端系统中,在端系统中,运输层协议将来自应用进程的报文移动到网络边缘(即网络层)。中间路由器既不处理也不识别运输层加在应用层报文的任何信息。
运输协议能够提供的服务常常受制于底层网络层协议的服务模型。如果网络层协议无法为主机之间发送的运输层报文段提供时延或带宽保证的话,运输层协议也就无法为进程之间发送的应用程序报文提供时延或带宽保证。
然而,即使底层网络协议不能在网络层提供相应的服务,运输层协议也能提供某些服务。例如,即使底层网络协议是不可靠的,也就是说网络层协议会使分组丢失、篡改、冗余,运输协议也能为应用程序提供可靠的数据传输服务。另一个例子是,即使网络层不能保证运输层报文段的机密性,运输协议也能使用加密来确保应用程序报文不被入侵者读取。
Internet传输层协议
在对UDP和TCP进行简要介绍之前,简单介绍一下因特网的网络层。因特网网络层协议有一个名字叫IP,即网际协议。IP为主机之间提供了逻辑通信。IP的服务模型是尽力而为交付服务(best-effort delivery service)。这意味着IP尽它“最大的努力”在通信的主机之间交付报文段,但它并不做任何确保。特别是,它不确保报文段的交付,不保证报文段的按序交付,不保证报文段中数据的完整性。由于这些原因,IP被称为不可靠服务(unreliable service)。在此还要指出的是,每台主机至少有一个网络层地址,即所谓的IP地址。在这一章中,只需要记住每台主机都有一个 IP 地址 即可。
- 可靠的、保序的传输:TCP(传输控制协议)
- 多路复用、解复用
- 拥塞控制
- 流量控制
- 建立连接
- 不可靠、不保序的传输:UDP(用户数据报协议)
- 多路复用、解复用
- 没有尽力而为的IP服务添加更多的其他额外服务
- 都不提供的服务:
- 延时保证
- 带宽保证
在对 IP 有了初步的了解之后。总结一下 TCP 和 UDP 所提供的 服务模型。 UDP 和 TCP 最基本的责任是 将两个端系统间 IP 的交付服务扩展到运行在端系统上的两个进程之间的交互服务。将主机间交付扩展到进程之间的交付被称为 运输层的多路复用 与 多路分解
多路复用与解复用
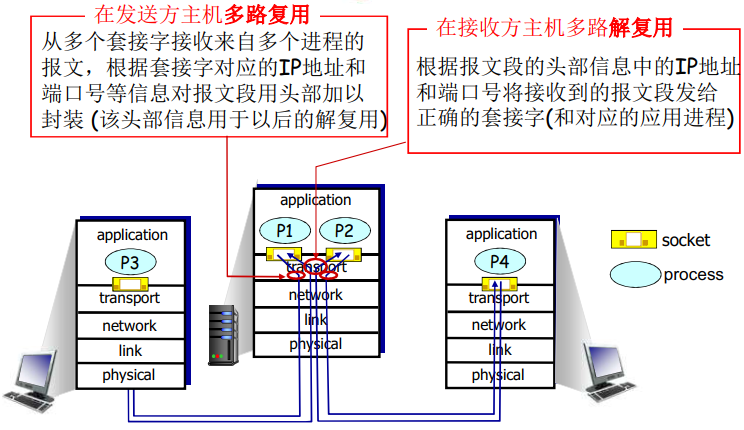
运输层的多路复用与多路分解:
将由网络层提供的主机到主机交付服务延伸到为运行在主机上的应用程序提供进程到进程的交付服务。
多路解复用工作原理
- 解复用作用:TCP或者UDP实体采用哪些信息,将报文段的数据部分交给正确的socket,从而交给正确的进程。
- 主机收到IP数据报
- 每个数据报有源IP地址和目标地址
- 每个数据报承载一个传输层报文段
- 每个报文段有一个源端口号和目标端口号(特定应用有著名的端口号)
- 主机联合使用IP地址和端口号将报文段发送给合适的套接字
现在应该清楚运输层是怎样能够实现分解服务的了:在主机上的每个套接字能够分一个端口号,当报文段到达主机时,运输层检查报文段中的目的端口号,并将其定向到相应的套接字。然后报文段中的数据通过套接字进入其所连接的进程。如我们将看到的那样,UDP大体上是这样做的。然而,也将如我们所见,TCP中的多路复用与多路分解更为复杂。
无连接(UDP)多路解复用
创建套接字:

serverSocket 和 sad 指定的端口号捆绑
没有 bind,clientSocket 和 os 为之分配的某个端口号捆绑(客户端使用什么端口号无所谓,客户端主动找服务器)
在接收端,UDP套接字用二元组标识(目标IP地址、目标端口号)
当主机收到UDP报文段:
- 检查报文段的目标端口号
- 用该端口号将报文段定位给套接字
如果两个不同源IP地址/源端口号的数据报,但是有相同的目标IP地址和端口号,则被定位到相同的socket套接字
例子
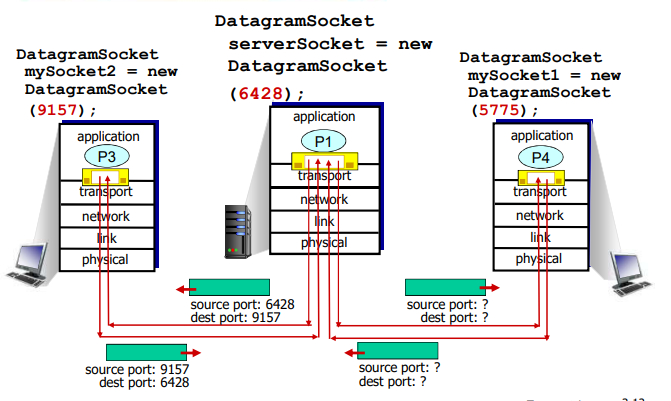
假定在主机A中的一个进程具有UDP端口19157,它要发送一个应用程序数据块给位于主机B中的另一个进程,该进程具有UDP端口46428.主机A中的运输层创建一个运输层报文段,其中包括 应用程序数据、源端口号(19157)、目的端口号(46428)和两个其他值。然后,运输层将得到的报文段传递到网络层。网络层将该报文段封装到一个IP数据报中,并尽力而为地将报文段交付给接收主机。如果该报文段到达接收主机B,接收主机运输层就检查该报文段中的目的端口号(46428)并将该报文段交付给端口号46428所标识的套接字。
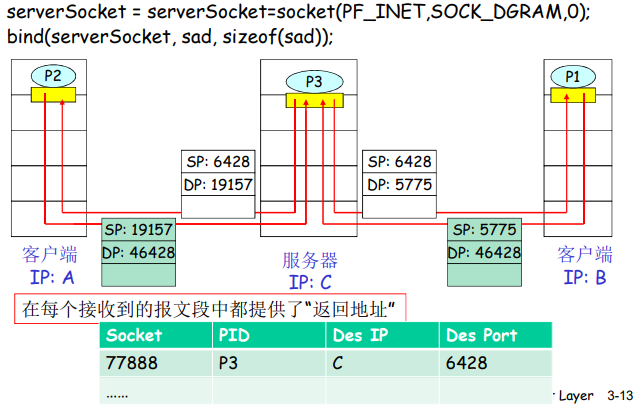
面向连接(TCP)的多路复用
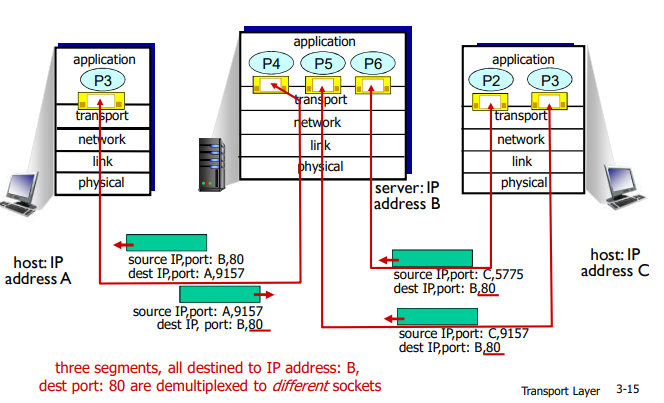
当一个TCP报文段从网络到达一台主机时,该主机使用全部4个值来将报文段定向(分解)到相应的套接字。
特别与UDP不同的是,两个具有不同源IP地址或源端口号的到达TCP报文段将被定向到两个不同的套接字,除非TCP报文段携带了初始创建连接的请求。
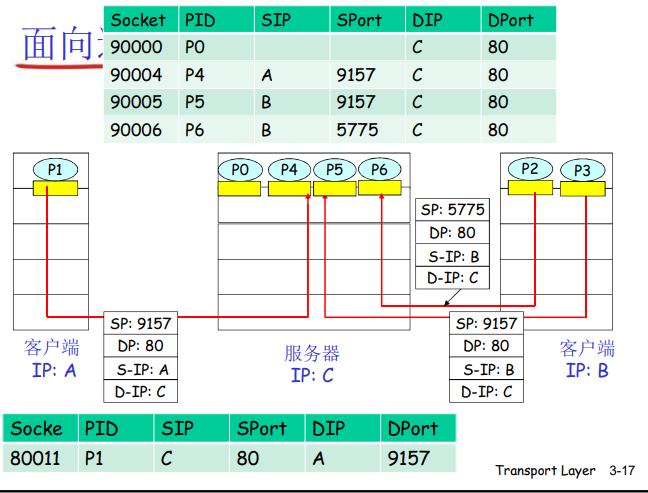
面向连接的解复用:例子
- TCP套接字:四元组本地标识:
- 源IP地址
- 源端口号
- 目的IP地址
- 目的端口号
- 解复用:接收主机用这四个值来将数据报定位到合适的套接字
- 服务器能够在一个TCP端口上同时支持多个TCP套接字:
- 每个套接字由其四元组标识(有不同的源IP和源port(端口号)),当一个TCP报文到达主机时,所有4个字段(源IP地址,源端口,目的IP地址,目的端口)被用来将报文段定向(分解)到响应的套接字。
- Web服务器对每个连接客户端有不同的套接字
- 非持久对每个请求有不同的套接字
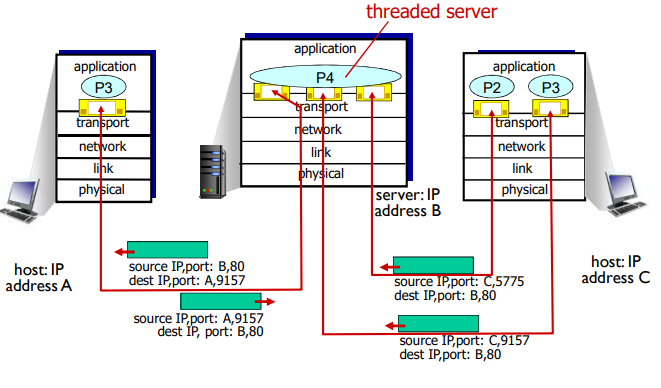
服务器主机可以支持很多并行的TCP套接字,每个套接字与一个进程相联系,并由其四元组来标识每个套接字。当一个TCP报文段到达主机时,所有4个字段(源IP地址,源端口,目的IP地址,目的端口)被用来将报文段定向(分解)到相应的套接字。
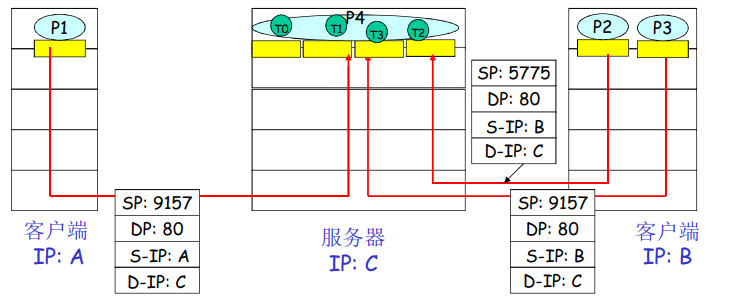
面向连接的多路复用:多线程Web Server
- 一个进程下面可能有多个线程:由多个线程分别为客户提供服务
- 在这个场景下,还是根据 4 元组决定将报文段内容 定向 到同一个进程下的不同线程
- 解复用到不同线程
事实上,当今的高性能Web服务器通常只使用一个进程,但是为每个新的客户连接创建一个具有新连接套接字的新线程。对于这样一台服务器,在任意给定的时间内都可能有(具有不同标识的)许多连接套接字连接到相同的进程。
无连接传输:UDP
由 [RFC768] 定义的 UDP 只是做了运输协议能够做的最少工作。除了复用/分解功能及少量的差错检测外,它几乎没有对IP增加别的东西。实际上,如果应用程序开发人员选择UDP而不是TCP,则该应用程序差不多就是直接与IP打交道。UDP从应用进程得到数据,附加上用于多路复用/分解服务的源和目的端口号字段,以及两个其他的小字段然后将形成的报文段交给网络层。网络层将该运输层报文段封装到一个IP数据报中,然后尽力而为地尝试将此报文段交付给接收主机。如果该报文段到达接收主机,UDP使用目的端口号将报文段中的数据交付给正确的应用进程。值得注意的是,使用UDP时,在发送报文段之前,发送方和接收方的运输层实体之间没有握手。正因为如此,UDP被称为是无连接的。
UDP:用户数据报协议
- “no frills”,”bare bones” Internet传输协议
- “尽力而为” 的服务,报文段可能
- 丢失
- 送到应用进程的报文段乱序
- 无连接:
- UDP发送端和接收端之间没有握手
- 每个UDP报文段都被独立地处理
- UDP被用于:
- 流媒体(丢失不敏感,速率敏感、应用可控制传输速率)
- DNS
- SNMP
- 在UDP上可行可靠传输:
- 在应用层增加可靠性
- 应用特定的差错恢复

应用层数据占用UDP报文段的数据字段。UDP首部只有4个字段,每个字段由两个字节组成。
因为数据字段的长度在一个UDP段中不同于在另一个段中,故需要一个明确的长度。接收方使用检验和来检查在该报文段中是否出现了差错。实际上,计算检验和时,除了UDP报文段以外还包括了IP首部的一些字段。
为什么要有UDP?
不建立连接(会增加延时)
简单:在发送端和接收端没有连接状态
报文段的头部很小(开销小)
无拥塞控制和流量控制:UDP可以尽可能快的发送报文段
- 应用 -> 传输的速率 = 主机 -> 网络的速率
UDP校验和
目标:检测在被传输报文段中的差错(如比特反转)
UDP检验和提供了差错检测功能。这就是说,检验和用于确定当UDP报文段从源到达目的地移动时,其中的比特是否发生了改变。
发送方:
- 将报文段的内容视为16比特的整数
- 校验和:报文段的加法和(1的补运算)
- 发送方将校验和放在UDP的校验和字段
接收方:
- 计算接收到的报文段的校验和
- 检查计算出的校验和字段的内容是否相等:
- 不相等 —> 检测到差错
- 相等 —> 没有检测到差错,但也许还是有差错,残存错误
你可能想知道为什么UDP首先提供了检验和,就像许多链路层协议(包括流行的以太网协议)也提供了差错检测那样。其原因是不能保证源和目的之间的所有链路都提供差错检测;这就是说,也许这些链路中的一条可能使用没有差错检测的协议。此外,即使报文段经链路正确地传输,当报文段存储在某台路由器的内存中时,也可能引入比特差错。在既无法确保逐链路的可靠性,又无法确保内存中的差错检测的情况下,如果端到端数据传输服务要提供差错检测,UDP就必须在端到端基础上在运输层提供差错检测。这是一个在系统设计中被称颂的 端到端原则 (end-end principle)的例子[Saltzer1984],该原则表述为因为某种功能(在此时为差错检测)必须基于端到端实现:“与在较高级别提供这些功能的代价相比,在较低级别上设置的功能可能是冗余的或几乎没有价值的。”
Internet校验和的例子
- 注意:当数字相加时,在最高位的进位要回卷,在加到结果上
例子:两个16比特的整数相加

- 目标端:校验范围 + 校验和 = 1111111111111111 通过校验
- 否则没有通过校验
- 注:求和时,必须将进位回卷到结果上
因为 假定 IP 是可以 运行 在 任何第二层协议之上的,运输层 提供 差错检测作为一种保险措施时非常有用的。虽然 UDP 提供 差错检测,但他对 差错恢复无能为力。UDP 的某种 实现 只是丢弃了 受损的报文段;其他 实现则是将受损的 报文段交给应用程序并且 给出警告
UDP是一种无连接的传输协议,它在计算机网络中被广泛使用。
在UDP中,数据被分成小的数据包并通过网络进行传输。每个数据包包含源和目标端口号,以及数据本身。与TCP不同,UDP不需要在发送数据之前建立连接。因此,UDP的传输速度比TCP更快,但可靠性较差。
UDP的优势在于它能够快速地传输数据,而且需要的网络带宽较少。因此,它通常用于实时应用程序,例如音频和视频流。此外,UDP还可以用于广播和多播应用程序,使得多个接收方可以同时接收数据。
但是,UDP的不可靠性也是它的缺点之一。因为UDP不提供数据包重传和数据包排序等功能,因此在传输过程中可能会丢失一些数据包或将它们发送到错误的目的地。因此,在使用UDP时,我们需要考虑如何处理这些问题。
总之,UDP是一种快速、简单的无连接传输协议,可用于实时应用程序和广播多播应用程序。但是,由于它的不可靠性,我们需要考虑如何处理数据包丢失和乱序等问题。
可靠数据传输的原理
可靠数据传输(reliable data transfer protocol)
可靠数据传输(rdt)的原理
- rdt在应用层、传输层和数据链路层都很重要
- 是网络 Top 10 问题之一
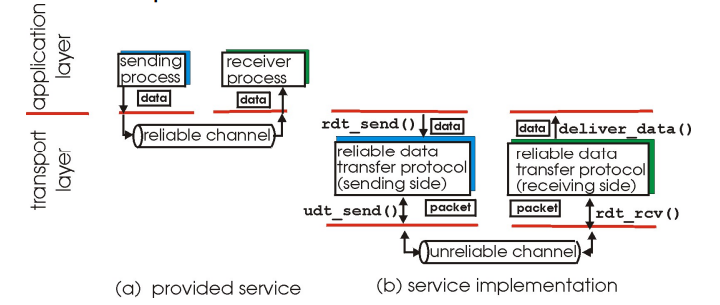
- 信道的不可靠特点决定了可靠数据传输协议(rdt)的复杂性
为上层实体提供的服务抽象是:数据可以通过一条可靠的信道进行传输。借助于可靠信道,传输数据比特就不会受到损坏(由0变为1,或者相反)或丢失,而且所有数据都是按照其发送顺序进行交付。实现这种服务抽象是可靠数据传输协议的责任。
可靠数据传输:问题描述
我们将:
- 渐增式地开发可靠数据传输协议(rdt)的发送方和接收方
- 只考虑单向数据传输
- 但控制信息是双向流动的!
- 双向的数据传输问题实际上是 2 个单向数据传输问题的综合
- 使用有限状态机(FSM)来描述发送方和接收方
状态:在该状态时,下一个状态只由下一个事件唯一确定

FSM,全称为有限状态机,是一种表示有限状态和转移动作的数学模型。在计算机科学中,FSM通常用于描述计算机程序的行为,以及硬件系统的设计。
在FSM中,系统的行为被描述为一组状态,以及状态之间的转移动作。系统可以根据输入或事件,从一个状态转移到另一个状态。这种状态转移可以按照预定义的规则进行,或者根据某些条件进行。
FSM的优势在于它可以帮助我们更好地理解系统的行为,并帮助我们设计和开发计算机程序或硬件系统。FSM可以帮助我们定义系统的状态和转移动作,以及相应的输入和输出。这样可以更好地管理程序的复杂性,并确保系统的正确性和可靠性。
在计算机科学中,FSM被广泛应用于各种领域,例如编译器设计、协议分析、硬件系统设计和计算机游戏设计等。在编译器设计中,FSM可以帮助我们分析程序的语法结构,并生成相应的编译器代码。在协议分析中,FSM可以帮助我们识别和分析网络协议中的状态和转移动作。在硬件系统设计中,FSM可以帮助我们设计和实现自动控制系统。在计算机游戏设计中,FSM可以帮助我们设计和实现游戏中的角色行为和故事情节等。
总之,FSM是一种表示有限状态和转移动作的数学模型,通常用于描述计算机程序的行为和硬件系统的设计。FSM的优势在于它可以帮助我们更好地理解系统的行为,并帮助我们设计和开发计算机程序或硬件系统。
rdt1.0 :在可靠信道上的可靠数据传输
- 下层的信道是完全可靠的
- 没有比特出错
- 没有分组丢失
- 发送方和接收方的 FSM
- 发送方将数据发送到下层信道
- 接收方从下层信道接收数据
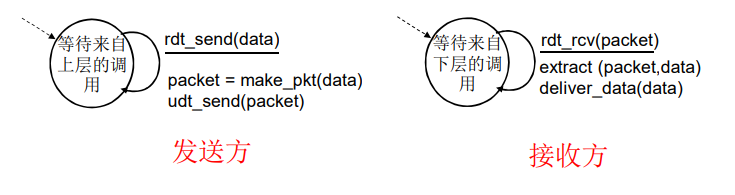
rdt1.0是最简单的可靠数据传输协议,它只考虑了无差错情况下的数据传输。
在rdt1.0中,当发送方要发送数据时,它会直接将数据发送到接收方。接收方收到数据后,会发送一个确认消息给发送方,表示已经接收到了数据。如果发送方没有收到确认消息,则假定数据包已经丢失,并重新发送该数据包。
这种方案比较简单,但是只能够处理无差错情况下的数据传输,无法处理数据包损坏或丢失的情况。因此,在实际应用中,我们需要更加复杂的协议来确保可靠的数据传输。
总之,rdt1.0是最简单的可靠数据传输协议,它只能处理无差错情况下的数据传输。在实际应用中,我们需要更加复杂的协议来确保可靠的数据传输。
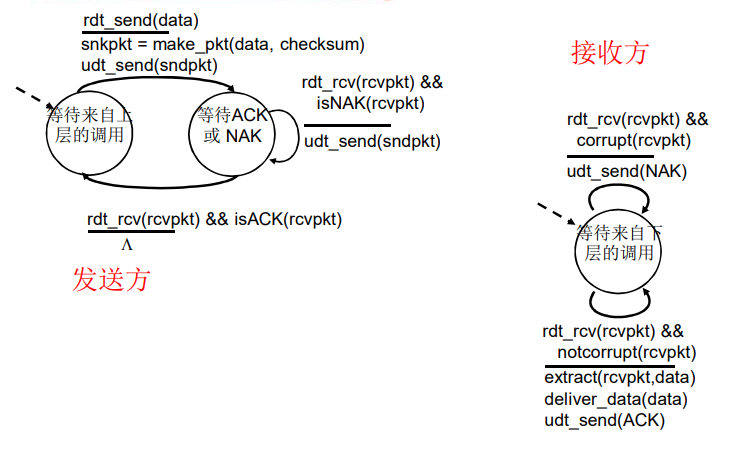
rdt2.0
rdt2.0: 具有比特差错的信道
- 下层信道可能会出错:将分组中的比特翻转
- 用校验和来检测比特差错
- 问题:怎样从差错中恢复:
- 确认(ACK):接收方显示地告诉发送方分组已被正确接收
- 否定确认(NAK):接收方显示地告诉发送方分组发生了差错
- 发送方收到NAK后,发送方重传分组
- rdt2.0 中的新机制:采用差错控制编码进行差错检测
- 发送方差错控制编码、缓存
- 接收方使用编码检错
- 接收方的反馈:控制报文(ACK、NAK):接收方 -> 发送方
- 发送方收到反馈相应的动作
这种口述报文协议使用了肯定确认与否定确认。这些控制报文使得接收方可以让发送方知道哪些内容被正确接收,哪些内容接收有误并因此需要重复。基于这样重传机制的可靠数据传输协议称为 自动重传请求(ARQ(Automatic Repeat reQuest))协议。
ARQ协议需要另外三种协议功能来处理存在比特差错的情况:
- 差错检测
- 接收方反馈
- 重传
FSM描述
没有差错时的操作
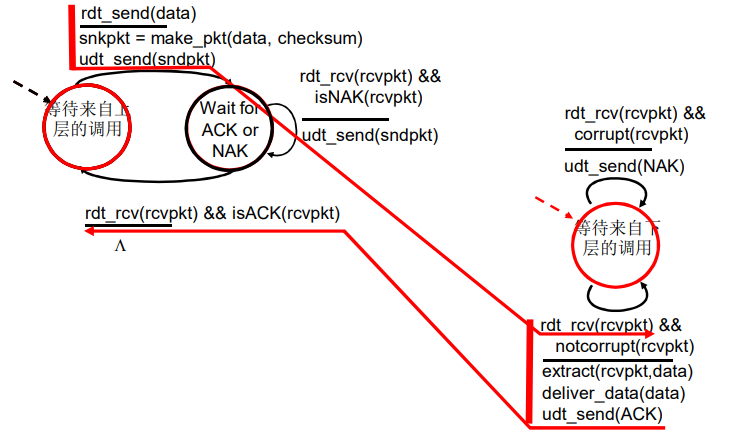
有差错时
当发送方处于等待ACK或NAK的状态时,它不能从上层获得更多的数据;这就是说,rdt_send() 时间不可能出现;仅当接收到 ACK 并离开该状态时才能发生这样的事件。因此,发送方将不会发送一块新数据,除非发送方确信接收方已正确接收当前分组。由于这种行为,rdt2.0这样的协议被称为 停等(stop-and-wait)协议。
rdt2.1 :处理出错的ACK/NAK
rdt2.0 的致命缺陷! -> rdt 2.1
如果ACK/NAK出错?
发送方不知道接收方发生了什么事情!
发送方如何做?
- 重传?可能重复
- 不重传?可能死锁(或出错)
需要引入新的机制
- 序号
处理重复:
发送方在每个分组中加入序号
如果ACK/NAK出错,发送方重传当前分组
接收方丢弃(不发给上层)重复分组
停等协议
发送方发送一个分组,然后等待接收方的应答
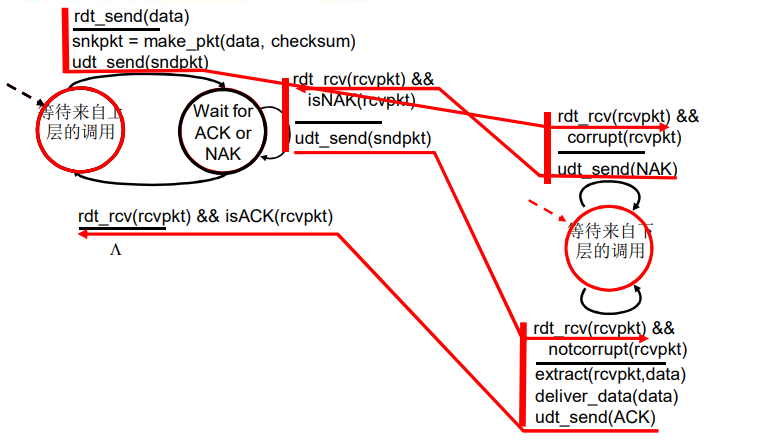
rdt2.1 : 发送方处理出错的ACK/NAK
rdt2.1 :接收方处理出错的ACK/NAK
rdt2.1 :讨论
发送方:
- 在分组中加入序列号,接收方只需要检查序列号即可确定收到的分组是否为重传。
- 两个序列号(0,1)就足够了
- 一次只发送一个未经确认的分组
- 必须检测ACK/NAK是否出错(需要EDC)
- 状态数变成了两倍
- 必须记住当前分组的序列号为 0 还是 1
接收方:
- 必须检测接收到的分组是否是重复的
- 状态会知识希望接收到的分组的序号为0还是1
- 注意:接收方并不知道发送方是否正确收到了其 ACK/NAK
- 没有安排确认的确认
rdt2.1的运行
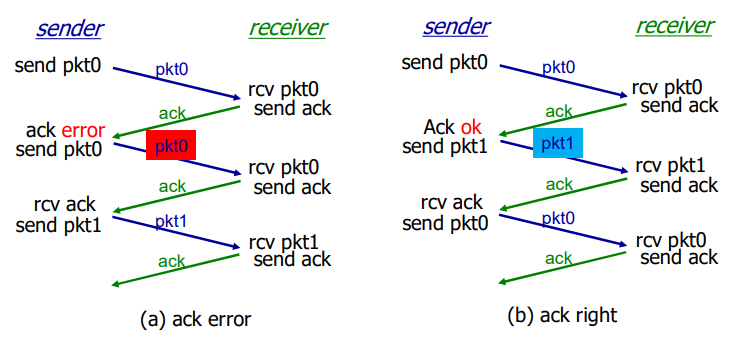
接收方不知道它最后发送的ACK/NAK是否被正确地收到
- 发送方不对收到的 ACK/NAK 给确认,没有所谓的确认的确认;
- 接收方发送 ACK,如果后面接收方收到的是:
- 老分组 p0?则 ACK 错误
- 下一个分组?P1,ACK正确
如果不发送NAK,只是对上次正确接收的分组发送一个 ACK,我们也能实现与NAK医用的效果。发送方接收到对同一个分组的两个ACK[即 接收冗余ACK]后,就知道接收方没有正确接收到跟在被确认两次的分组后面的分组。
rdt2.1是一种可靠数据传输协议,它可以处理数据包丢失和损坏的情况。
在rdt2.1中,发送方将每个数据包都增加一个序号,以便接收方可以检测丢失的数据包。发送方还会计算每个数据包的校验和并将其发送给接收方,以便接收方可以检测数据包是否损坏。当接收方收到一个数据包时,它会发送一个确认消息给发送方,表示已成功接收该数据包。如果接收方没有收到数据包,则发送NAK消息给发送方,请求重传该数据包。如果发送方收到NAK消息,则重新发送相应的数据包。
rdt2.1的优点在于它可以处理数据包丢失和损坏的情况,从而提高了数据传输的可靠性。但是,rdt2.1仍然存在一些缺点,例如它只能处理单个数据包丢失或损坏的情况,而无法处理多个数据包丢失或损坏的情况。此外,rdt2.1还可能存在死锁和无限重传的问题。
总之,rdt2.1是一种可靠数据传输协议,它可以处理数据包丢失和损坏的情况,从而提高了数据传输的可靠性。但是,它仍然存在一些缺点,需要在实际应用中进行改进和优化。
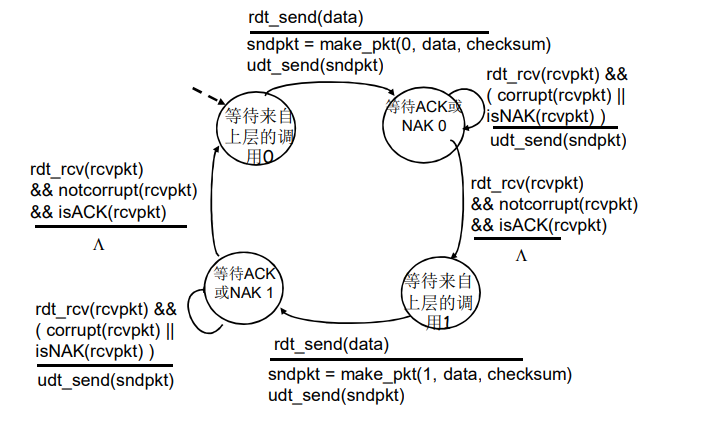
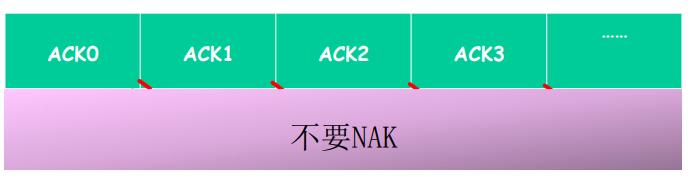
rdt2.2 :无NAK的协议
rdt2.2是在有比特差错信道上实现的一个无NAK的可靠数据传输协议。
rdt2.1和rdt2.2之间的细微变化在于,接收方此时必须包括由一个ACK报文所确认的分组序号,发送方此时必须检查接收到的ACK报文中被确认的分组序号。
rdt2.2 :无NAK的协议
- 功能通rdt2.1,但只使用 ACK(ACK要编号)
- 接收方对最后正确接收的分组发ACK,以替代NAK
- 接收方必须显示地包含被正确接收的序号
- 当收到重复的ACK(如:再次收到ACK0)时,发送方与收到NAK采取相同的动作:重传当前分组
- 为后面的一次发送多个数据单位做一个准备
- 一次能够发送多个
- 每一个的应答都有:ACK、NAK;麻烦
- 使用对前一个数据单位的ACK,代替本数据单位的NAK
- 确认信息减少一半,协议处理简单
NAK free
rdt2.2的运行
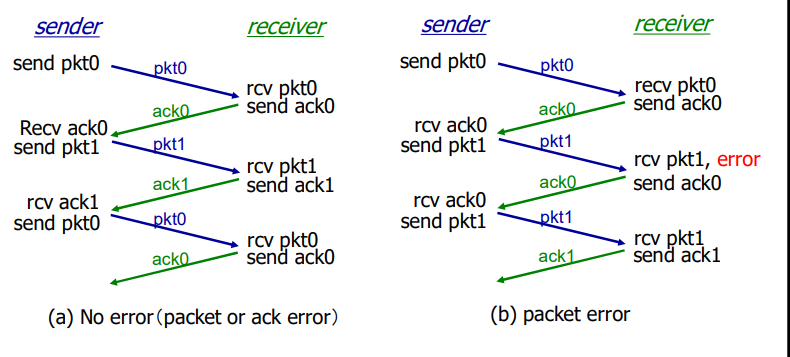
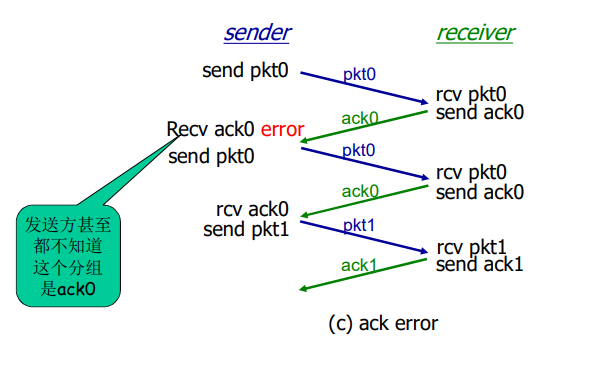
rdt2.2 :发送方和接收方片断
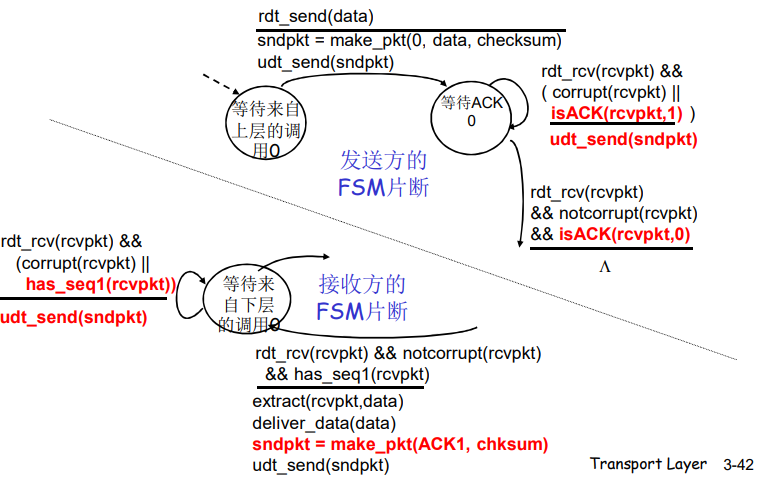
rdt2.0、rdt2.1和rdt2.2都是可靠数据传输协议,它们之间的区别和改进如下:
rdt2.0:只能处理单个数据包丢失的情况,无法处理多个数据包丢失的情况。为了解决这个问题,rdt2.1和rdt2.2引入了选择重传和滑动窗口技术。
rdt2.1:引入了选择重传技术,可以处理多个数据包丢失的情况。选择重传技术允许发送方只重传丢失的数据包,而不是重传整个窗口中的所有数据包。这样可以减少重传的次数,提高传输效率。
rdt2.2:在rdt2.1的基础上引入了滑动窗口技术,可以进一步提高传输效率。滑动窗口技术允许发送方发送多个数据包,并等待接收方发送确认消息。如果接收方没有发送确认消息,则发送方会重传相应的数据包。滑动窗口技术可以在等待确认消息的同时发送多个数据包,从而提高传输效率。
总之,rdt2.0、rdt2.1和rdt2.2都是可靠数据传输协议,它们之间的区别和改进在于处理多个数据包丢失的能力和传输效率的提高。rdt2.0只能处理单个数据包丢失的情况,rdt2.1引入了选择重传技术,可以处理多个数据包丢失的情况,而rdt2.2引入了滑动窗口技术,可以进一步提高传输效率。
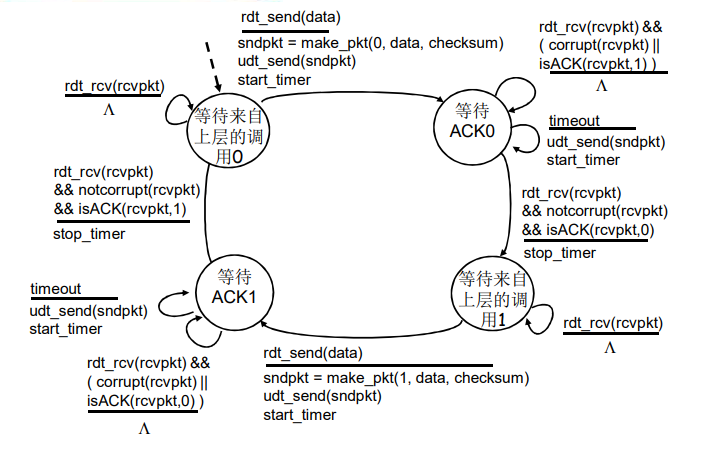
rdt3.0 :具有比特差错和分组丢失的信道
rdt3.0:具有比特差错和分组丢失的信道
新的假设:下层信道可能会丢失分组(数据或ACK)
- 会死锁
- 机制还不够处理这种状况:
- 检验和
- 序列号
- ACK
- 重传
方法:
发送方等待ACK一段合理的时间
(链路层的timeout时间是确定的,传输层timeout时间是适应式的)
- 发送端超时重传:如果到时没有收到ACK -> 重传
- 问题:如果分组(或ACK)只是被延迟了:
- 重传将会导致数据重复,但利用序列号已经可以处理这个问题
- 接收方必须指明被正确接收的序列号
- 需要一个倒计数定时器
rdt3.0 发送方
rdt3.0 的运行
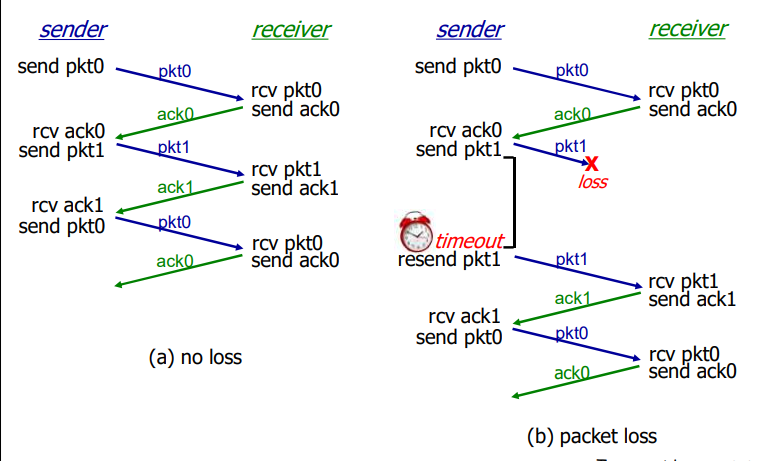
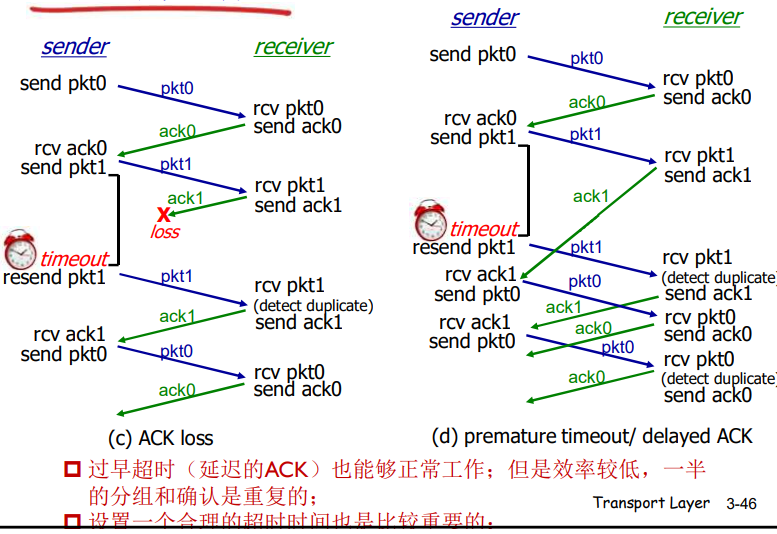
rdt3.0的性能
- rdt3.0可以工作,但链路容量比较大的情况下,性能很差
- 链路容量比较大,一次发一个PDU的不能够充分利用链路的传输能力
例子:

rdt3.0 :停-等操作
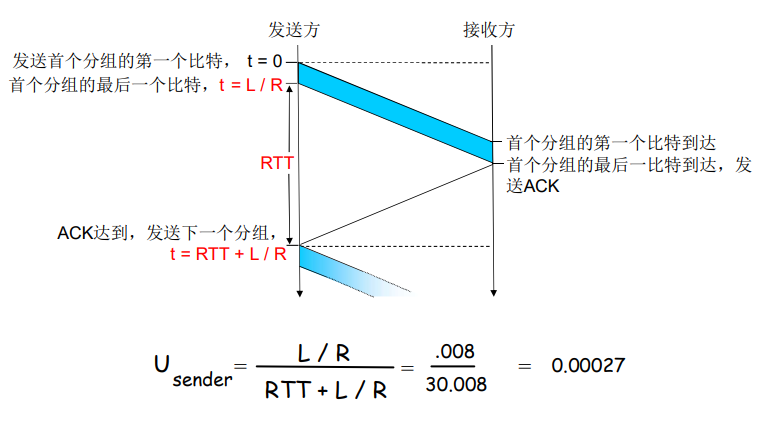
rdt3.0是一种可靠数据传输协议,它可以处理丢失、损坏和重复的数据包。
在rdt3.0中,发送方将每个数据包都增加一个序号,以便接收方可以检测丢失和重复的数据包。发送方还会计算每个数据包的校验和并将其发送给接收方,以便接收方可以检测数据包是否损坏。当接收方收到一个数据包时,它会检查数据包的序号是否正确,如果正确,则发送确认消息给发送方。如果接收方收到重复的数据包,则发送ACK消息表示已经接收过这个数据包。如果接收方收到的数据包不正确,则发送NAK消息给发送方,请求重传该数据包。如果发送方收到ACK消息,则认为该数据包已经成功发送,如果发送方收到NAK消息,则重新发送相应的数据包。
rdt3.0的优点在于它可以处理丢失、损坏和重复的数据包,从而提高了数据传输的可靠性。但是,rdt3.0仍然存在一些缺点,例如它无法处理数据包的乱序到达问题。此外,rdt3.0在处理重传问题时可能会导致网络拥塞和带宽浪费。
总之,rdt3.0是一种可靠数据传输协议,它可以处理丢失、损坏和重复的数据包,从而提高了数据传输的可靠性。但是,它仍然存在一些缺点,需要在实际应用中进行改进和优化。
流水线:提高链路利用率
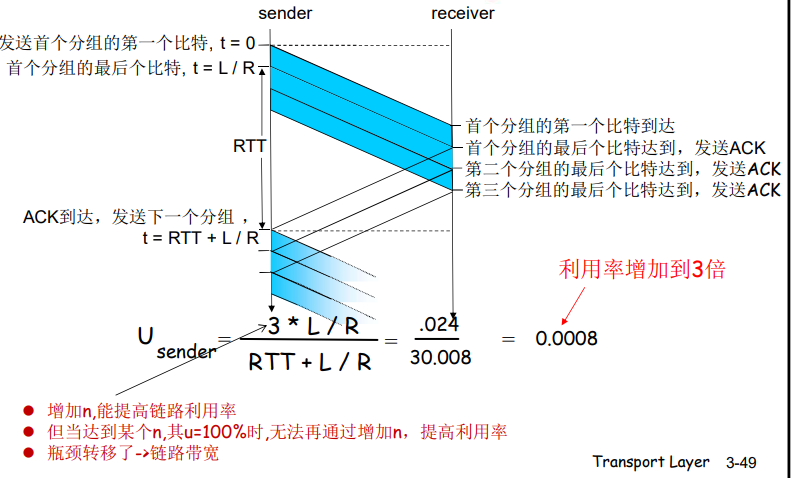
流水线协议
流水线:允许发送方在未得到对方确认的情况下一次发送多个分组
- 必须增加序号的范围:用多个 bit 表示分组的序号
- 在 发送方/接收方 要有缓冲区
- 发送方缓冲:未得到确认,可能需要重传
- 接收方缓存:上层用户取用数据的速率 ≠ 接收到的数据速率:接收到的数据可能乱序,排序交付(可靠)
- 两种通用的流水线协议:回退N步(GBN)(Go-Back-N)和 选择重传(SR)(Selective Repeat, SR)
通用:滑动窗口(slide window)协议
- 发送缓冲区
- 形式:内存中的一个区域,落入缓冲区的分组可以发送
- 功能:用于存放已发送,但是没有得到确认的分组
- 必要性:需要重发时可用
- 发送缓冲区的大小:一次最多可以发送多少个未经确认的分组
- 停止等待协议 = 1
- 流水线协议 > 1,合理的值,不能很大,链路利用率不能超过 100%
- 发送缓冲区中的分组
- 未发送的:落入发送缓冲区的分组,可以连续发送出去
- 已经发送出去的、等待对方确认的分组:发送缓冲区的分组只有得到确认才能删除
发送窗口滑动过程 - 相对表示方法
- 采用相对移动方式表示,分组不动
- 可缓冲范围移动,代表一段可以发送的权利
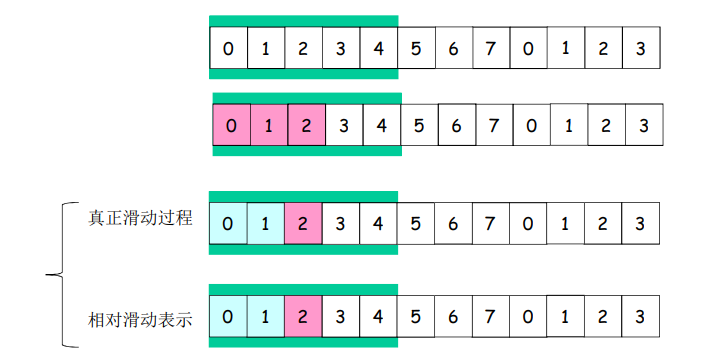
滑动窗口(slide window)协议
- 发送窗口:发送缓冲区内容的一个范围
- 那些已发送但是未经确认分组的序号构成的空间
- 发送窗口的最大值 <= 发送缓冲区的值
- 一开始:没有发送任何一个分组
- 后沿 = 前沿
- 之前为发送窗口的尺寸 = 0
- 每发送一个分组,前沿前移一个单位

发送窗口的移动 -> 前沿移动
- 发送窗口前沿移动的极限:不能够超过发送缓冲区
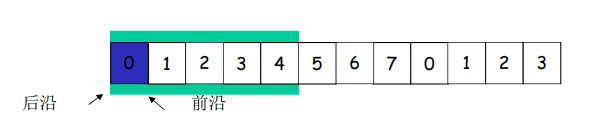
- 发送窗口前沿移动的极限:不能够超过发送缓冲区
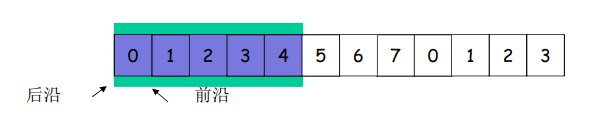
发送窗口的移动 -> 后沿移动
- 发送窗口后沿移动
- 条件:收到老分组的确认
- 结果:发送缓冲区罩住新的分组,来了分组可以发送
- 移动的极限:不能够超过前沿

- 发送窗口后沿移动
- 条件:收到老分组(后沿)的确认
- 结果:发送缓冲区罩住新的分组,来了分组可以发送
- 移动的极限:不能够超过前沿
滑动窗口协议-发送窗口
- 滑动窗口技术
- 发送窗口(sending window)
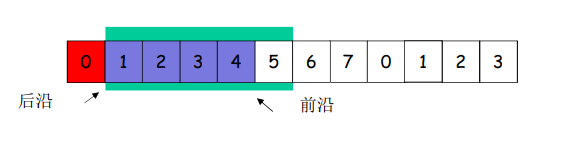
滑动窗口协议-接收窗口
接收窗口(receiving window)= 接收缓冲区
接收窗口用于控制哪些分组可以接收:
- 只有收到的分组序号落入接收窗口内才允许接收
- 若序号在接收窗口之外,则丢弃
接收窗口尺寸 Wr=1 ,则只能顺序接收
接收窗口尺寸 Wr>1 ,则可以乱序接收
- 但提交给上层的分组,要按序
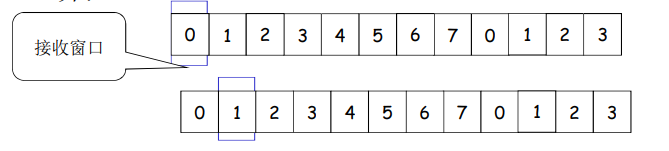
例子:Wr=1,在0的位置;只有0号分组可以接收;
向前滑动一个,罩在1的位置,如果来了第2号分组,则丢弃;
- 接收窗口的滑动和发送确认
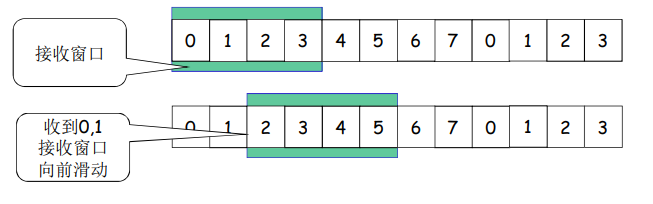
- 滑动:
- 低序号的分组到来,接收窗口移动;
- 高序号分组乱序到,缓存但不交付(因为要实现rdt,不允许失序),不滑动
- 发送确认:
- 接收窗口尺寸 =1,发送连续接收到的最大的分组确认(累计确认)
- 接收窗口尺寸 >1,收到分组,发送那个分组的确认(非累积确认)
- 滑动:
窗口互动
正常情况下的2个窗口互动
- 发送窗口
- 有新的分组落入发送缓冲区范围,发送 -> 前沿滑动
- 来了老的低序号分组的确认 -> 后沿向前滑动 -> 新的分组可以落入发送缓冲区的范围
- 接收窗口
- 收到分组,落入到接收窗口范围内,接收
- 是低序号,发送确认给对方
- 发送端上面来了分组 -> 发送窗口滑动 -> 接收窗口滑动 -> 发确认
异常情况下GBN的2窗口互动
- 发送窗口
- 新分组落入发送缓冲区范围,发送 -> 前沿滑动
- 超时重发机制让发送端将发送窗口中的所有分组发送出去
- 来了老分组的重复确认 -> 后沿不向前滑动 -> 新的分组无法落入发送发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
- 接收窗口
- 收到乱序分组,没有落入到接收窗口范围内,抛弃
- (重复)发送老分组的确认,累计确认
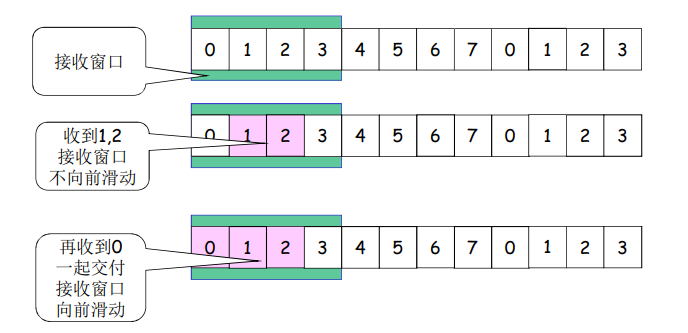
异常情况下SR的2窗口互动
- 发送窗口
- 新分组落入发送缓冲区范围,发送 -> 前沿滑动
- 超时重发机制让发送端将超时的分组重新发送出去
- 来了乱序分组的确认 -> 后沿不向前滑动 -> 新的分组无法落入发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
- 接收窗口
- 收到乱序分组,落入到接收窗口范围内,接收
- 发送该分组的确认,单独确认
流水线协议:总结
GBN和SR
Go-back-N(GBN):(回退N步)
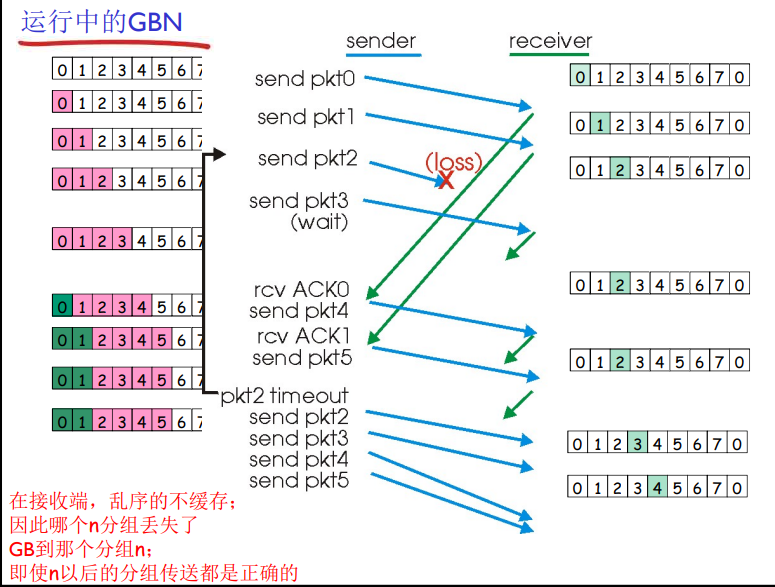
数据必须按序交付,在GBN协议中,接收方丢弃所有失序分组。
在接收方,如果分组2丢失,即使3,4,5都成功确认也要被丢弃重传,这就是按序交付。
- 发送端最多在流水线中有 N 个未确认的分组
- 接收端只是发送累计型确认 cumulative ack,表明接收方已正确接收到序号为n的以前且包括n在内的所有分组。
- 接收端如果发送 gap,不确认新到来的分组
- 发送端拥有对赘肉的未确认分组的定时器
- 只需设置一个定时器
- 当定时器到时时,重传所有未确认分组
Selective Repeat(SR):
选择重传(SR)协议通过让发送方仅重传那些它怀疑在接收方出错(即丢失或受损)的分组而避免了不必要的重传。
- 发送端最多在流水线中有 N 个未确认的分组
- 接收方对每个到来的分组单独确认 individual ack (非累计确认)
- 发送方为每个未确认的分组保持一个定时器
- 当超时定时器到时,只重发到时的未确认分组
如果接收方不确认该分组,则发送方窗口将永远不能向前滑动!这说明,对于哪些分组已经被正确接收,哪些没有,发送方和接收方并不总是能看到相同的结果,对于SR而言,这就意味着发送方和接收方的窗口并不总是一致(缺乏同步会产生严重的后果)。
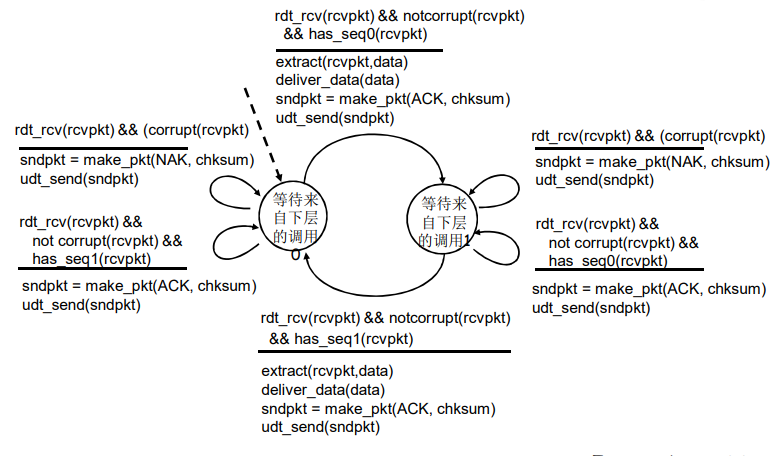
GBN:扩展的FSM
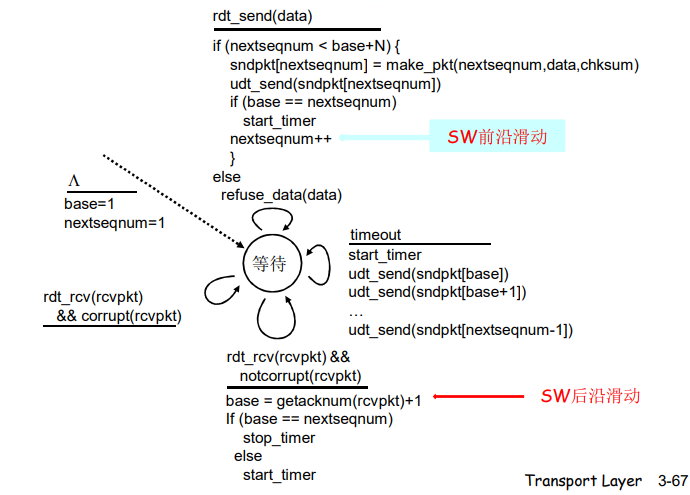
GBN:发送方扩展的FSM
GBN:接收方扩展的FSM
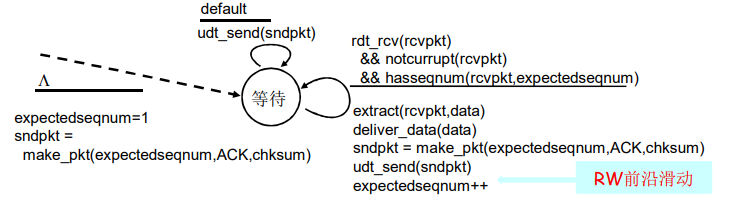
- 只发送ACK:对顺序接收的最高序号的分组
- 可能会产生重复的 ACK
- 只需记住 expectedseqnum ;接收窗口 = 1,只一个变量就可表示接收窗口
- 对乱序的分组:
- 丢弃(不缓存)-> 在接收方不被缓存!
- 对顺序接收的最高序号的分组进行确认 - 累计确认

扩展FSM指的是扩展有限状态机(Finite State Machine),它是一种模型,用于描述系统的各种状态和状态之间的转移。
在扩展FSM中,我们可以添加新的状态和转移,以适应系统的需求。例如,我们可以添加新的状态来表示系统的故障或者异常状态,或者添加新的转移来处理系统的错误或者异常情况。
扩展FSM的优点在于它可以更好地描述系统的各种状态和状态之间的转移,从而提高系统的可靠性和稳定性。但是,扩展FSM也存在一些缺点,例如它可能会导致状态的数量增加,从而增加系统的复杂性和开销。
总之,扩展FSM是一种用于描述系统的各种状态和状态之间的转移的模型,它可以添加新的状态和转移来适应系统的需求,从而提高系统的可靠性和稳定性。但是,扩展FSM也需要在实际应用中仔细考虑其优缺点,并进行合理的设计和优化。
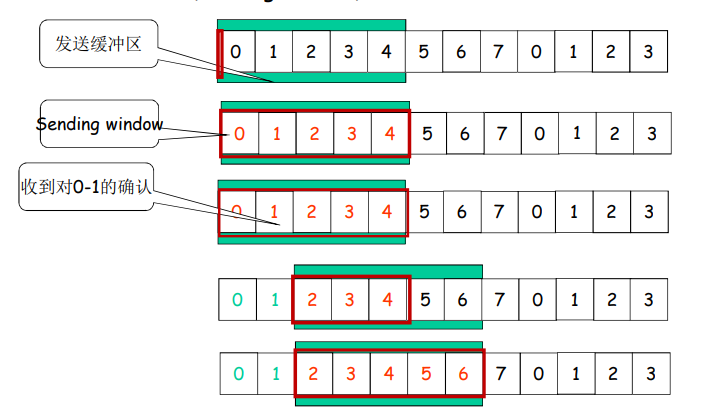
运行中的GBN
选择重传SR
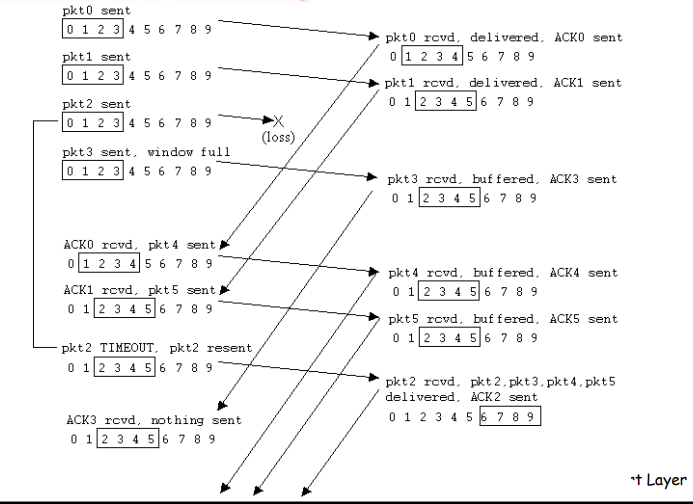
接收方对每个正确接收的分组,分别发送 ACKn(非累积确认)
- 接收窗口 >1
- 可以缓存乱序的分组
- 最终将分组按顺序交付给上层
- 接收窗口 >1
发送方只对那些没有收到ACK的分组进行重发 - 选择性重发
- 发送方为每个未确认的分组设定一个定时器
发送窗口的最大值(发送缓冲区)限制发送未确认分组的个数
如果收到ACK,倘若该分组序号在窗口内,则SR发送方将哪个被确认的分组标记为已接收,窗口基序号向前移动到具有最小序号的未确认分组处。如果窗口移动了并且有序号落在窗口内的未发送分组,则发送这些分组。
发送方
从上层接收数据:
- 如果下一个可用于该分组的序号可在发送窗口中,则发送 timeout(n)
- 重新发送分组 n,重新设定定时器
ACK(n) in [sendbase, sendbase+N]:
- 将分组 n 标记为已接收
- 如 n 为最小未确认的分组序号,
- 将 base 移到下一个未确认序号
接收方:
分组n[rcvbase, rcvbase + N - 1]
- 发送ACK(n)
- 乱序:缓存
- 有序:该分组及以前缓存的序号连续的分组交付给上层,然后将窗口移到下一个仍未被接收的分组
分组n [rcvbase-N,rcvbase-1]
- ACK(n)
其他:
- 忽略该分组
选择重传SR的运行
GBN协议和SR协议的异同
相同之处
- 发送窗口 >1
- 一次能够可发送多个未经确认的分组
不同之处
- GBN:接收窗口尺寸 =1
- 接收端:只能顺序接收
- 发送端:从表现来看,一旦一个分组没有发成功,如:0,1,2,3,4;假如1未成功,234都发送出去了,要返回1再发送:GB1
- SR:接收窗口尺寸 >1
- 接收端:可以乱序接收
- 发送端:发送0,1,2,3,4;一旦1未成功,2,3,4 已发送,无需重发,选择性发送1
对比GBN和SR
| GBN | SR | |
|---|---|---|
| 优点 | 简单,所需资源少(接收方一个缓存单元) | 出错时,重传一个(代价小) |
| 缺点 | 一旦出错,回退N步(代价大) | 复杂,所需要的资源多(接收方多个缓存单元) |
- 适用范围
- 出错率低:比较适合GBN,出错非常罕见,没有必要用复杂的SR,为罕见的事件做日常的准备和复杂处理
- 链路容量大(延迟大,带宽大):比较适合SR而不是GBN,一点出错代价太大。
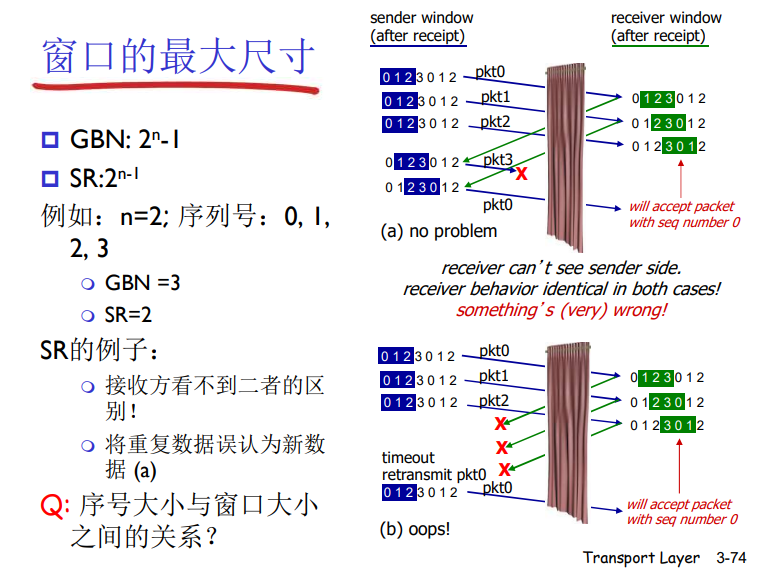
窗口的最大尺寸
可靠数据传输机制及其用途的总结
| 机制 | 用途和说明 |
|---|---|
| 检验和 | 用于检测在一个传输分组中的比特错误 |
| 定时器 | 用于超时/重传一个分组,可能因为该分组(或其ACK)在信道中丢失了。由于当一个分组延时但未丢失(过早超时),或当一个分组已被接收方收到发送方的ACK丢失时,可能产生超时事件,所以接收方可能会收到一个分组的多个冗余副本 |
| 序号 | 用于为从发送方刘翔接收方的数据分组按顺序编号。所接收分组的序号间的空隙可使接收方检测出丢失的分组。具有相同序号的分组可使接收方检测出一个分组的冗余副本 |
| 确认 | 接收方用于告诉发送方一个分组或一组分组已被正确地接收到了。确认报文通常携带着被确认的分组或多个分组的序号。确认可以使逐个的或累积的,这取决于协议 |
| 否定确认 | 接收方用于告诉发送方某个分组未被正确地接收。否定确认报文通常携带着未被正确接收的分组的序号 |
| 窗口、流水线 | 发送方也许被限制仅发送那些序号落在一个指定范围内的分组。通过允许一次发送多个分组但未被确认,发送方的利用率可在停等操作模式的基础上得到增加。我们很快将会看到,窗口长度可根据接收方接收和缓存报文的能力、网络中的拥塞程度或两者情况来进行设置 |
面向连接的传输:TCP
TCP被称为是面向连接的(connection-oriented),这是因为在一个应用进程可以开始向另一个应用进程发送数据之前,这两个进程必须先相互“握手”,即它们必须相互发送某些预备报文段,以建立确保数据传输的参数。作为TCP连接建立的一部分,连接的双方都将初始化与TCP连接相关的许多TCP状态变量(其中的许多状态变量将在本节和3.7节中讨论)。
TCP是全双工的。
TCP:概述
这种TCP“连接”不是一条像在电路交换网络中的端到端TDM或FDM电路。相反,该“连接”是一条逻辑连接,其共同状态仅保留在两个通信端系统的TCP程序中。
由于 TCP 协议只在 端系统中运行 ,而不在中间的 网络元素(路由器和链路层 )中运行, 所以 中间的网络元素 并不会 维持 TCP 连接
事实上,中间 路由器对 TCP 的连接视而不见,他们看到的 是 数据报,而不是连接
TCP 的 连接也总是 点对点的(point - to - point),即 在单个发送方和单个接收方之间的连接
我们现在来看看TCP连接是怎样建立的。假设运行在某台主机上的一个进程想与另一台主机上的一个进程建立一条连接。发起连接的这个进程被称为客户进程,而另一个进程被称为服务器进程。
该客户应用进程首先要通知客户运输层,它想与服务器上的一个进程建立一条连接。
clientsocket.connect((serverName,serverPort))其中 serverName 是服务器的名字,serverPort 标识了服务器上的进程。客户边开始与服务器上上的 TCP 建立一条 TCP 连接。
- 客户首先发送一个特殊的TCP报文段
- 服务器用另一个特殊的TCP报文段来响应
- 客户再用第三个特殊报文段作为响应
前两个报文段不承载“有效载荷”,也就是不包含应用层数据;而第三个报文段可以承载有效载荷。由于在这两台主机之间发送了3个报文段,所以这种连接建立过程常被称为 三次握手(three-way handshake)
一旦建立起一条TCP连接,两个应用进程之间就可以相互发送数据了。
下面考虑一下从客户进程向服务器进程发送数据的情况。客户进程通过套接字(该进程之门)传递数据流。数据一旦通过该门,它就由客户中运行的TCP控制了。如图3-28所示,TCP将这些数据引导到该连接的发送缓存(send buffer)里,发送缓存是发起三握手期间设置的缓存之一。接下来TCP就会不时从发送缓存里取出一块数据,并将数据传递到网络层。有趣的是,在TCP规范[RFC793]中却没提及TCP应何时实际发送缓存里的数据,只是描述为 “TCP应该在它方便的时候以报文段的形式发送数据” 。TCP可从缓存中取出并放入报文段中的数据数量受限于最大报文段长度(Maximum Segment Size,MSS)。MSS通常根据最初确定的由本地发送主机发送的最大链路层帧长度(即所谓的最大传输单元(Maximum Transmission Unit,MTU))来设置。设置该MSS要保证一个TCP报文段(当封装在一个IP数据报中)加上TCP/IP首部长度(通常40字节)将适合单个链路层帧。以太网和PPP链路层协议都具有1500字节的MTU,因此MSS的典型值为1460字节。注意到MSS是指在报文段里应用层数据的最大(有效)长度,而不是指包括首部的TCP报文段的最大长度。
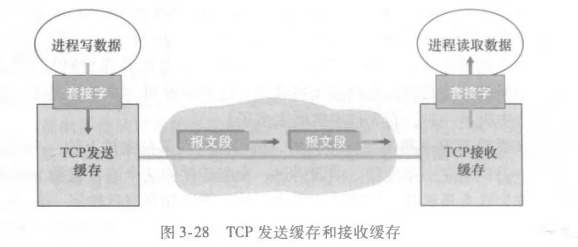
TCP为每块客户数据配上一个TCP首部,从而形成多个TCP报文段,这些报文段被下传给网络层,网络层将其封装在网络层 IP 数据报中。然后这些 IP 数据报被发送到网络中。当 TCP 在另一端接收到一个报文段后,该报文段的数据就被放入该 TCP连接的接收缓存中。如上图所示,应用从此缓存中读取的数据流,该连接的每一段都有各自的发送缓存和接收缓存。
TCP连接的组成包括:一台主机上的缓存、变量和与进程连接的套接字,以及另一台主机上的另一组缓存、变量和与进程连接的套接字。在这两台主机之间的网络元素(路由器、交换机和中继器)中,没有为该连接分配任何缓存和变量。
- 点对点:
- 一个发送方,一个接收方
- 可靠的、按顺序的字节流:
- 没有报文边界
- 管道化(流水线):
- TCP拥塞控制和流量控制设置窗口大小
- 发送和接收缓存
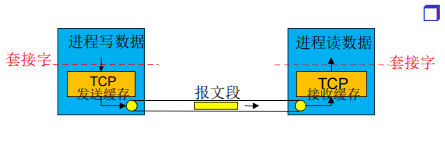
- 全双工数据:
- 在同一连接中数据流双向流动
- MSS:最大报文段大小
- 面向连接:
- 在数据交换之前,通过握手(交换控制报文)初始化发送方、接收方的状态变量
- 有流量控制:
- 发送方不会淹没接收方
TCP报文段结构
TCP报文段结构
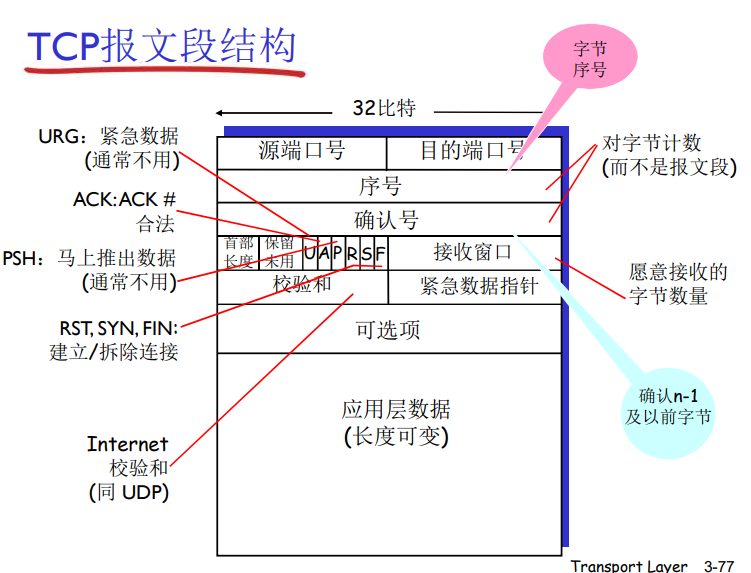
TCP报文段由首部字段和一个数据字段组成。数据字段包含一块应用数据。MSS限制了报文段数据字段的最大长度。
首部包括源端口号和目的端口号,它被用于多路复用/分解来自或送到上层应用的数据。
TCP序号,确认号
序号:(32比特)
- 报文段首字节的在字节流的编号
确认号:(32比特)
- 期望从另一方收到的下一个字节的序号
- 累积确认
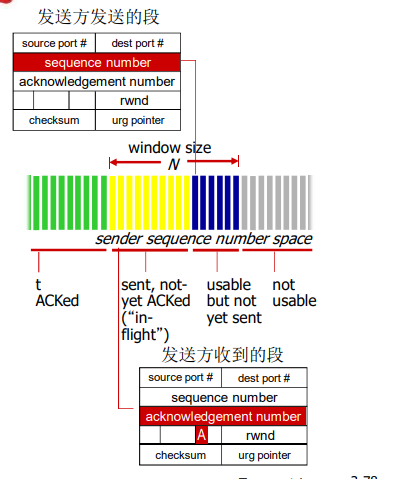
这两个字段是TCP可靠传输服务的关键部分。
TCP把数据看成一个无结构的、有序的字节流。我们从 TCP 对序号的使用上可以看出这一点,因为序号是建立在传送的字节流之上,而不是建立在传送的报文段的序列之上。一个报文段的序号因此是该报文段首字节的字节流编号。
TCP是全双工的,因此主机 A 在向主机 B 到达的每个报文段中都有一个序号用于从 B 流向 A 的数据。主机 A 填充进报文段的确认号是主机 A 期望从主机 B 收到的下一字节的序号 (假设主机A已经收到了来自主机B的编号 0 ~ 535的所有字节,同时假设它打算发送一个报文段给主机B,主机A等待主机B的数据流中子产品536即之后的所有字节,所以主机A就会在它发往主机B的报文段的确认号字段中填上536)。
当主机在一条 TCP 连接中收到失序报文段时该怎么办?TCP把这一问题留给了实现TCP的编程人员去处理,他们有两种基本的选择
- 接收方立即丢弃失序报文段
- 接收方保留失序的字节,并等待缺少的字节以填补该间隔。(这种选择对网络带宽而言更为有效,是实践中采用的方法)
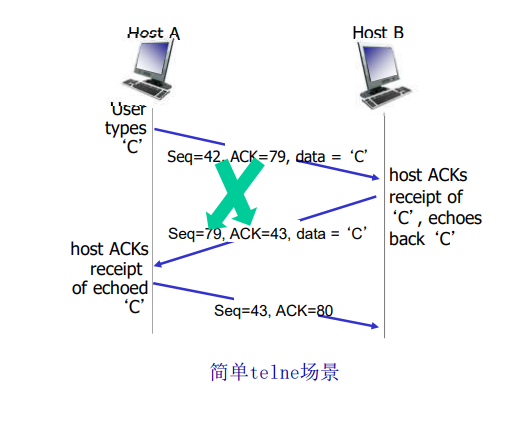
第一个报文段是由客户发往服务器,Seq=42 表示客户端给服务器字节从42开始(包括42),而且客户端希望服务器发送确认字段从79开始,data表示客户端传输给服务器的数据部分
第二个报文段是由服务器发往客户端的,它有两个目的:
- 第一个目的:它是为该服务器所收到数据提供一个确认。通过在确认号字段中填入 43,服务器告诉客户它已经成功地收到字节42及以前的所有字节,现在正等待着字节43的出现。
- 第二个目的:回显字符 ‘C’ 。第二个报文段的序号为 79,它是该 TCP 连接上从服务器到客户的数据流的起始序号,这也正是服务器要发送的第一个字节的数据。
对客户到服务器的数据的确认被装载在一个承载服务器到客户的数据的报文段中;这种确认被称为是被捎带在服务器到客户的数据报文中的。
TCP往返延时(RTT)和超时
TCP 如 rdt 一样,它采用 超时/ 重传 机制来处理报文段的丢失问题。但是 超时 间隔长度的设置 是一个明显的问题。显然,超时时间间隔 必须大于 该连接 的RTT,即从一个报文段发出到它被确认的时间,否则 会造成 不必要的 重传
Q:怎样设置TCP超时?
- 比 RTT 要长
- 但 RTT 是变化的
- 太短:太早超时
- 不必要的重传
- 太长:对报文段的丢失反应太慢
估计往返时间
估计之间往返时间的。这是通过如下方法完成的。报文段的样本RTT(表示为SampleRTT)就是从某报文段被发出(即交给IP)到对该报文段的确认被收到之间的时间量。大多数TCP的实现仅在某个时刻做一次SampleRTT测量,而不是为每个发送的报文段测量一个SampleRTT。这就是说,在任意时刻,仅为一个已发送的但目前尚未被确认的报文段估计Samp-leRTT, 从而产生一个接近每个RTT的新SampleRTT值。另外,TCP决不为已被重传的报文段计算SampleRTT; 它仅为传输一次的报文段测量SampleRTT[Kan1987]
显然,由于路由器的拥塞和端系统负载的变化,这些报文段的 SampleRTT 值会随之波动。由于这种波动,任何给定的SampleRTT值也许都是非典型的。因此,为了估计一个典型的RTT,自然要采取某种对SampleRTT取平均的办法。TCP维持一个SampleRTT均值(称为EstimatedRTT)。一旦获得一个新SampleRTT时,TCP就会根据下列公式来更新EstimatedRTT :

- 指数加权移动平均
- 过去样本的影响呈指数衰减
- 推荐值:α = 0.125
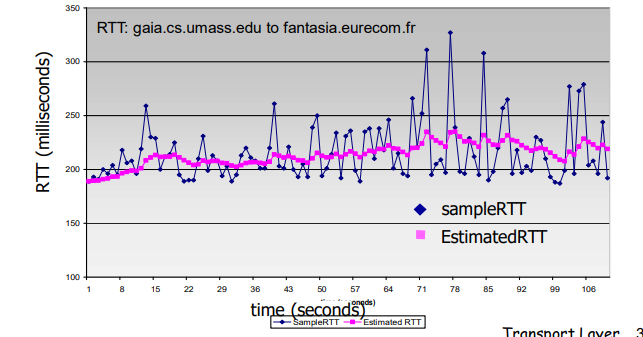
Q:怎样估计 RTT
- SampleRTT:测量 报文段发出到收到确认的 时间
- 如果有重传,忽略此次测量
- SampleRTT 会变化,因此估计的 RTT 应该比较平滑
- 对 几个最近的测量值求平均,而不是仅用当前的 SampleRTT
设置和管理重传超时间隔
很明显,超时间隔应该大于等于EstimatedRTT 否则,将造成不必要的重传。但是超时间隔也不应该比 EstimatedRTT 大太多,否则当报文段丢失时,TCP不能很快地重传该报文段,导致数据传输时延大。因此要求将超时间隔设为 EstimatedRTT 加上一定余量。当 SampleRTT 值波动较大时,这个余量应该大些;当波动较小时,这个余量应该小些。因此:

推荐的 TimeoutInterval 为 1 s, 同时当出现超时时, TimeoutInterval 值将加倍,以免即将被确认的后继报文段过早出现超时。然而,只要收到报文段并更新 EstimatedRTT, 就使用上述公式再次计算 TimeoutInterval
设置超时:
- EstimtedRTT + 安全边界时间
- EstimatedRTT变化大(方差大) -> 较大的安全边界时间
- SampleRTT 会偏离 EstimateRTT多远:

- 超时时间设置

TCP:可靠数据传输
因特网的网络层服务(IP服务)是不可靠的。
IP不保证数据报的交付,不保证数据报的按序交付,也不保证数据报中数据的完整性
对于IP服务,数据报能够溢出路由器缓存而永远不能到达目的地。数据报也可能是乱序到达,而且数据报中的比特可能损坏
由于运输层报文段是被IP数据报携带着在网络中传输的,所以运输层的报文段也会遇到这些问题。
TCP在IP不可靠的尽力而为服务(可以认为是完全没服务)之上创建了一种可靠数据传输服务(reliable datatransfer service)。
TCP的可靠数据传输服务确保一个进程从其接收缓存中读出的数据流是无损坏、无间隙、非穴余和按序的数据流;即该字节流与连接的另一方端系统发送出的字节流是完全相同。TCP提供可靠数据传输的方法涉及在 rdt 中所学的许多原理。
TCP:可靠数据传输
TCP在IP不可靠服务的基础上建立了rdt
- 管道化的报文段
- GBN or SR
- 累积确认(像GBN)
- 单个重传定时器(像GBN)
- 是否可以接收乱序的,没有规范
- 管道化的报文段
通过以下时间触发重传
- 超时(只重发那个最早的未确认段:SR)
- 重复的确认
- 例子:收到了 ACK50,之后又收到 3 个 ACK50
首先考虑简化的TCP发送方:
- 忽略重复的确认
- 忽略流量控制和拥塞控制
TCP 发送方(简化版)
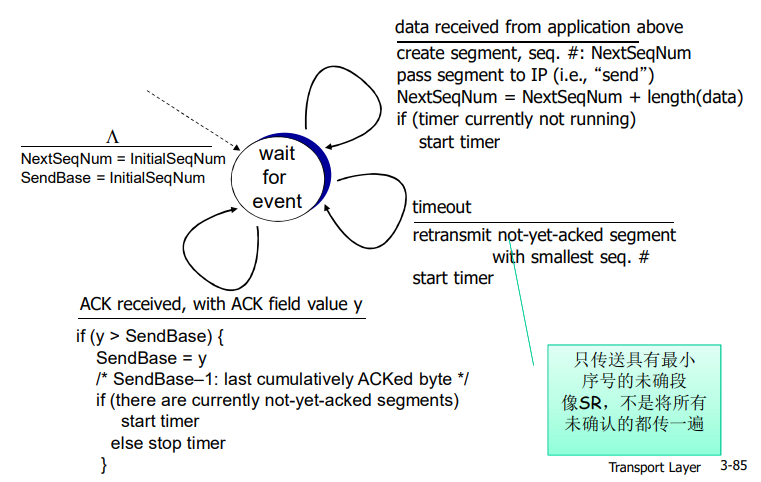
TCP发送方事件:
从应用层接收数据:
- 用nextseq创建报文段
- 序号nextseq为报文段首字节的字节流编号,交给IP
- 如果还没有运行,启动定时器
- 定时器与最早未确认的报文段关联
- 过期间隔:
TimeOutInterval
超时:
TCP通过重传引起的报文段来响应超时事件。然后TCP重启定时器。
- 重传后沿最老的报文段
- 重新启动定时器
收到确认:
- 如果是对尚未确认的报文段确认
- 更新已被确认的报文序号
- 如果当前还有未被确认的报文段,重新启动定时器
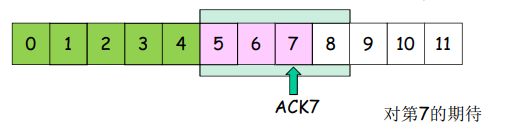

TCP:重传
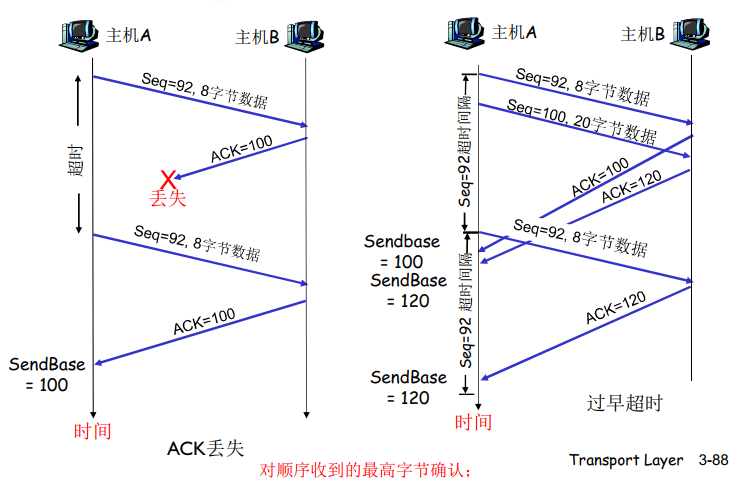
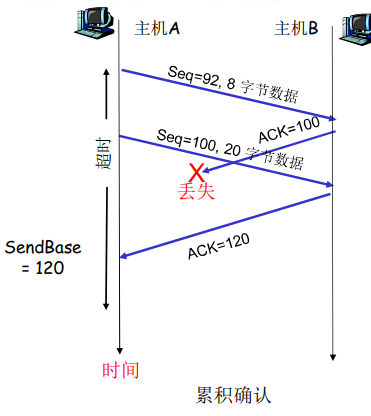
TCP快速重传
- 超时周期往往太长:
- 在重传丢失报文之前的延时太长,增加了端到端的时延。
- 通过重复的ACK来检测报文段丢失
- 发送方通常连续发送大量报文段
- 如果报文段丢失,通常会引起多个重复的ACK
- 如果发送方收到同一数据的 3 个冗余 ACK,重传最小序号的段:
- 快速重传:在定时器过时之前重发报文段
- 它假设跟在被确认的数据后面的数据丢失了
- 第一个ACK是正常的;
- 收到第二个该段的ACK,表示接收方收到一个该段后的乱序段;
- 收到 3, 4 个该段的 ACK,表示接收方收到该段之后的 2 个,3个乱序段,可能性非常大,段丢失了。
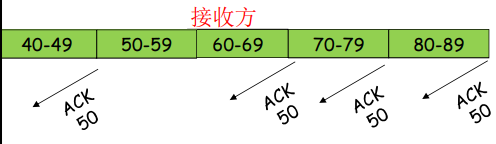
快速重传

超时触发重传存在的问题之一是超时周期可能相对较长。当一个报文段丢失时,这种长超时周期迫使发送方延迟重传丢失的分组,因而增加了端到端时延。幸运的是,发送方通常可在超时事件发生之前通过注意所谓冗余ACK来较好地检测到丢包情况。冗余ACK(duplicate ACK) 就是再次确认某个报文段的ACK,而发送方先前已经收到对该报文段的确认。
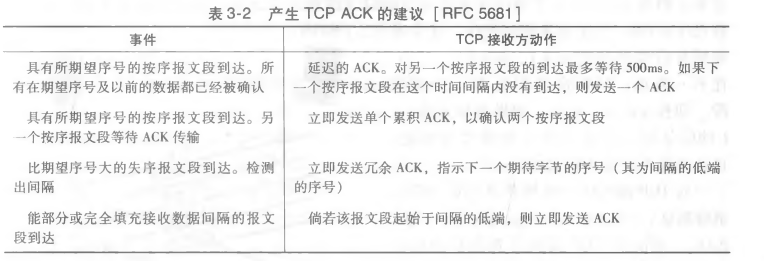
因为发送方经常一个接一个地发送大量的报文段,如果一个报文段丢失,就很可能引起许多一个接一个的 冗余ACK(因为服务器也需要客户端确认收到这个ACK,客户端如果没有发送或丢失发给服务器的ACK,则服务器会一直给客户端发之前的ACK,直到得到客户端的确认)。如果TCP发送方接收到对相同数据的 3 个冗余 ACK,它把这当做一种指示,说明 根在这个已被确认过3次的报文段之后的报文段已经丢失。 一旦收到 3 个冗余ACK,TCP就执行快速重传(fast retransmit)[RFC5681],即在该报文段的定时器过期之前上重传丢失的报文段。 对于采用快速重传的TCP,可用下列代码片段代替 下图 中的 ACK时间:
 ****
****
快速重传算法

TCP正确接收但失序的报文段是不会被接收方逐个确认的,TCP发送方仅需维持已发送过但未被确认的字节的最小序号(SendBase)和下一个要发送的字节的序号(NextSeqNum)。
对TCP提出的一种修改意见是所谓的选择确认(Selective acknowledgment)[RFC 2018],它允许TCP接收方有选择地确认失序报文段,而不是累积地确认最后一个正确接收的有序报文段。
因此,TCP的差错恢复机制也许最好被分类为 GBN协议 与 SR协议的混合体。
流量控制
前面说过,一条 TCP 连接的每一侧主机都为该链接设置了 接收缓存。当该 TCP 连接收到正确、按序的字节后,他就将数据放入缓存中。相关联的 应用进程会从该缓存中读取数据,但 不必是数据刚一到达就立即读取。 事实上,接收方可能正忙于其他任务,甚至要过很长时间才去读取该数据。如果,某应用程序读取数据时 相对缓慢,而发送方发送得太多、太快, 发送的数据就会很容易地使该链接的接收缓存溢出
TCP为它的应用程序提供了 流量控制服务(flow-control service)以消除发送方使接收方缓存溢出的可能性。流量控制因此是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。
前面提到过,TCP发方也可能因为IP网络的拥塞而被遏制;这种形式的发送方的控制被称为拥塞控制(congestion control),即使流量控制和拥塞控制采取的操作非常相似(对发送方的遏制),但是它们显然是针对完全不同的原因而采取的措施。
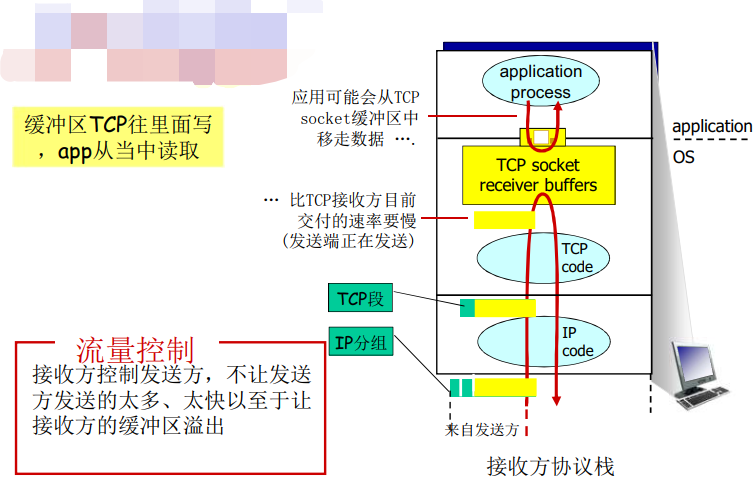
TCP通过让发送方维护一个称为接收窗口(receive window)的变量来提供流量控制。通俗地说,接收窗口用于给发送方一个指示 -> 该接收方还有多少可用的缓存空间。因为TCP是全双工通信,在连接两端的发送方都各自维护一个接收窗口。
- 接收方在其向发送方的TCP段头部的rwnd字段 “通告” 其空闲 buffer 大小
- RcvBuffer 大小通过 socket 选项设置(典型默认大小为 4096 字节)
- 很多操作系统自动调整
RcvBuffer

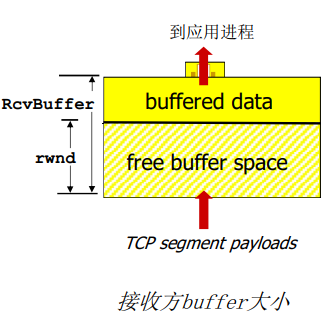
- 发送方限制未确认(”in-flight”)字节的个数 <= 接收方发过来的 rwnd 值
- 保证接收方不会被淹没
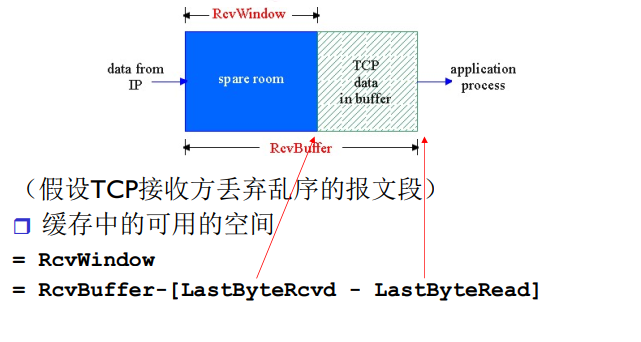
这个方案还存在一个小小的问题,假设主机B的接收缓存已经存满,使得 rwnd=0 。在将 rwnd=0通告给主机A之后,还要假设主机B没有任何数据要发给主机A。此时,考虑会发生什么情况。因为主机B上的应用进程将缓存清空,TCP并不向主机A发送带有rwnd新值的新报文段;事实上,TCP仅当在它有数据或有确认要发时才会发送报文段给主机A。这样,主机A不可能知道主机B的接收缓存已经有新的空间了,即主机A被阻塞而不能再发送数据!为了解决这个问题,TCP规流中要求:当主机B的接收窗口为0时,主机A继续发送只有一个字节数据的报文段。这些报文段将会被接收方确认。最终缓存将开始清空,并且确认报文里将包含一个非0的rwnd值。
描述了 TCP 的流量控制服务之后,在此简要的 提一下 UDP 并不提供 流量控制,报文段由于缓存溢出可能在接收方丢失。 进程每次从 缓存中读取一个完整的报文段,如果 进程从缓存中读取报文段的速度还不够快,那么 缓存将会溢出,并且将丢失报文段
连接管理
TCP连接管理
在正式交换数据之前,发送方和接收方握手建立通信关系:
- 同意建立连接(每一方到知道对方愿意建立连接)
- 同意连接参数
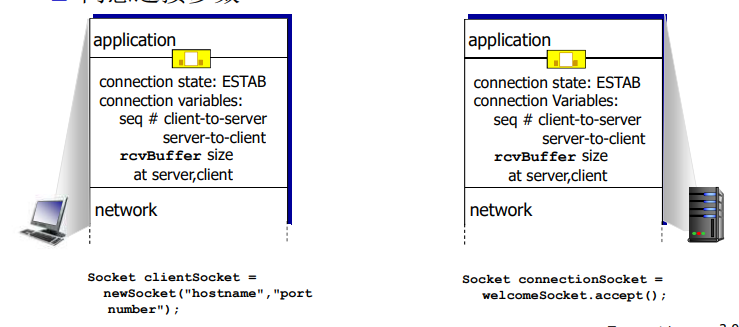
同意建立连接
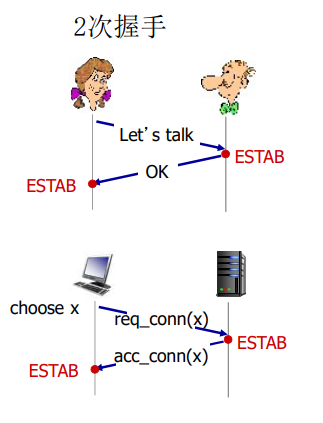
Q:在网络中,2 次握手建立连接总是可行吗?
- 变化的延迟(连接请求的段没有丢,但可能超时)
- 由于丢失造成的重传(e.g. req_conn(x))
- 报文乱序
- 相互看不到对方
2次握手的失败场景:
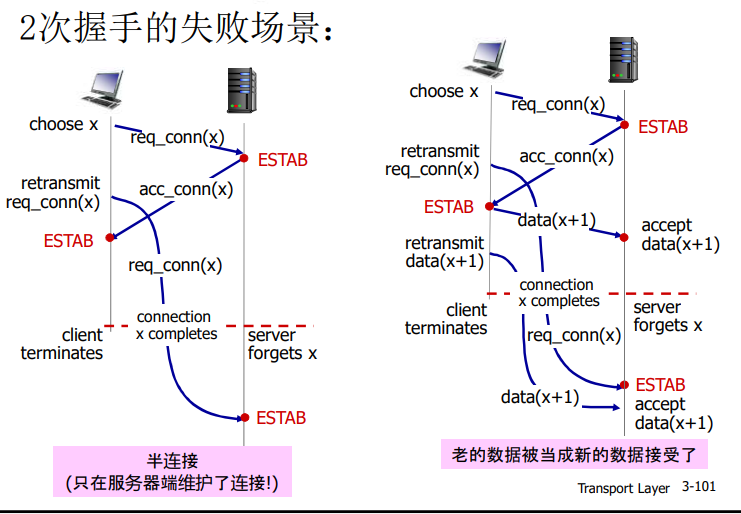
TCP:3次握手
3次握手:
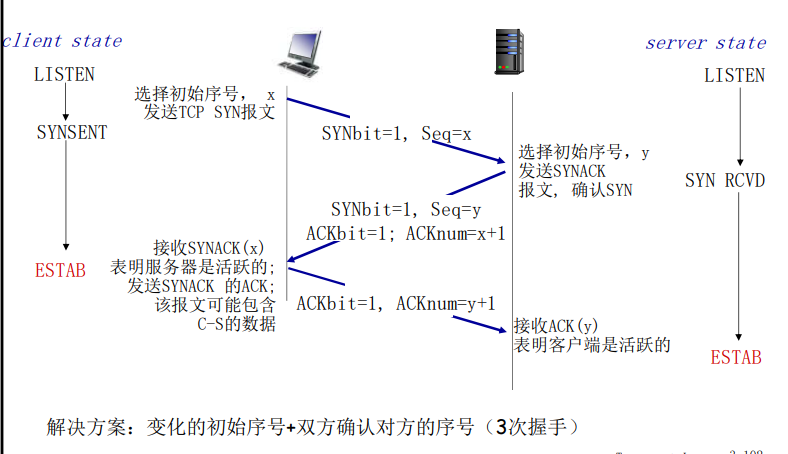
3次握手解决:半连接和接收老数据问题
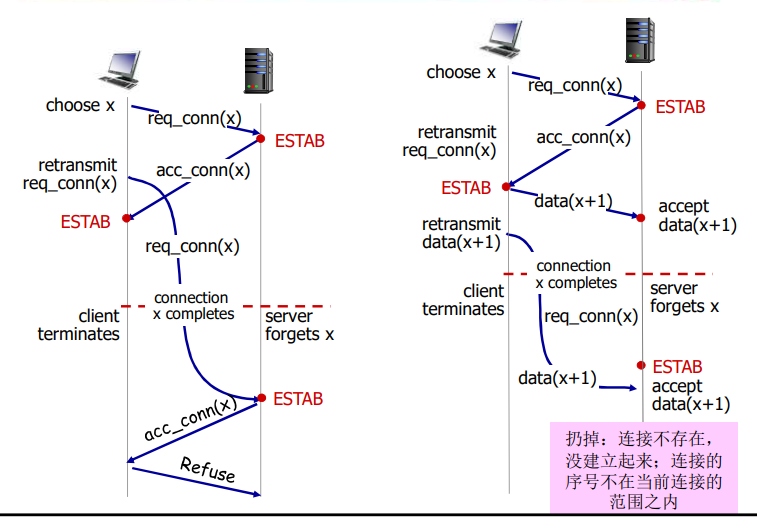
TCP 3次握手:FSM
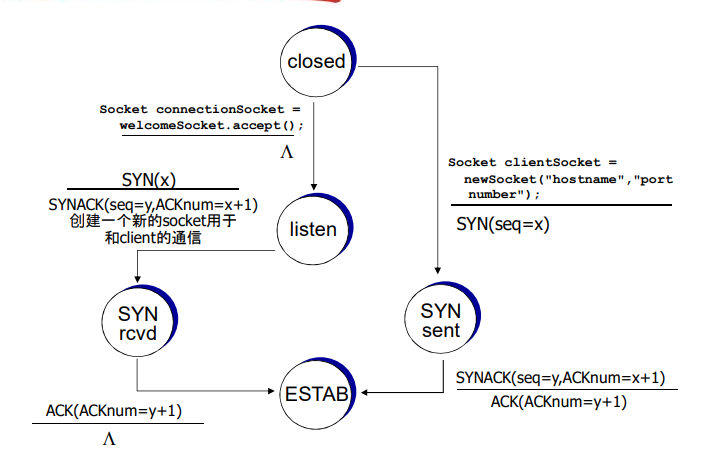
现在我们去更加仔细的观察如何建立 和 拆除一条 TCP 连接。
- 第一步:客户端的TCP首先向服务器端的TCP发送一个特殊的TCP报文段。该报文段中不包含应用层数据。但是在报文段的首部(参见图3-29)中的一个标志位(即SYN比特)被置为1。因此,这个特殊报文段被称为SYN报文段。另外,客户会随机地选择一个初始序号(client_isn),并将此编号放置于该起始的TCP SYN报文段的序号字段中。该报文段会被封装在一个IP数据报中,并发送给服务器。为了避免某些安全性攻击,在适当地随机化选择client_isn方面有着不少有趣的研究[CERT 2001-09]。
- 第二步:一旦包含TCP SYN报文段的IP数据报到达服务器主机(假定它的确到达了!),服务器会从该数据报中提取出TCP SYN报文段,为该TCP连接分配TCP缓存和变量,并向该客户TCP发送允许连接的报文段。(我们将在第8章看到,在完成三次握手的第三步之前分配这些缓存和变量,使得TCP易于受到称为SYN洪泛的拒绝服务攻击。)这个允许连接的报文段也不包含应用层数据。但是,在报文段的首部却包含3个重要的信息。首先,SYN比特被置为1。其次,该TCP报文段首部的确认号字段被置为client_isn+1。最后,服务器选择自己的初始序号(server_isn),并将其放置到TCP报文段首部的序号字段中。这个允许连接的报段实际上表明了:“我收到了你发起建立连接的SYN分组,该分组带有初始序号client_isn。我同意建立该连接。我自己的初始序号是server_isn。”该允许连接的报文段被称为SYN ACK报文段(SYN ACK segment)。
- 第三步:在收到SYN ACK报文段后,客户也要给该连接分配缓存和变量。客户机则向服务器发送另外一个报文段;这最后一个报文段对服务器的允许连接的报文段进行了确认(该客户通过将值server_isn+1放置到TCP报文段首部的确认字段中来完成此项工作)。因为连接已经建立了,所以该SYN比特被置为0。该三次握手的第三个阶段可以在报文段负载中携带客户到服务器的数据。
一旦完成这三个步骤,客户和服务器主机就可以互相发送包括数据的 报文段 了。注意: 为了创建这个连接,在两台主机之间发送了 3 个分组,由于这个原因,这种 连接创建过程 通常被称为 三次握手
TCP三次握手是用于建立一个可靠的TCP连接的过程,它包含以下三个步骤:
- 发送方向接收方发送一个SYN报文段,请求建立连接。
在这一步中,发送方向接收方发送一个SYN报文段,请求建立连接。这个SYN报文段中包含一个随机的序列号,用于标识数据流的起始位置。发送方还会向接收方发送一些其他的TCP参数,例如窗口大小、最大分段大小等等。
- 接收方向发送方发送一个SYN+ACK报文段,确认收到请求并请求建立连接。
当接收方收到发送方的SYN报文段后,它向发送方发送一个SYN+ACK报文段,表示已经收到了建立连接的请求,并请求建立连接。这个SYN+ACK报文段中也包含一个随机的序列号,用于标识数据流的起始位置。接收方还会向发送方发送一些其他的TCP参数,例如窗口大小、最大分段大小等等。
- 发送方向接收方发送一个ACK报文段,确认收到确认消息并建立连接。
当发送方收到接收方的SYN+ACK报文段后,它向接收方发送一个ACK报文段,表示已经收到了确认消息,并建立了连接。这个ACK报文段中包含接收方的序列号+1,用于告诉接收方下一次应该从哪个位置开始发送数据。
在这个过程中,发送方和接收方都会在自己的TCP缓存中保存一些用于维护连接状态的信息。这些信息包括序列号、窗口大小、最大分段大小等等,用于保证数据的可靠传输。
总之,TCP三次握手是用于建立一个可靠的TCP连接的过程,它包含三个步骤。在这个过程中,每一步都是非常重要的,它们确保了连接的正常建立,并保证了数据的完整性和可靠性。
如果没有TCP三次握手中的第三步,即接收方不向发送方发送确认消息,那么发送方将不知道接收方是否已准备好接收数据。在这种情况下,发送方可能会继续发送数据,但由于接收方未准备好接收数据,这些数据可能会丢失或损坏,从而导致通信失败。
因此,如果没有TCP三次握手中的第三步,通信的可靠性将无法得到保证,数据的传输将无法正确进行。这是TCP协议设计时必须考虑并解决的问题之一。
TCP:关闭连接
- 客户端,服务器分别关闭它自己这一侧的连接
- 发送 FIN bit = 1 的 TCP片段
- 一旦接收到 FIN,用 ACK回应
- 接到 FIN段,ACK可以和它自己发出的FIN段一起发送
- 可以处理同时的FIN交换
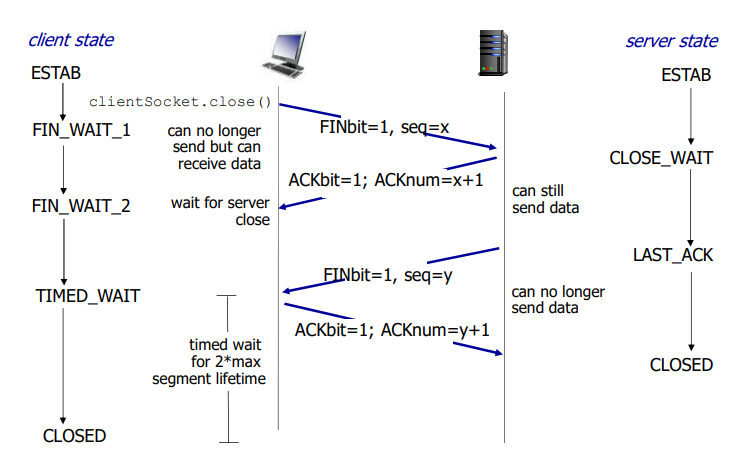
TCP:关闭连接
任何一个都能终止该连接。当连接结束后主机中的“资源”(即缓存和变量)将被释放。
举一个例子,假设某客户打算关闭连接,如图3-40所示。客户应用进程发出一个关闭连接命令。这会引起客户TCP向服务器进程发送一个特殊的TCP报文段。这个特殊的报文段让其首部中的一个标志位即FIN比特(参见图3-29)被设置为1。当服务器接收到该报文段后,就向发送方回送一个确认报文段。然后,服务器发送它自己的终止报文段,其FIN比特被置为1。最后,该客户对这个服务器的终止报文段进行确认。此时,在两台主机上用于该连接的所有资源都被释放了。
可以注意到 上面客户端与服务器端一共有 4 次 动作,TCP 的连接关闭 也被称为 四次挥手
TCP四次挥手是用于关闭一个TCP连接的过程,它包含以下四个步骤:
- 发送方向接收方发送一个FIN报文段,请求关闭连接。
在这一步中,发送方向接收方发送一个FIN报文段,请求关闭连接。这个FIN报文段表示发送方已经不会再向接收方发送数据了。发送方也可以在这个报文段中携带一些最后的数据,以便接收方能够正确地处理这些数据。
- 接收方向发送方发送一个ACK报文段,确认收到关闭请求。
当接收方收到发送方的FIN报文段后,它向发送方发送一个ACK报文段,表示已经收到了关闭请求。这个ACK报文段不会携带任何数据,只是用来确认发送方的关闭请求已经被接收到了。
- 接收方向发送方发送一个FIN报文段,请求关闭连接。
在这一步中,接收方向发送方发送一个FIN报文段,请求关闭连接。这个FIN报文段表示接收方已经不会再向发送方发送数据了。接收方也可以在这个报文段中携带一些最后的数据,以便发送方能够正确地处理这些数据。
- 发送方向接收方发送一个ACK报文段,确认收到关闭请求。
当发送方收到接收方的FIN报文段后,它向接收方发送一个ACK报文段,表示已经收到了关闭请求。这个ACK报文段不会携带任何数据,只是用来确认接收方的关闭请求已经被发送方接收到了。
在这个过程中,接收方向发送方发送的ACK报文段和FIN报文段可以合并在一起发送,即ACK+FIN报文段,这样就可以减少一次网络通信。但是,发送方向接收方发送的ACK报文段和FIN报文段需要分开发送,以避免接收方收到ACK报文段后就关闭了连接,导致发送方的FIN报文段无法到达接收方。
总之,TCP四次挥手是用于关闭一个TCP连接的过程,它包含四个步骤。在这个过程中,每一步都是非常重要的,它们确保了连接的正常关闭,并保证了数据的完整性和可靠性。
由于网络中存在一些延迟或丢失的数据包,因此在第四次挥手中,接收方还会向发送方发送一个最后的数据包,以确保数据能够完整地到达接收方。这个数据包可能是一个空数据包(ACK报文段),或者是一个包含数据的数据包(FIN+ACK报文段)。发送方接收到最后的数据包后,就可以确认通信已经结束,并释放连接。
拥塞控制原理
拥塞控制原理
拥塞:
- 非正式的定义:“太多的数据需要网络传输,超过了网络的处理能力”
- 与流量控制不同
- 拥塞的表现:
- 分组丢失(路由器缓冲区溢出)
- 分组经历比较长的延迟(在路由器的队列中排队)
- 网络中前10位的问题!
拥塞的原因/代价
场景1
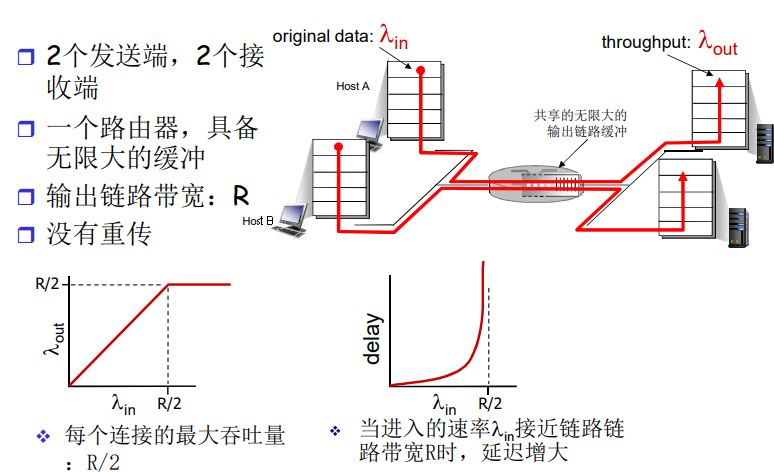
场景2
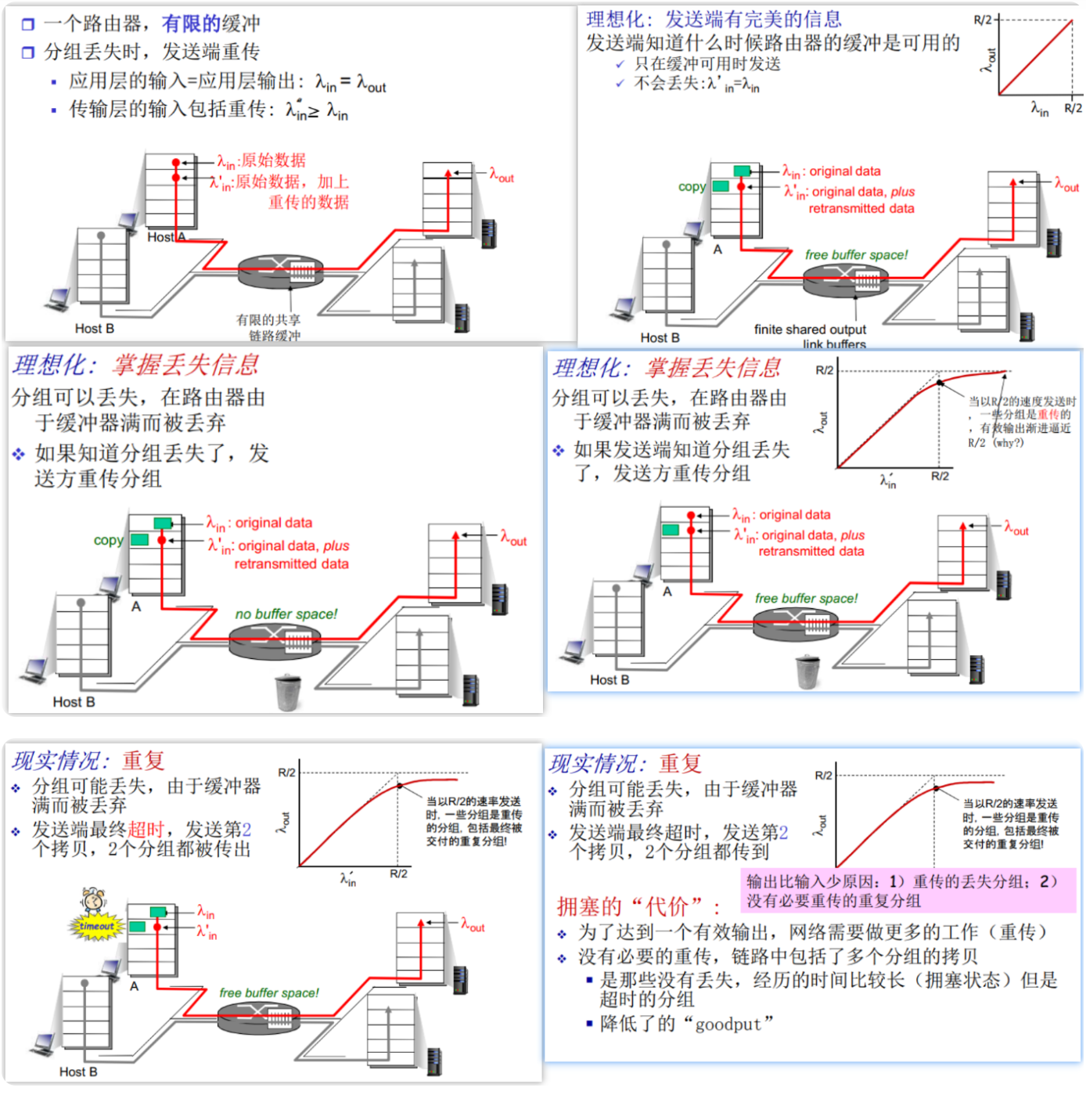
场景3
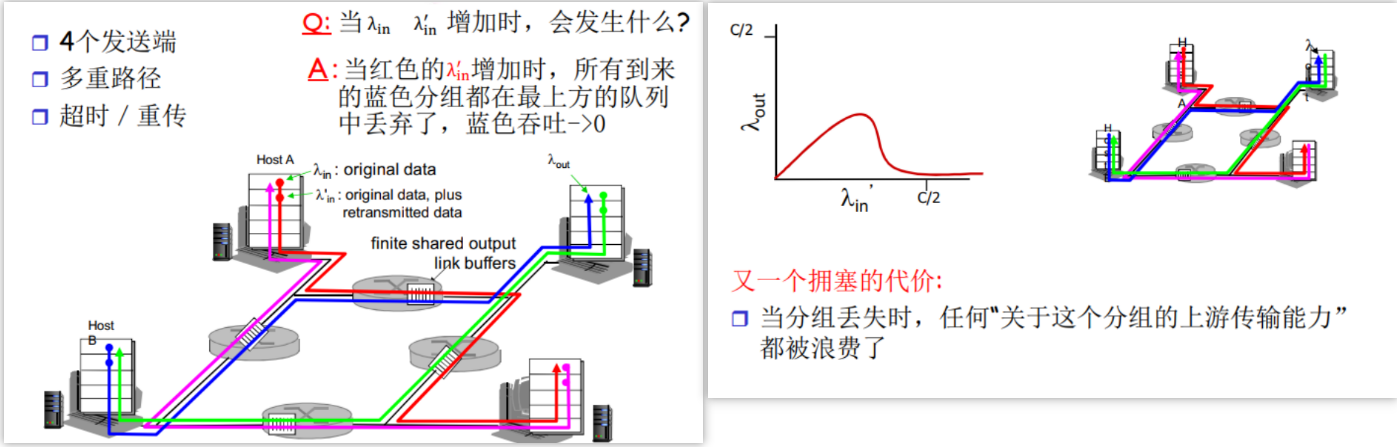
拥塞控制方法
2 种常用的拥塞控制方法:
端到端拥塞控制:
- 没有来自网络的显式反馈
- 段系统根据延迟和丢失时间推断是否有拥塞
- TCP采用的方法
网络辅助的拥塞控制:
- 路由器提供给端系统以反馈信息
- 单个 bit 置位,显式有拥塞(SNA,DEC bit,TCP/IP ECN,ATM)
- 显式提供发送端可以采用的速率
案例学习:ATM ABR 拥塞控制
ABR:available bit rate:
- “弹性服务”
- 如果发送端的路径 “轻载”
- 发送方使用可用带宽
- 如果发送方的路径拥塞了
- 发送方限制其发送的速度到一个最小保障速率上
RM(资源管理)信元:
- 有发送端发送,在数据信元中间隔插入
- RM信元中的比特被交换机设置(“网络辅助”)
- NI bit:no increase in rate(轻微拥塞)速率不要增加了
- CI bit:congestion indication 拥塞指示
- 发送端发送的 RM 信元被接收端返回,接收端不做任何改变
- 在 RM 信元中的 2 个字节 ER(explicit rate)字段
- 拥塞的交换机可能会降低信元中 ER 的值
- 发送端发送速度因此是最低的可支持速率
- 数据信元中的 EFCI bit:被拥塞的交换机设置成1
- 如果在管理信元 RM 前面的数据信元 EFCI 被设置成了 1,接收端在返回的 RM 信元中设置 CI bit
TCP 拥塞控制
TCP 拥塞控制:机制
端到端的拥塞控制机制
- 路由器不向主机有关拥塞 反馈信息
- 路由器的负担较轻
- 符合网络核心简单的 TCP/IP 架构原则
- 端系统根据自身得到的信息,判断是否发生拥塞,从而采取动作
拥塞控制的几个问题:
- 如何检测拥塞
- 轻微拥塞
- 拥塞
- 控制策略
- 在拥塞发送时如何动作,降低速率
- 轻微拥塞,如何降低
- 拥塞时,如何降低
- 在拥塞缓解时如何动作,增加速率
- 在拥塞发送时如何动作,降低速率
TCP 拥塞控制:拥塞感知
发送端如何探测到拥塞?
- 某个段超时了(丢失时间):拥塞
- 超时时间到,某个段的确认没有来
- 原因1:网络拥塞(某个路由器缓冲区间没空间了,被丢弃)概率大
- 原因2:出错被丢弃了(各级错误,没有通过校验,被丢弃)概率小
- 一旦超时,就认为拥塞了,有一定误判,但是总体控制方向是对的
- 有关某个段的 3 次重复 ACK:轻微拥塞
- 段的第 1 个 ACK,正常,确认绿段,期待红段
- 段的第 2 个重复 ACK,意味着红缎的后一段收到了,蓝段乱序到达
- 段的第 2、3、4个 ACK 重复,意味着红段的后第 2、3 、4 个段收到了,橙段乱序到达,同时红段丢失的可能性很大(后面 3 个段都到了,红段都没到)
- 网络这时还能够进行一定程度的传输,拥塞但情况要必比第一种好

TCP 拥塞控制:速率控制方法
如何控制发送端发送的速率
维持一个拥塞窗口的值:
CongWin发送端限制已发送但是未确认的数据量(的上限):
LastByteSent-LastByteAcked <= CongWin从而粗略地控制发送方的往网络中注入的速率
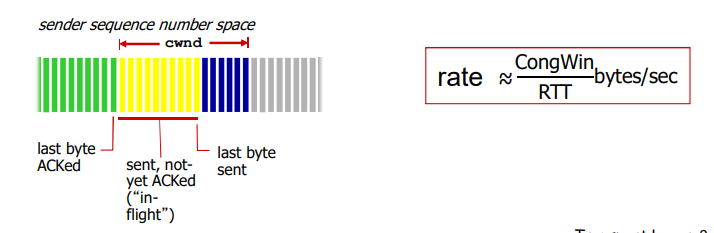
- CongWin 是动态的,是感知到的网络拥塞程度的函数
- 超时或者3个重复ACK,CongWin
- 超时时:CongWin 降为 1 MSS(最大分段大小),进入SS阶段然后在倍增到CongWin/2(每个RTT),从而进入CA阶段
- 3个重复ACK:CongWin降为 CongWin/2 ,CA阶段
- 否则(正常收到ACK,没有发送以上情况):CongWin跃跃欲试
- SS阶段:加倍增加(每个RTT)
- CA阶段:线性阶段(每个RTT)
- 超时或者3个重复ACK,CongWin
TCP拥塞控制和流量控制的联合动作
联合控制的方法:
- 发送段控制 发送但是未确认 的量同时也不能够超过接收窗口,满足流量控制要求
- SendWin = min{CongWin,RecvWin}
- 同时满足 拥塞控制 和 流量控制要求
TCP 拥塞控制:策略概述
拥塞控制策略:
- 慢启动
- AIMD:线性增、乘性减
- 超时事件后的保守策略
慢启动
连接刚建立,CongWin = 1 MSS
- 如:MSS = 1460bytes & RTT = 200 msec
- 初始速率 = 58.4 bps
可用带宽可能 >> MSS/RTT
- 应该尽快加速,到达希望的速率
当连接开始时,指数性增加发送速率,直到发生丢失的事件
启动初值很低
但是速度很快
当连接开始时,指数型增加(每个RTT)发送速率直到发生丢失事件
- 每一个RTT,ConWin 加倍
- 每收到一个 ACK 时,ConWin加1
- 慢启动阶段:只要不超时或 3 个重复ACK,一个 RTT,CongWin 加倍
总结:初始速率很慢,但是加速却是指数性的
- 指数增加,SS时间很短,长期来看可以忽略
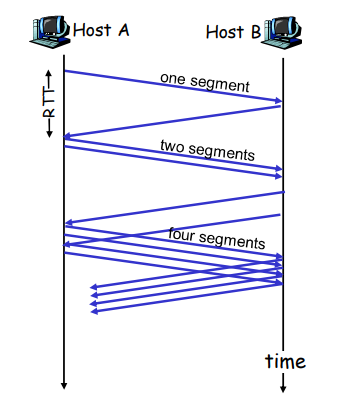
AIMD
乘性减:
丢失事件后将CongWin降为1,将CongWin/2 作为域值,进入慢启动阶段(倍增直到 CongWin/2)
加性增:
当 CongWin > 阈值时,一个 RTT 如没有发生丢失事件,将 ConWin 加 1 MSS:探测
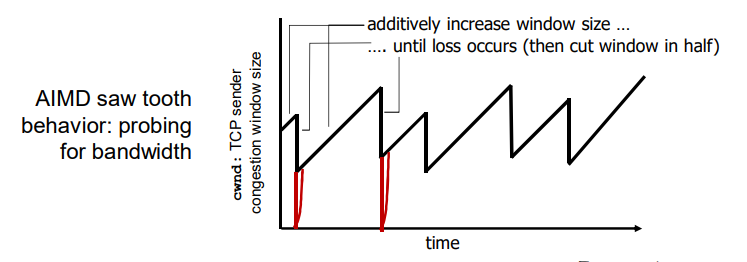
- 当收到 3个重复的ACK时:
- CongWin 减半
- 窗口(缓冲区大小)之后线性增长
- 当超时事件发生时:
- CongWin被设置成1 MSS,进入 SS 阶段
- 之后窗口指数增长
- 增长到一个阈值(上次发生拥塞的窗口的一半)时,再线性增加
思路
- 3 个重复的 ACK 表示网络还有一定的段传输能力
- 超时之前的 3 个重复的 ACK 表示 “警报“
改进
总结:TCP拥塞控制
- 当CongWin < Threshold,发送端处于慢启动阶段(slow-start),窗口指数性增长.
- 当CongWin > Threshold,发送端处于拥塞避免阶段(congestion-avoidance),窗口线性增长.
- 当收到三个重复的ACKs(triple duplicate ACK)
- Threshold设置成CongWin/2
- CongWin=Threshold+3.
- 当超时事件发生时timeout,Threshold=CongWin/2 CongWin=1 MSS,进入SS阶段
TCP 吞吐量
TCP吞吐量
- TCP的平均吞吐量是多少,使用窗口 window 尺寸 W 和 RTT 来描述?
- 忽略慢启动阶段,假设发送端总有数据传输
- W:发生丢失事件时的窗口尺寸(单位:字节)
- 平均窗口尺寸(#in-flight字节):3/4W
- 平均吞吐量:RTT时间吞吐 3/4W
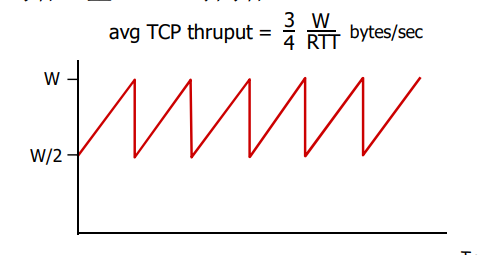
TCP未来:TCP over “long, fat pipes”

TCP 公平性
公平性目标:
如果 K 个TCP会话分享一个链路带宽为R的瓶颈,每一个会话的有效带宽为 R/K
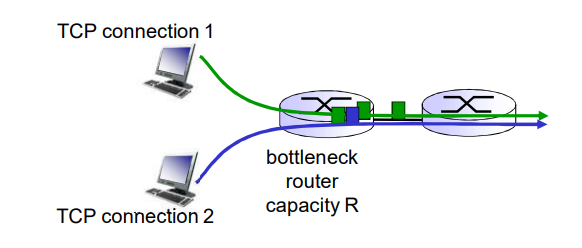
为什么TCP是公平的?
2个竞争的TCP会话:
- 加性增,斜率为1,吞吐量增加
- 乘性减,吞吐量比例减少
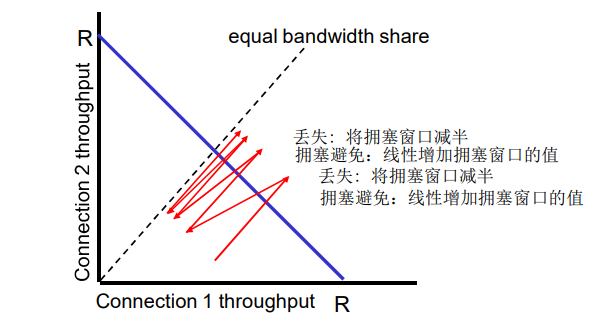
公平性和UDP
- 多媒体应用通常不是用TCP
- 应用发送的数据速率希望不受拥塞控制的节制
- 使用UDP
- 音视频应用泵出数据的速率是恒定的,忽略数据的丢失
- 研究领域:TCP友好性
公平性和并行TCP连接
- 2个主机间可以打开多个并行的TCP连接
- Web浏览器
- 例如:带宽为R的链路支持了9个连接:
- 如果新的应用要求建 1 个 TCP 连接,获得带宽 R/10
- 如果新的应用要求建 11 个 TCP 连接,获得带宽 R/2
Explicit Congestion Notification(ECN)
网络辅助拥塞控制:
- TOS字段中2个bit被网络路由器标记,用于指示是否发生拥塞
- 拥塞指示被传送到接收主机
- 在接收方-到发送方的ACK中,接收方(在IP数据报中看到了拥塞指示)设置 ECE bit,指示发送方发生了拥塞
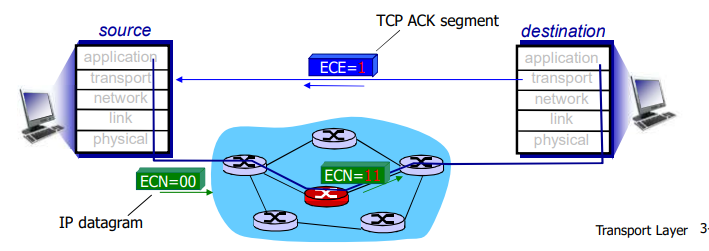
总结
传输层提供的服务
- 应用进程间的逻辑通信
- vs 网络层提供的是主机到主机的通信服务
- 互联网上传输层协议:UDP TCP
- 特性
- 应用进程间的逻辑通信
多路复用和解复用
- 端口:传输层的 SAP
- 无连接的多路复用和解复用
实例1:无连接传输层协议 UDP
- 多路复用解复用
- UDP报文格式
- 检错机制:校验和
可靠数据传输原理
- 问题描述
- 停止等待协议:
- rdt1.0 、rdt2.0、rdt2.1、rdt2.2、rdt3.0
- 流水线协议
- GBN
- SR
实例2:面向连接的传输层协议-TCP
- 概述:TCP特性
- 报文段格式
- 序号,超时机制及时间
- TCP可靠传输机制
- 重传,快速重传
- 流量控制
- 连接管理
- 三次握手
- 对称连接释放
拥塞控制原理
- 网络辅助的拥塞控制
- 端到端的拥塞控制
TCP的拥塞控制
- AIMD
- 慢启动
- 超市之后的保守策略
网络层:数据平面
导论
本章目标
- 理解网络服务的基本原理,聚焦于其数据平面
- 网络服务模型
- 转发和路由
- 路由器工作原理
- 通用转发
- 互联网中网络层协议的实例和实现
网络层服务
- 在发送主机和接收主机对之间传送段(segment)(包)
- 在发送端将段封装到数据报中
- 在接收端,将段上交给传输层实体
- 网络层协议存在于每一个主机和路由器
- 路由器检查每一个经过它的IP数据报的头部
网络层的关键功能
网络层功能:
- 转发:将分组从路由器的输入接口转发到合适的输出接口
- 路由:使用路由算法来决定分组从发送主机到目标接收主机的路径
- 路由选择算法
- 路由选择协议
旅行的类比:
- 转发:通过单个路口的过程
- 路由:从源到目的的路由规划过程
网络层:数据平面、控制平面
数据平面:
- 本地,每个路由器功能
- 决定从路由器输入端口到达的分组如何转发到输出端口
- 转发功能:
- 传统方式:基于目标地址 + 转发表
- SDN方式:基于多个字段 + 流表
控制平面:
- 网络范围内的逻辑
- 决定数据报如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径
- 2 个控制平面方法:
- 传统的路由算法:在路由器中被实现
software-defined networking(SDN):在远程的服务器中实现
传统方式:每-路由器(Per-router)控制平面
在每一个路由器中的单独路由器算法元件,在控制平面进行交互
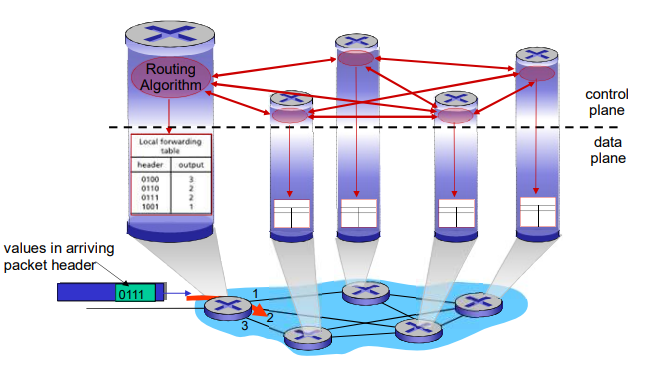
传统方式:路由和转发的相互作用
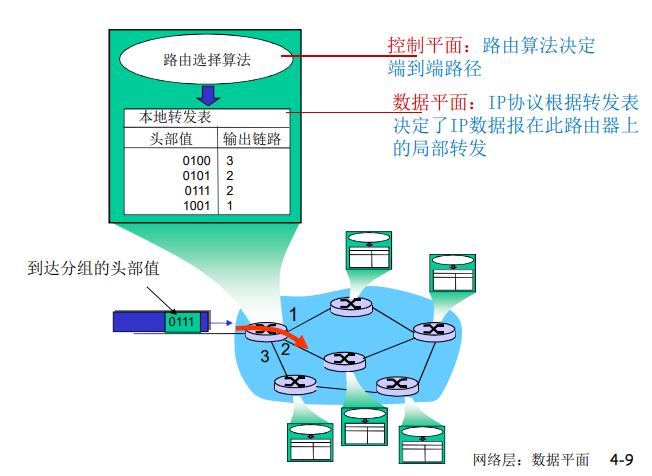
SDN方式:逻辑集中的控制平面
一个不同的(通常是远程的)控制器与本地控制代理(CAs)交互
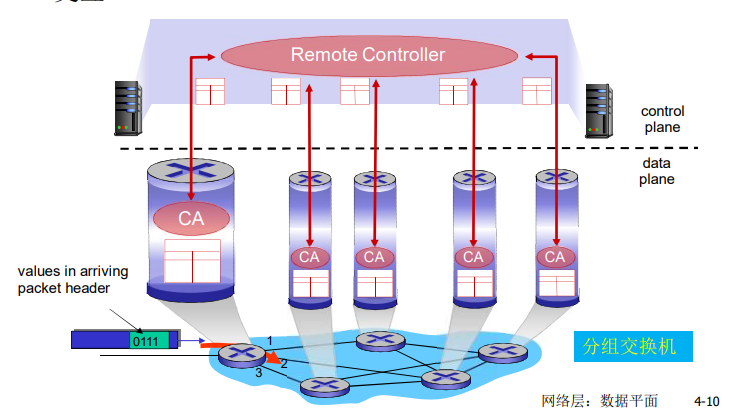
网络服务模型
Q:从发送方主机到接收方主机传输数据报的 ”通道“,网络提供什么样的服务模型?
对于单个数据报的服务:
- 可靠传送
- 延迟保证,如:少于40ms的延迟
对于数据报流的服务:
- 保序数据报的传送
- 保证流的最小带宽
- 分组之间的延迟差
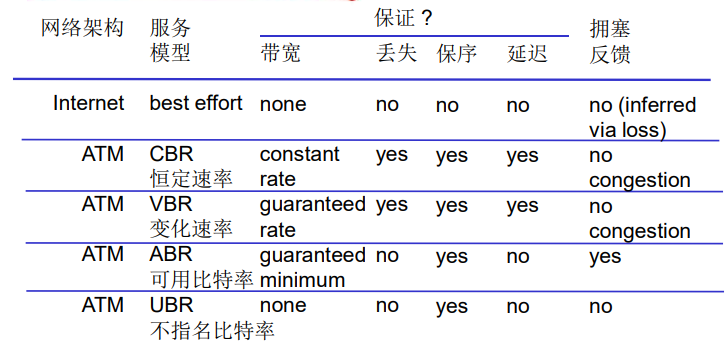
连接建立
- 在某些网络架构中是第三个重要的功能
- ATM、frame relay、X.25
- 在分组传输之前,在两个主机之间,在通过一个路由器所构成的路径上建立一个网络层连接
- 涉及到路由器
- 网络层和传输层连接服务区别:
- 网络层:在 2 个主机之间,涉及到路径上的一些路由器
- 传输层:在 2 个进程之间,很可能只体现在端系统上(TCP连接)
路由器组成
路由器结构概况
高层面(非常简化的)通用路由器体系架构
- 路由:运行路由选择算法/协议(RIP、OSPF、BGP)- 生成路由表
- 转发:从输入到输出链路交换数据报 - 根据路由表进行分组的转发
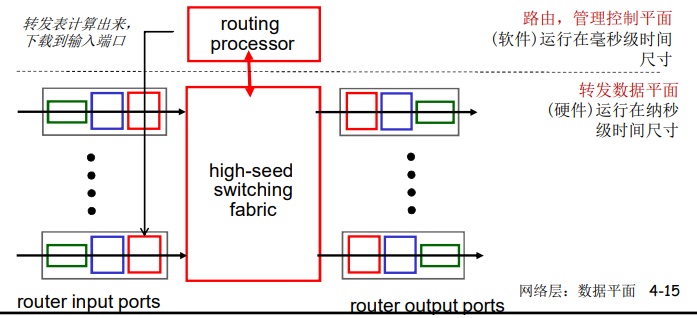
输入端口处理和基于目的地转发
输入端口功能
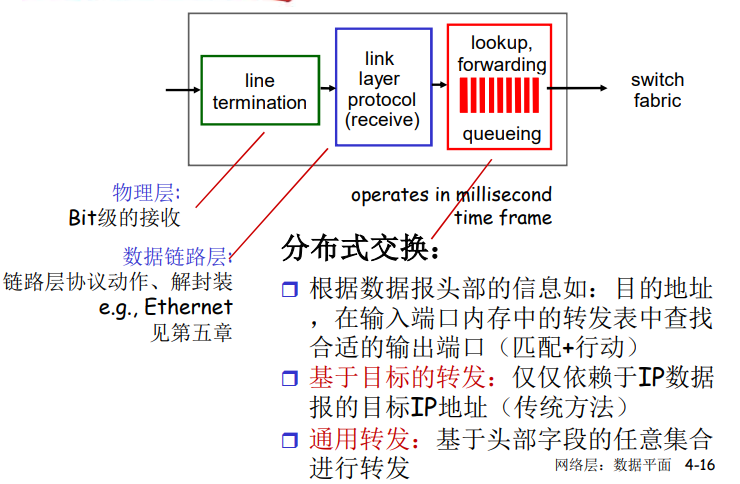
基于目标的转发:
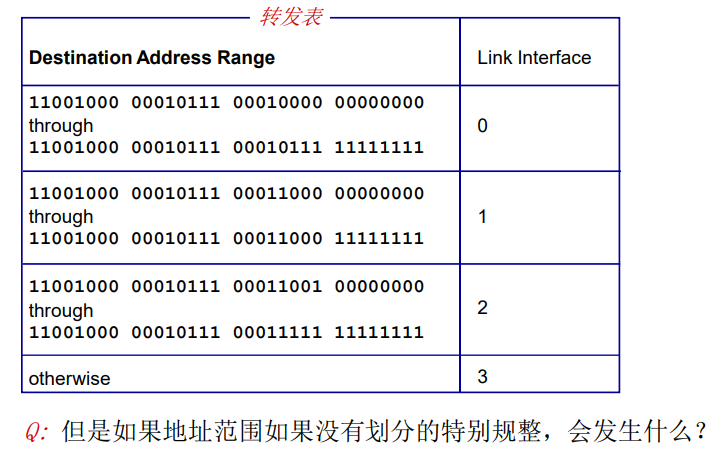
最长前缀匹配
当给定目标地址查找转发表时,采用最长地址前缀匹配的目标地址表项
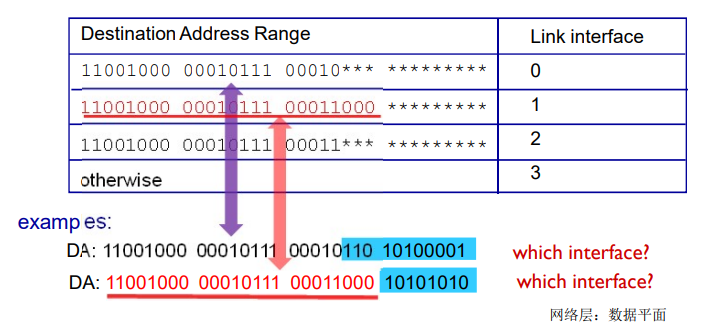
- 我们将会在学习IP地址时,简单讲解为什么要采用最长前缀匹配
- 最长前缀匹配:在路由器中经常采用 TCAMs(ternary content addressable memories)硬件来完成
- 内容可寻址:将地址交给 TCAM,它可以在一个时钟周期内检索出地址,不管表空间有多大
- Cisco Catalyst 系列路由器:在 TCAM中可以存储多达约为 1百万条路由表项
输入端口缓存
- 当交换机构的速率小于输入端口的汇聚速率时 -> 在输入端口可能要排队
- 排队延迟以及由于输入缓存溢出造成丢失!
- Head-of-the-Line(HOL)blocking:排在队头的数据报组织了队列中其他数据报向前移动
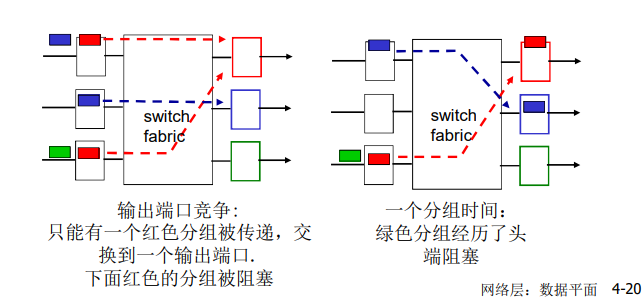
交换
交换结构
- 将分组从输入缓冲区传输到合适的输出端口
- 交换速率:分组可以按照该速率从输入传输到输出
- 运行速度经常是输入/输出链路速率的若干倍
- N 个输入端口:交换机构的交换速度是输入线路速度的 N 倍比较理想,才不会成为瓶颈
- 3 种典型的交换机构
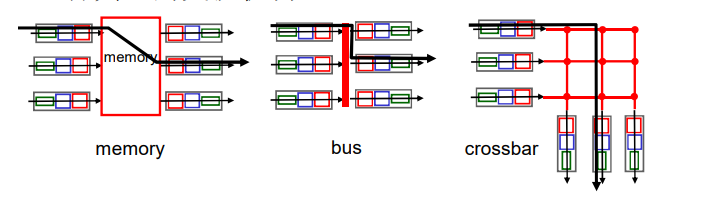
通过内存交换
第一代路由器:
- 在 CPU 直接控制下的交换,采用传统的计算机
- 分组被拷贝到系统内存,CPU 从分组的头部提取出目标地址,查找转发表,找到对应的输出端口,拷贝到输出端口
- 转发速率被内存的带宽限制(数据报通过 BUS 两遍)
- 一次只能转发一个分组
在计算机网络中,通过内存交换方式转发数据时,数据包需要从输入端口经过总线(BUS)传输到输出端口,然后再通过输出端口发送出去。这个总线(BUS)指的是计算机硬件中的总线,用于连接计算机各个组件、传输数据和控制信号。在数据包传输时,总线(BUS)的带宽限制会影响数据包的传输速率,从而影响网络的性能。因此,总线(BUS)的带宽是一个重要的性能指标,需要根据实际情况进行优化和调整。
通过总线交换
- 数据报通过共享总线,从输入端口转发到输出端口
- 总线竞争:交换速度受限于总线带宽
- 1 次处理一个分组
- 1 Gbps bus ,Cisco 1900 ;32 Gbps bus,Cisco 5600;对于接入或企业级路由器,速度足够(但不适合区域或骨干网络)
通过互联网络(crossbar等)的交换
- 同时并发转发多个分组,克服总线带宽限制
- Banyan(榕树)网络,crossbar(纵横)和其他的互联网络被开发,将多个处理器连接成多处理器
- 当分组从端口A到达,转给端口Y;控制器短接相应的两个总线
- 高级设计,将数据报分片为固定长度的信元,通过交换网络交换
- Cisco12000:以 60Gbps的交换速率通过互联网络
输出端口
输出端口处理
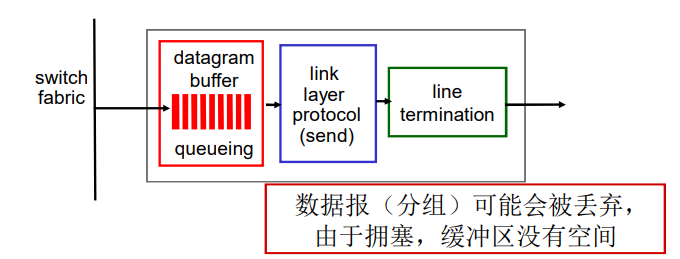
- 当数据报从交换机构的到达速度比传输速率快就需要输出端口缓存
- 数据报(分组)可能会被丢弃,由于拥塞、缓冲区没有空间
- 由调度规则选择排队的数据报进行传输
输出端口排队
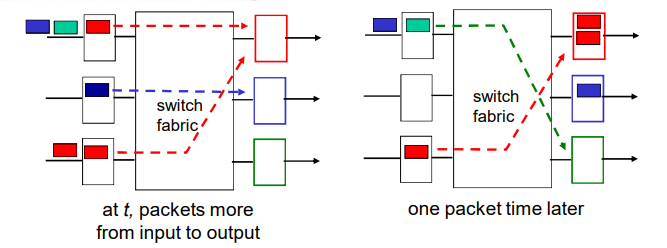
- 假设交换速率 R(switch) 是 R(line) 的N倍(N:输入端口的数量)
- 当多个输入端口同时向输出端口发送时,缓冲该分组(当通过交换网络到达的速率超过输出速率则缓存)
- 排队带来延迟,由于输出端口缓存溢出则丢弃数据报!
需要多少缓存?

调度机制
调度:选择下一个要通过链路传输的分组
FIFO:(first in first out)scheduling:按照分组到来的次序发送,先来先服务。
例子:
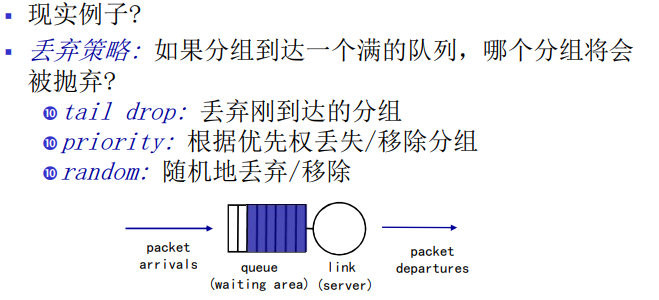
调度策略:优先权
优先权调度:发送最高优先权的分组
- 多类,不同类别由不同的优先权
- 类别可能依赖于标记或者其他的头部字段,e.g. IP source/dest,port numbers ,ds,etc.
- 先传高优先级的队列中的分组,除非没有
- 高(低)优先权中的分组传输次序:FIFO
调度策略:其他的
Round Robin (RR) scheduling:(轮转调度算法)
- 多类
- 循环扫描不同类型的队列,发送完一类的一个分组,再发送下一个类的一个分组,循环所有类。
Weighted Fair Queuing(WFQ):
一般化的 Round Robin
在一段时间内,每个队列得到的服务时间是:
 ,和权重成正比
,和权重成正比每个类在一个循环中获得不同的权重的服务量
IP:网际协议
互联网的网络层
- 主机、路由器中的网络层功能:
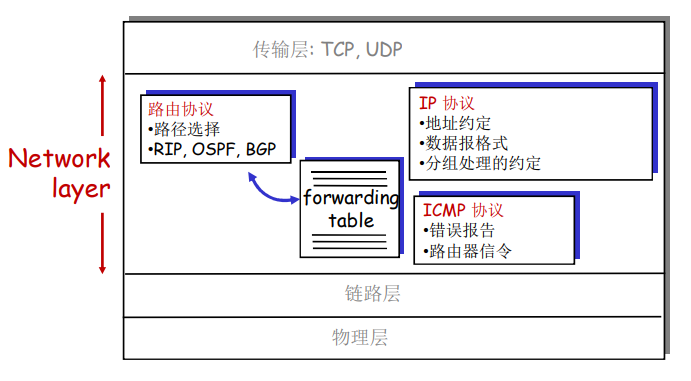
IP数据报格式
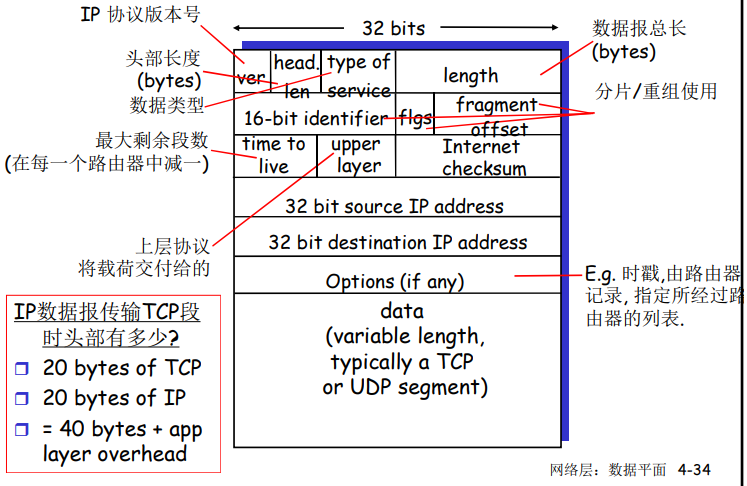
IP分片和重组
分片和重组(Fragmentation & Reassmbly)
网络链路有MTU(最大传输单元)- 链路层帧所携带的最大数据长度
不同的链路类型
不同的 MTU
大的IP数据报在网络上被分片(fragmented)
- 一个数据报被分割成若干个小的数据报
- 相同的ID
- 不同的偏移量
- 最后一个分片标记为0
- “重组” 只在最终的目标主机进行
- IP 头部的信息被用于标识,排序相关分片
- 一个数据报被分割成若干个小的数据报
例子:
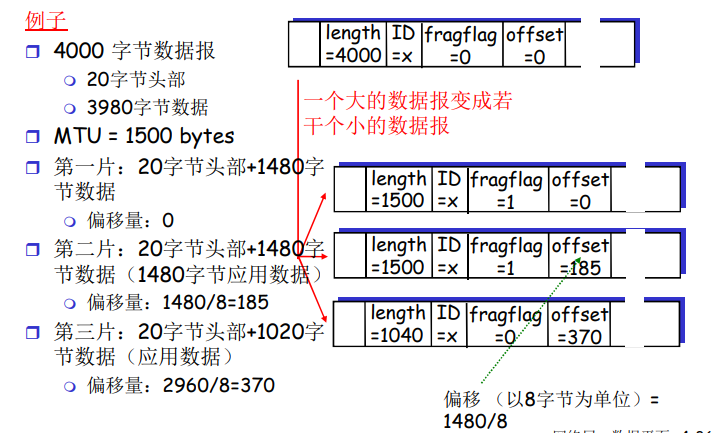
IPv4地址
编址:引论
- IP地址:32位标示,对主机或者路由器的接口编址
- 接口:主机/路由器和物理链路的连接处
- 路由器通常拥有多个接口
- 主机也有可能有多个接口
- IP地址和每一个接口关联
- 一个IP地址和一个接口相关联
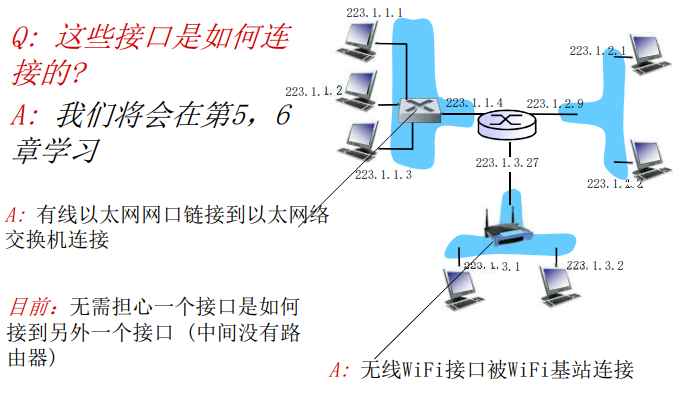
子网(Subnets)
- IP地址:
- 子网部分(高位bits)
- 主机部分(地位bits)
- 什么是子网(subnet)?
- 一个子网内的节点(主机或者路由器)它们的IP地址和高位部分相同,这些节点构成的网络的一部分叫做子网。
- 无需路由器介入,子网内各主机可以在物理上相互直接到达。
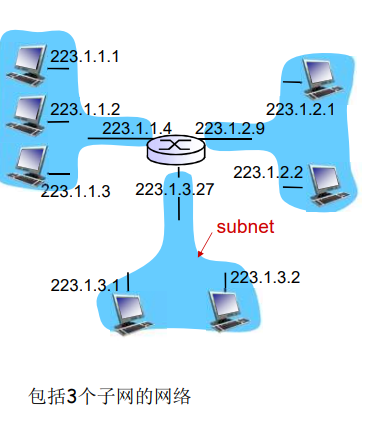
方法:
- 要判断一个子网,将每一个接口从主机或者路由器上分开,构成了一个个网络的孤岛
- 每一个孤岛(网络)都是一个都可以被称之为 子网(subnet)
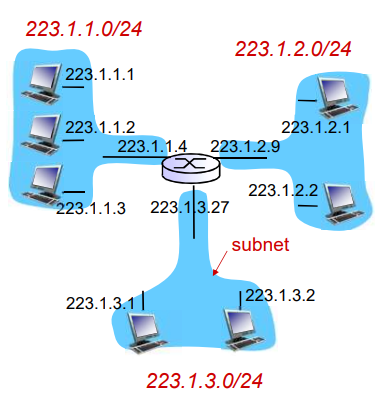
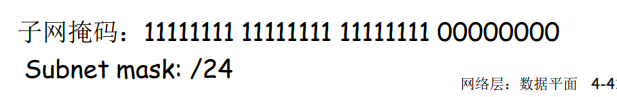
IP地址分类

特殊的IP地址
- 一些约定:
- 子网部分:全为 0 —- 本网络
- 主机部分:全为0 —– 本主机
- 主机部分:全为1 —— 广播地址,这个网络的所有主机
- 特殊 IP 地址
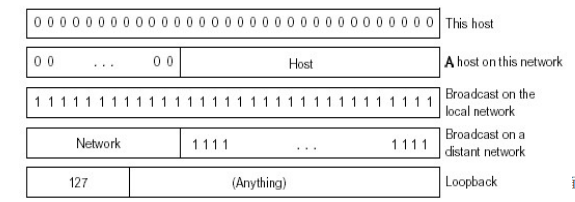
内网(专用)IP地址
专用地址:地址空间的一部分供专用地址使用
永远不会被当做公用地址来分配,不会与公用地址重复
- 只在局部网络中有意义,区分不同的设备
路由器不对目标地址是专用地址的分组进行转发
专用地址范围

IP编址:CIDR
CIDR:Classless InterDomain Routing(无类域间路由)
子网部分可以在任意的位置
地址格式: a.b.c.d/x,其中 x 是 地址中子网号的长度

子网掩码(subnet mask)

转发表和转发算法
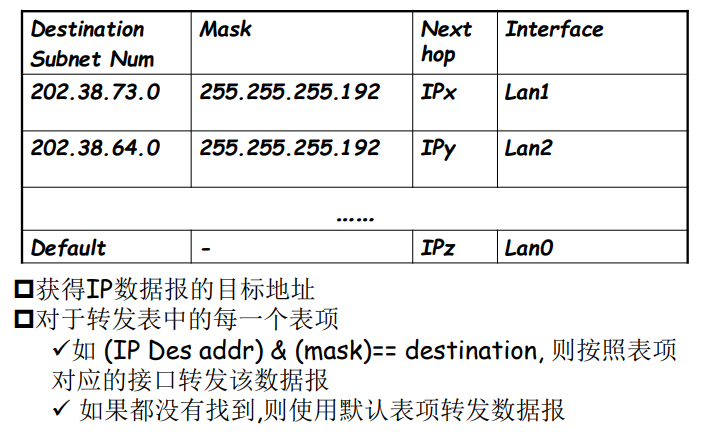
如何获得一个IP地址

DHCP:Dynamic Host Configuration Protocol
目标:允许主机在加入网络的时候,动态地从服务器那里获得IP地址:
- 可以更新对主机在用IP地址的租用期 - 租期快到了
- 重新启动时,允许重新使用以前用过的IP地址
- 支持移动用户加入到该网络(短期在网)
DHCP工作概况:
- 主机广播 “DHCP discover”报文 [可选]
- DHCP 服务器用 “DHCP offer” 提供报文响应 [可选]
- 主机请求IP地址:发送 “DHCP request” 报文
- DHCP服务器发送地址:“DHCP ack”报文
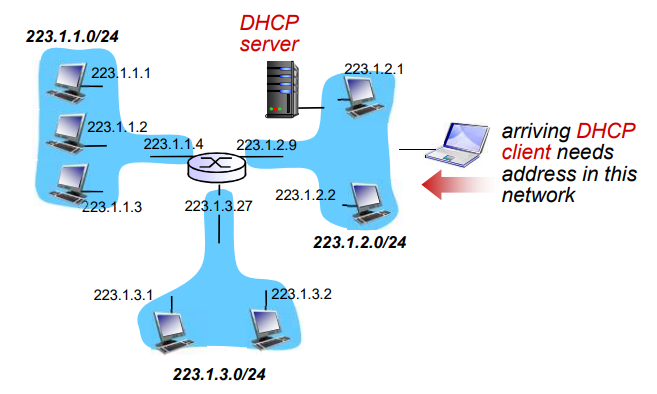
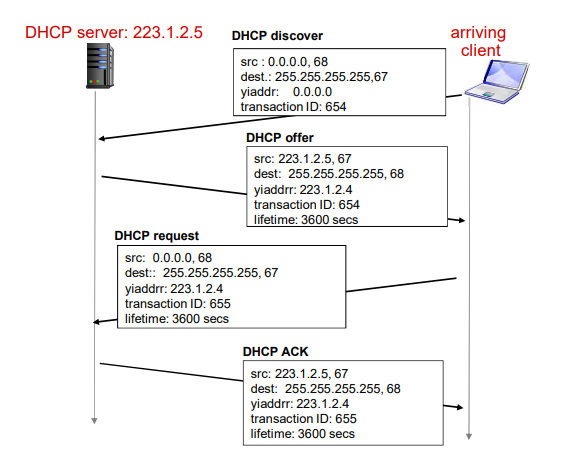
DHCP:不仅仅是 IP adresses
DHCP 返回:
IP地址
第一跳路由器的 IP地址(默认网关)
DNS服务器的域名和 IP 地址
子网掩码(指示地址部分的网络号和主机号)
DHCP:实例
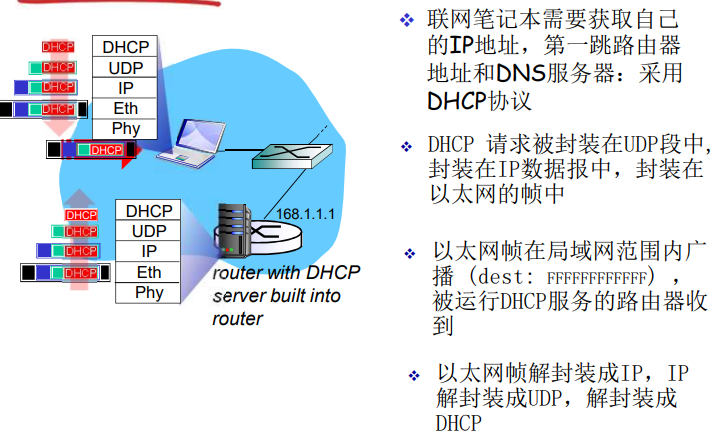
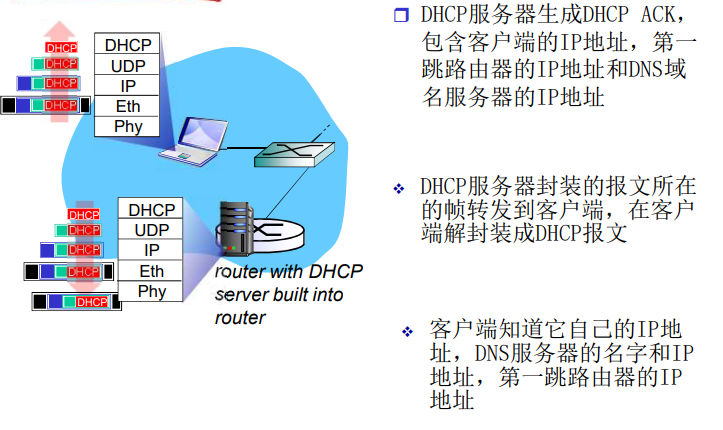
DHCP:Wireshark 输出(home LAN)

如何获得一个IP地址

层次编址:路由聚集(route aggregation)
层次编址允许路由信息的有效广播:
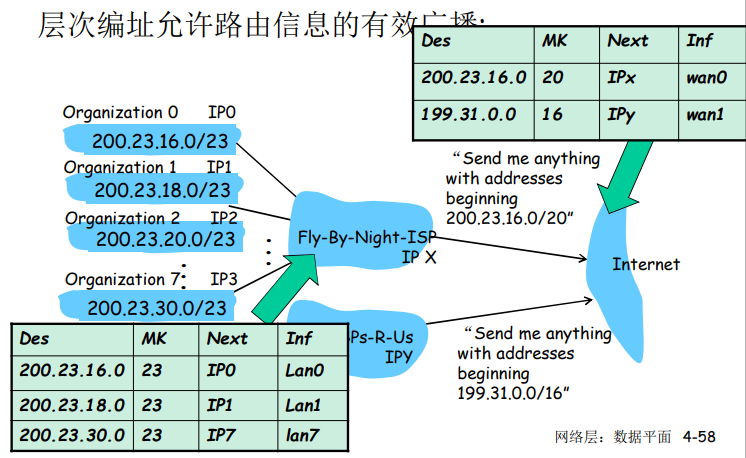
层次编址:特殊路由信息(more specific routes)
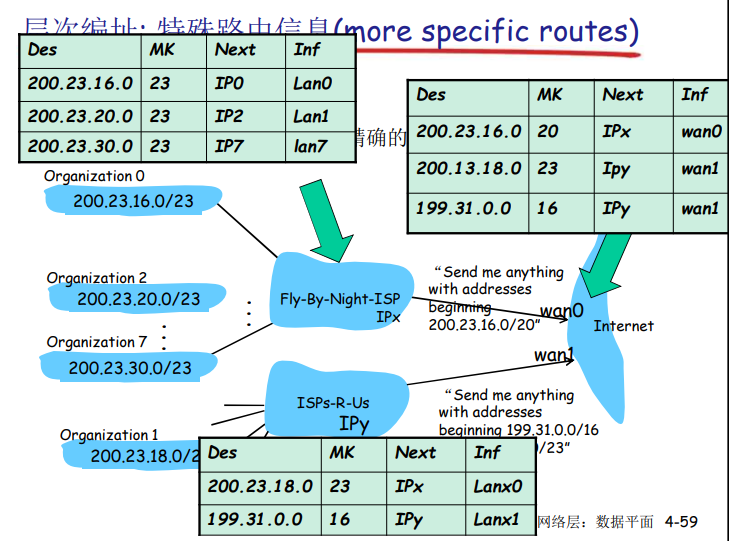
IP编址:如何获得一块地址
Q:一个ISP如何获得一个地址块?
A:ICANN:Internet Corporation for Assigned Names and Numbers
- 分配地址
- 管理DNS
- 分配域名,解决冲突
网络地址转换
NAT:Network Address Translation
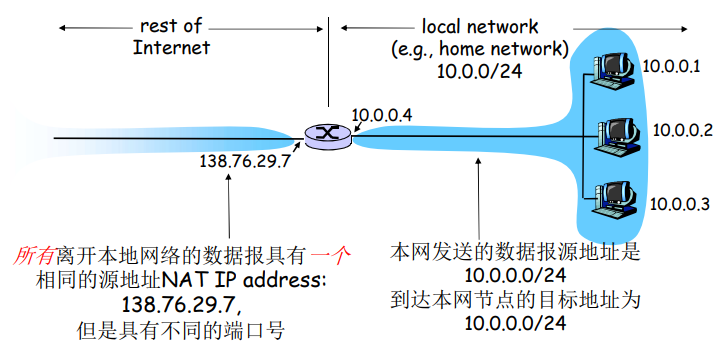
动机:本地网络只有一个有效IP地址:
- 不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备 — 省钱
- 可以在局域网改变设备的地址情况下而无须通知外界
- 可以改变ISP(地址变化)而不需要改变内部的设备地址
- 局域网内部的设备没有明确的地址,对外是不可见的 — 安全
实现:NAT路由器必须:
外出数据包:替换原地址和端口号为 NAT IP地址和新的端口号,目标IP和端口不变
远端的 C/S 将会用 NAP IP 地址,新端口号作为目标地址
记住每个轮转替换对(在 NAT 转换表中)
… 源IP、端口 vs NAP IP,新端口
进入数据包:替换目标IP地址和端口号,采用存储在 NAT 表中的 mapping 表项,用(源IP、端口)
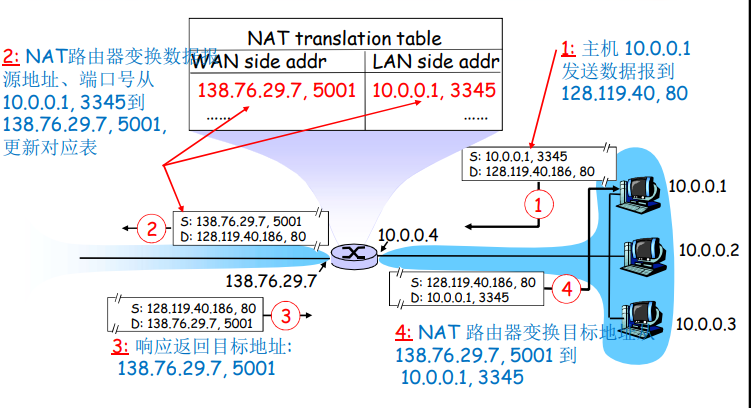
16-bit 端口字段:
- 6 万多个同时连接,一个局域网!
对NAT是有争议的:
路由器只应该对第 3 层做信息处理,而这里对端口号(4层)作了处理
违反了 end-to-end 原则
端到端原则:复杂性放到网络边缘
无需借助中转和变换,就可以直接传送到目标主机
NAT可能要被一些应用设计者考虑,eg, P2P applications
外网的机器无法主动连接到内网的机器上
地址短缺问题可以被 IPv6 解决
NAT穿越:如果客户端需要连接在 NAT 后面的服务器,如何操作
NAT穿越问题

IPv6
动机
- 初始动机:32-bit地址空间将会被很快用完
- 另外的动机:
- 头部格式改变帮助加速处理和转发
- TTL - 1 (TTL是生存时间,RTT是往返时延)
- 头部 checksum
- 分片
- 头部格式改变帮助 QoS
- 头部格式改变帮助加速处理和转发
IPv6 数据报格式:
- 固定的 40 字节头部
- 数据报传输过程中,不允许分片
IPv6 头部(Cont)
Priority:标示流中数据报的优先级
Flow Label:标示数据报在一个 “flow”(flow 的概念没有被严格的定义)
Next header:标示上层协议
和IPv4的其他变化
- Checksum:被移除掉,降低在每一段中的处理速度
- Options:允许,但是在头部之外,被 “Next Header” 字段标示
- ICMPv6:ICMP的新版本
- 附加了报文类型 e.g. “Packet Too Big”
- 多播组管理功能
从IPv4到IPv6的平移
- 不是所有的路由器都能够同时升级的
- 没有一个标记日 “flag days”
- 在IPv4和IPv6路由器混合时,网络如何运转?
- 隧道:在IPv4路由器之间传输的IPv4 数据报中携带IPv6数据报
隧道(Tunneling)
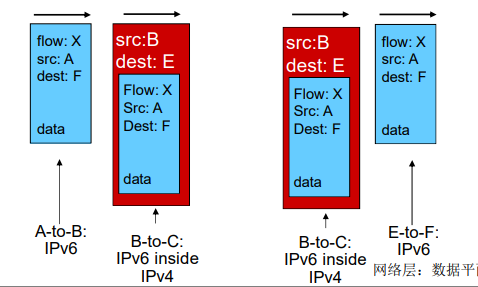
通用转发和SDN
网络层功能为例的数据平面和控制平面
网络层功能:
- 转发:对于从某个端口到来的分组转发到合适的输出端口
- 路由:决定分组从源端到目标端的路径
- 路由算法
类比:旅行
- 转发:一个多岔路口进入和转出过程
- 路由:规划从源到目标的旅行路径
数据平面:
- 本地的、每个路由器的功能
- 决定某个从某个端口进入的分组从哪个端口输出
- 转发功能
控制平面:
- 网络范围的逻辑
- 决定分组端到端穿行于各个路由器的路径
每个路由器(Per Route)的控制平面
每个路由器上都有实现路由算法元件(它们之间需要相互交互) - 形成传统IP实现方式的控制平面
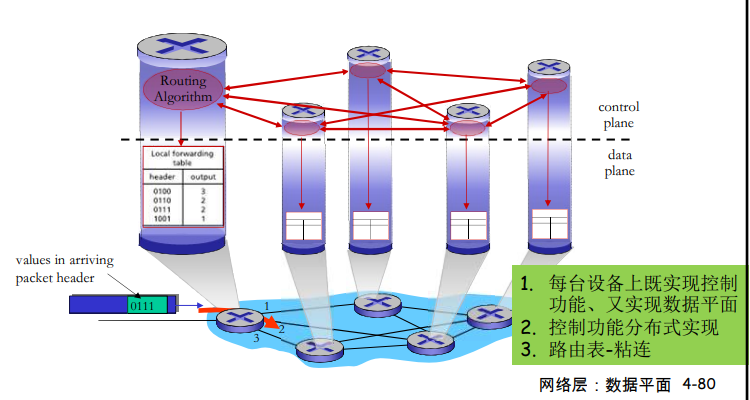
数量众多、功能各异的中间盒
- 路由器的网络层功能:
- IP转发:对于到来的分组按照路由表决定如何转发,数据平面
- 路由:决定路径,计算路由表;处在控制平面
- 还有其他种类繁多网络设备(中间盒):
- 交换机;防火墙;NAT;IDS;负载均衡设备
- 未来:不断增加的需求和相应的网络设备
- 需要不同的设备去实现不同的网络功能
- 每台设备集成了控制平面和数据平面的功能
- 控制平面分布式地实现了各种控制平面功能
- 升级和部署网络设备非常困难
网络设备控制平面的实现方式特点
- 互联网网络设备:传统方式都是通过分布式,每台设备的方法来实现数据平面和控制平面功能
- 垂直集成:每台路由器或其他网络设备,包括:
- (1)硬件、在私有的操作系统;
- (2)互联网标准协议(IP、RIP、IS-IS,OSPF,BGP)的私有实现
- 从上到下都由一个厂商提供(代价大,被设备上 ”绑架“)
- 每个设备都实现了数据平面和控制平面的事情
- 控制平面的功能是分布式实现的
- 设备基本上只能(分布式升级困难)按照固定方式工作,控制逻辑固化。不同的网络功能需要不同的 “middleboxes” :防火墙、负载均衡设备、NAT boxes,…
- 垂直集成:每台路由器或其他网络设备,包括:
- (数据 + 控制平面)集成 > (控制逻辑)分部 -> 固化
- 代价大;升级困难;管理困难等
传统方式实现网络功能的问题
问题:
- 垂直集成 > 昂贵、不便于创新的生态
- 分布式、固化设备功能 == 网络设备种类繁多
- 无法改变路由等工作逻辑,无法实现流量工程等高级特性
- 配置错误影响全网运行;升级和维护会涉及到全网设备:管理困难
- 要增加新的网络功能,需要设计、实现以及部署新的特定设备,设备种类繁多
~2005:开始重新思考网络控制平面的处理方式
- 集中:远程的控制器集中实现控制逻辑
- 远程:数据平面和控制平面的分离
SDN:逻辑上集中的控制平面
一个不同的(通常是远程)控制器和CA交互,控制器决定分组转发的逻辑(可编程),CA所在设备执行逻辑。
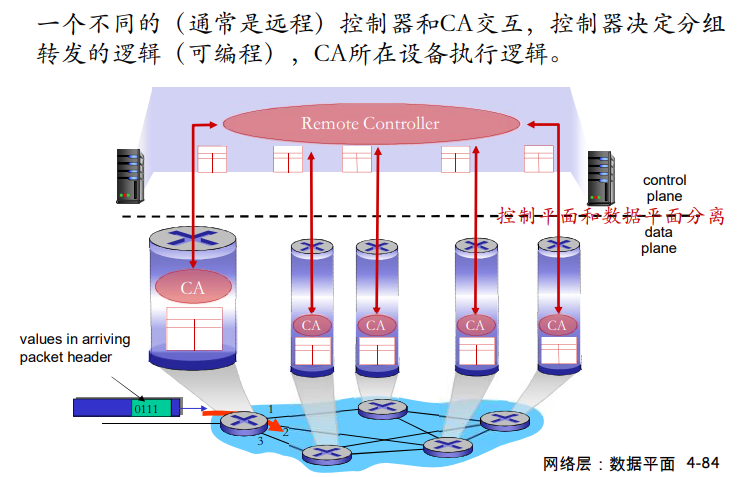
SDN的主要思路:
- 网络设备数据平面和控制平面分离
- 数据平面 - 分组交换机
- 将路由器、交换机和目前大多数网络设备的功能进一步 抽象 成:按照流标(由控制平面设置的控制逻辑)进行PDU(帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻塞)
- 统一化 设备功能:SDN交换机(分组交换机),执行控制逻辑
- 控制平面 = 控制器 + 网络应用
- 分离、集中
- 计算和下发控制逻辑:流表
SDN控制平面和数据平面分离的优势:
- 水平集成控制平面的开放实现(而非私有实现),创造出好的产业生态,促进发展
- 分组交换机、控制器和各种控制逻辑网络应用 app 可由不同厂商生产,专业化,引入竞争形成良好生态
- 集中式实现控制逻辑,网络管理容易:
- 集中式控制器了解网络状况,编程简单,传统方式困难
- 避免路由器的误配置
- 基于流表的 匹配 + 行动 的工作方式允许 “可编程的” 分组交换机
- 实现流量工程等高级特性
- 在此框架下实现各种新型(未来)的网络设备
类比:主框架到PC的演变
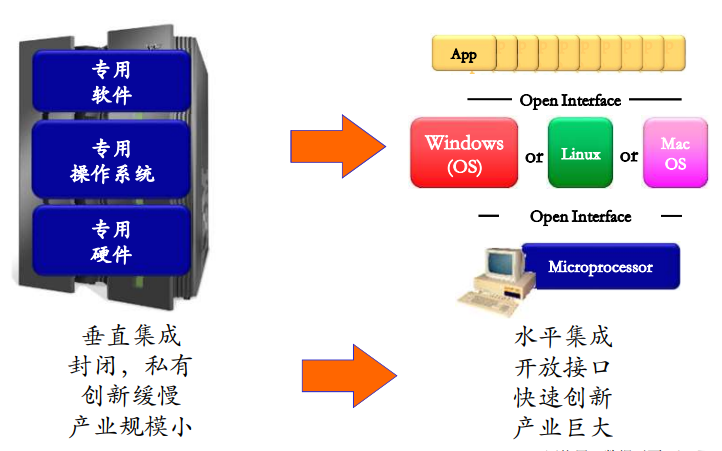
流量工程:传统路由比较困难
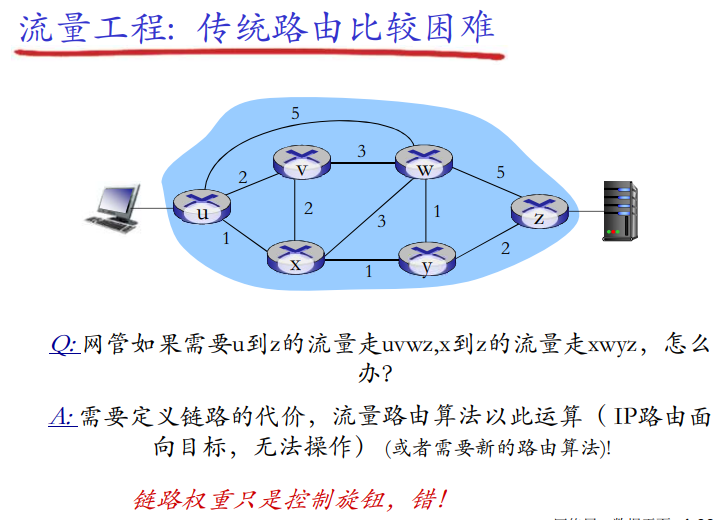
流量控制:困难
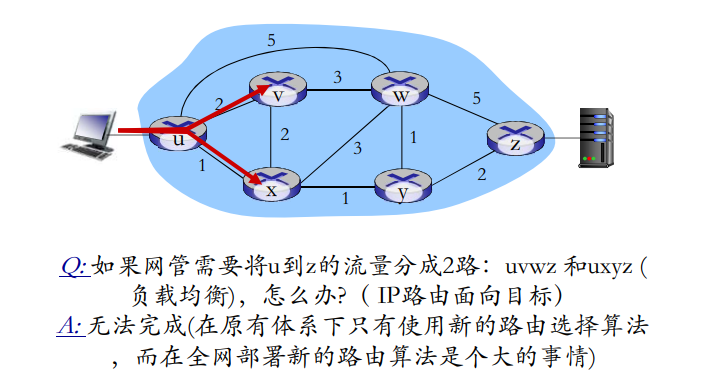
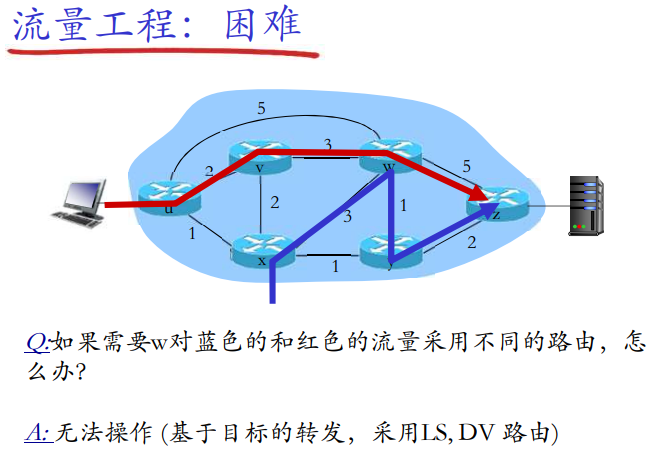
SDN特点
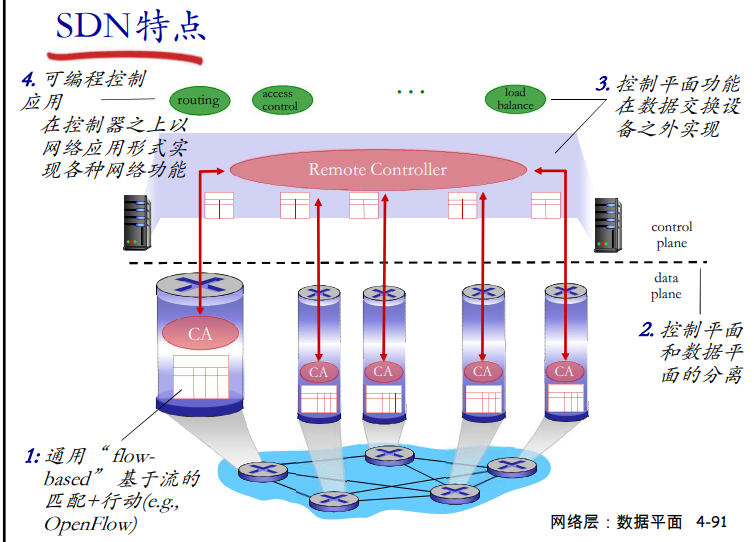
SDN架构:数据平面交换机
数据平面交换机
- 快速,简单,商业化交换设备采用硬件实现通用转发功能
- 流表被控制器计算和安装
- 基于南向API(例如OpenFlow),SDN控制器访问基于流的交换机
- 定义了哪些可以被控制哪些不能
- 也定义了和控制器的协议(e.g. ,OpenFlow)
SDN架构:SDN控制器
SDN控制器(网络OS):
维护网络状态信息
通过上面的北向 API 和网络控制应用交互
通过下面的南向 API 和网络交换机交互
逻辑上集中,但是在实现上通常用于性能、可扩展性、容错性以及鲁棒性采用分布式方法
SDN架构:控制应用
网络控制应用:
控制的大脑:采用下层提供的服务(SDN控制器提供的 API),实现网络功能
- 路由器 交换机
- 接入控制 防火墙
- 负载均衡
- 其他功能
非绑定:可以被第三方提供,与控制器厂商可以通常上不同,与分组交换机厂商也可以不同
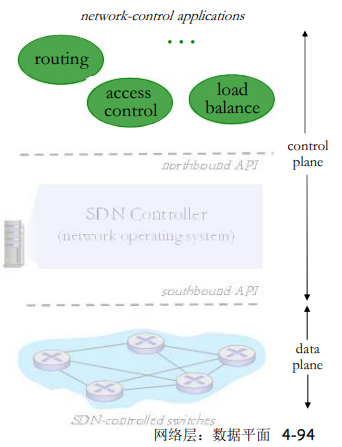
通用转发和SDN
每个路由器包含一个流表(被逻辑上集中的控制器计算和分发)
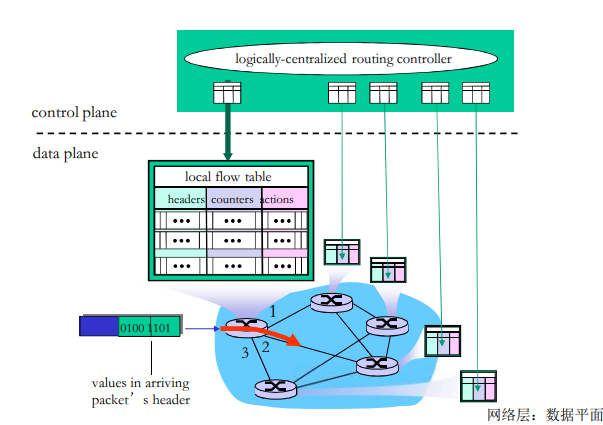
OpenFlow数据平面抽象
流:由分组(帧)头部字段所定义
通用转发:简单的分组处理规则
- 模式:将分组头部字段和流表进行匹配
- 行动:对于匹配上的分组,可以是 丢弃、转发、修改、将匹配的分组发送给控制器
- 优先权:Priority:几个模式匹配了,优先采用哪个,消除歧义
- 计数器(Counters):#bytes 以及 #packets
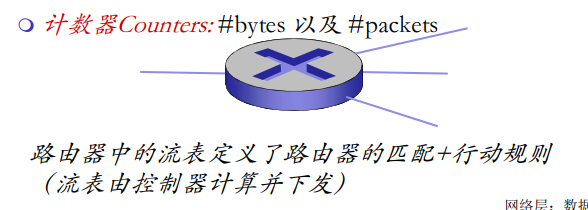
防火墙的实践:

OpenFlow:流表的表项结构
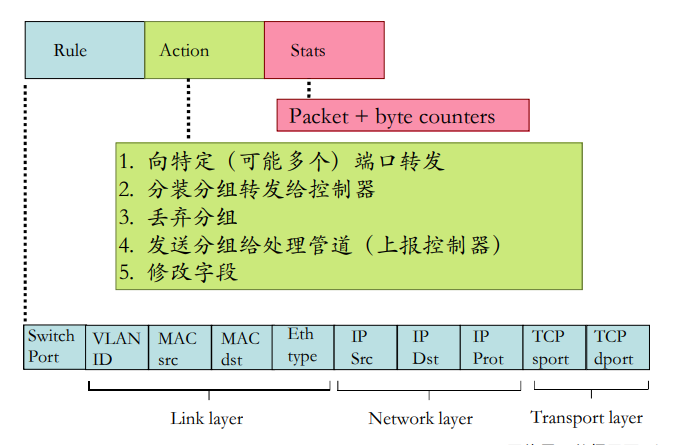
例子:
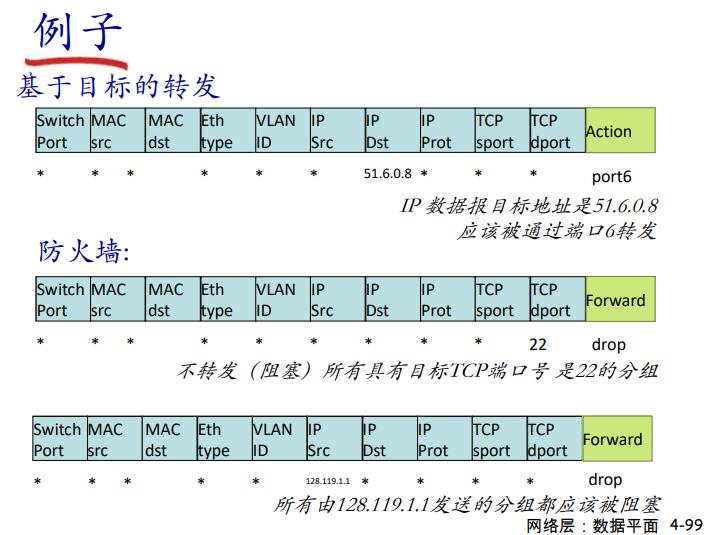
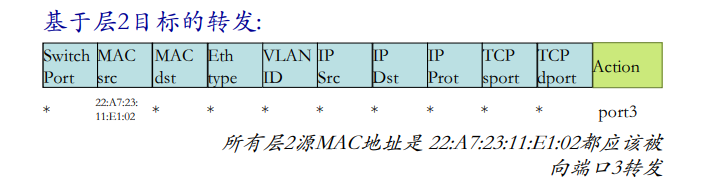
OpenFlow抽象
- match + action :统一化各种网络设备提供的功能
- 路由器
- match:最长前缀匹配
- action:通过一条链路转发
- 交换机
- match:目标MAC地址
- action:转发或者泛洪
- 防火墙
- match:IP地址和 TCP/UDP端口号
- action:允许或者禁止
- NAT
- match:IP地址和端口号
- action:重写地址和端口号
目前几乎所有的网络设备都可以在这个 匹配+行动模式 框架进行描述,具体化为各种网络设备包括未来的网络设备。
OpenFlow 例子
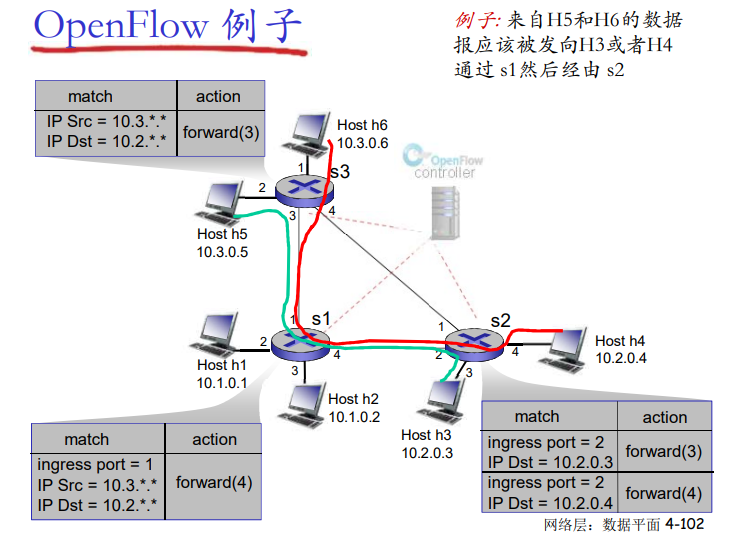
网络层:控制平面
本章目标:理解网络层控制平面的工作原理
- 传统路由选择算法
- SDN 控制器
- ICMP:Internet Control Message Protocol :因特网控制报文协议,是TCP/IP协议族的一个字协议,用于在 Internet Protocol(IP)网络中传递控制信息和错误消息
以及他们在互联网上的实例和实现:
- OSPF、OpenFlow、ODL 和 ONOS 控制器,ICMP、SNMP
控制平面
回顾:2个网络层功能:
转发:将分组从路由器的一个输入端口移到合适的输出端口(数据平面)
路由:确定分组从源到目标的路径 (控制平面)
两种构建网络控制平面功能的方法:
每个路由器控制功能实现(传统)
逻辑上集中的控制功能实现(software defined networking)
传统方式:每 - 路由器(Per-router)控制平面
在 每一个路由器 中的单独路由器算法元件,在控制平面进行交互
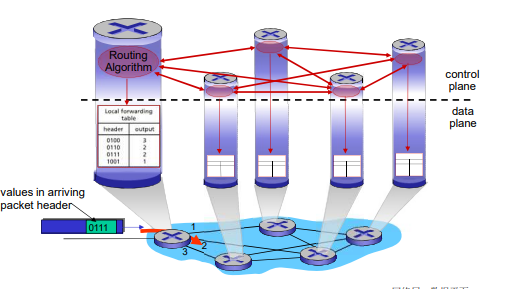
SDN方式:逻辑上集中的控制平面
一个不同的(通常是远程的)控制器与本地控制代理(CAs)交互
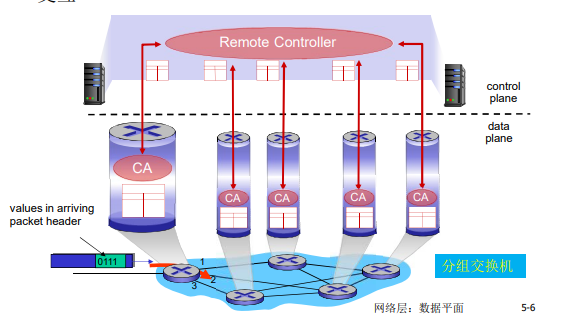
路由选择算法
路由(route)
路由的概念:
路由:按照某种指标(传输延迟,所经过的站点数目)找到一条从源节点到目标节点的较好路径
- 较好路径:按照某种指标较小的路径
- 指标:站数、延迟、费用,队列长度等,或者是一些单纯指标的加权平均
- 采用什么样的指示,表示网络使用者希望网络在什么方面表现突出,什么指标网络使用者比较重视
以网络为单位进行路由(路由信息通告 + 路由计算)
- 网络为单位进行路由,路由信息传输、计算和匹配的代价低
- 前提条件是:一个网络所有节点地址前缀相同,且物理上聚集
- 路由就是:计算 网络 到 其他网络 如何走的问题
网络到网络的路由 = 路由器 - 路由器 之间路由
- 网络对应的路由器到其他网络对应的路由器的路由
- 在一个网络中:路由器 - 主机之间的通信,链路层解决
- 到了这个路由器就是到了这个网络
路由选择算法(routing algorithm):网络层软件的一部分,完成路由功能
网络的图抽象
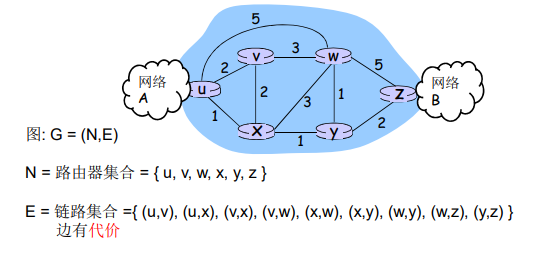
图抽象:边和路径的代价
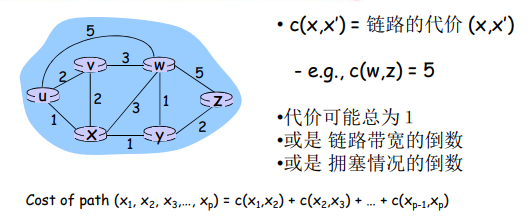
路由的输入:拓扑、边的代价、源节点
输出的输出:源节点的汇集树
最优化原则(optimality principle)
- 汇集树(sink tree)
- 此节点到所有其他节点的最优路径形成的树
- 路由选择算法就是为所有路由器找到并使用汇集树
路由的原则
路由选择算法的原则
正确性(correctness):算法必须是正确的和完整的,使分组一站一站接力,正确发向目标站;
完整:目标所有的站地址,在路由表中都能找到相应的表项;没有处理不了的目标站地址;
简单性(simpliity):算法在计算机上应简单:最优但复杂的算法,时间上延迟很大,不实用, 不应为了获取路由信息增加很多的通信量;
健壮性(robustness):算法应能适应 通信量 和 网络拓扑 的变化:通信量变化,网络拓扑的变化算法能很快适应;不向很拥挤的链路发送数据,不向断了的链路发送数据;
路由选择算法的原则
- 稳定性(stability):产生的路由不应该摇摆
- 公平性(fairness):对每一个站点都公平
- 最优性(optimality):某一个指标的最优,时间上,费用上,等指标,或综合指标;实际上,获取最优的结果代价较高,可以是次优的
路由算法分类
全局或者局部路由信息?
全局:
- 所有的路由器拥有完整的拓扑和边的代价的信息
- “link state”算法
分布式:
- 路由器只知道与它有物理连接关系的邻居路由器,和到相应邻居路由器的代价值
- 叠代地与邻居交换路由信息、计算路由信息
- “distance vector”算法
静态或者动态的?
静态:
- 路由随时间变化缓慢
动态:
- 路由变化很快
- 周期性更新
- 根据链路代价的变化而变化
非自适应算法(non-adaptive algorithm):
不能适应网络拓扑和通信量的变化,路由表是事先计算好的
自适应路由选择(adaptive algorithm):
能适应网络拓扑和通信量的变化
链路状态路由选择-link state算法
LS路由的工作过程
- 配置 LS路由选择算法的路由工作过程
- 各点通过各种渠道获得整个网络拓扑,网络中所有链路代价等信息(这部分和算法没关系,属于协议和实现)
- 使用LS路由算法,计算本站点到其他站点的最优路径(汇集树),得到路由表
- 按照此路由表转发分组(datagram数据报方式)
- 严格意义上说不是路由的一个步骤
- 分发到输入端口的网络层

链路状态路由选择(link state routing)
LS路由的基本工作过程
发现相邻节点,获知对方网络地址
测量到相邻节点的代价(延迟,开销)
组装一个LS分组,描述它到相邻节点的代价情况
将分组通过扩散的方法发到所有其它路由器
以上 4步 让每个路由器获得 拓扑 和 边代价
通过Dijkstra算法找出最短路径(这才是路由算法)
- 每个节点独立算出来到其他节点(路由器 = 网络)的最短路径
- 迭代算法:第k步能够知道本节点到 k 个其他节点的最短路径
发现相邻节点,获知对方网络地址
一个路由器上电之后,向所有线路发送 HELLO 分组
其他路由器收到 HELLO 分组,回送应答,在应答分组中,告知自己的名字(全局唯一)
在 LAN 中,通过广播 HELLO 分组,获得其他路由器的信息,可以认为引入一个人工节点
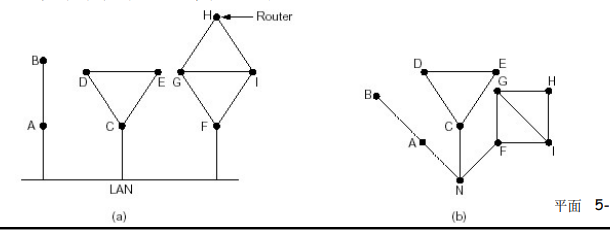
测量到相邻节点的代价(延迟,开销)
- 实测法,发送一个分组要求对方立即响应
- 回送一个 ECHO 分组
- 通过测量时间可以估算出延迟情况
组装一个分组,描述相连节点的情况
- 发送者名称
- 序号,年龄
- 列表:给出它相邻节点,和它到相邻节点的延迟
将分组通过扩散的方法发到所有其他路由器
顺序号:用于控制无穷的扩散,每个路由器都记录(源路由器,顺序号),发现重复的或老的就不扩散
- 具体问题1:循环使用问题
- 具体问题2:路由器崩溃之后序号从0开始
- 具体问题3:序号出现错误
解决问题的办法:年龄字段(age)
- 生成一个分组时,年龄字段不为0
- 每个一个时间段,AGE字段减1
- AGE字段为0的分组将被抛弃
关于扩散分组的数据结构
- Source:从哪个节点收到 LS 分组
- Seq,Age:序号,年龄
- Send flags:发送标记,必须向指定的哪些相邻站点转发 LS 分组
- ACK flags:本站点必须向哪些相邻站点发送应答
- DATA:来自source 站点的 LS 分组
- 节点 B 的数据结构
通过Dijkstra算法找出最短路径
- 路由器获得各站点 LS 分组和整个网络的拓扑
- 通过 Dijkstra 算法计算出到其他个路由器的最短路径(汇集树)
- 将计算结果安装到路由表中
LS的应用情况
- OSPF协议是一种 LS 协议,被用于 Internet上
- IS-IS(intermediate system - intermediate system):被用于 Internet主干中,Netware
符号标记
- c(i,j):从节点 i 到 j 链路代价(初始状态下非相邻节点之间的链路代价为 ∞)
- D(v):从源节点到节点 V 的当前路径代价(节点的代价)
- p(v):从源到节点v的路径前序节点
- N’ :当前已经知道最优路径的节点集合(永久节点的集合)
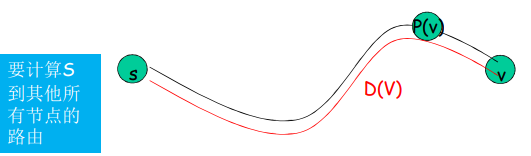
LS 路由选择算法的工作原理
- 节点标记:每一个节点使用(D(v),p(v))如:(3,B)标记
- D(v) 从源节点由已知最优路径到达本节点的 距离
- P(v) 前序节点 来标注
- 2 类节点
- 临时节点(tentative node):还没有找到从源节点到此节点的最优路径的节点
- 永久节点(permanent node)N’ :已经找到了从源节点到此节点的最优路径的节点
- 初始化
- 除了源节点外,所有节点都为临时节点
- 节点代价除了与源节点代价相邻的节点外,都为 ∞
- 从所有临时节点中找到一个节点代价最小的临时节点,将之变成永久节点(当前节点)W
- 对此节点的所有在临时节点集合中的邻节点(V)
- 如 D(v) > D(w) + c(w,v),则重新标注此点,(D(w) + C(w,v),w)
- 否则,不重新标注
- 开始一个新的循环
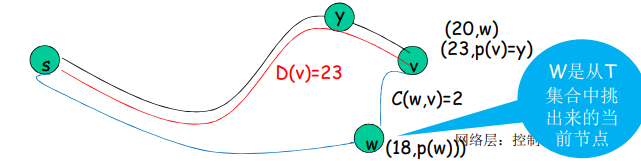
- 节点标记:每一个节点使用(D(v),p(v))如:(3,B)标记
例子:
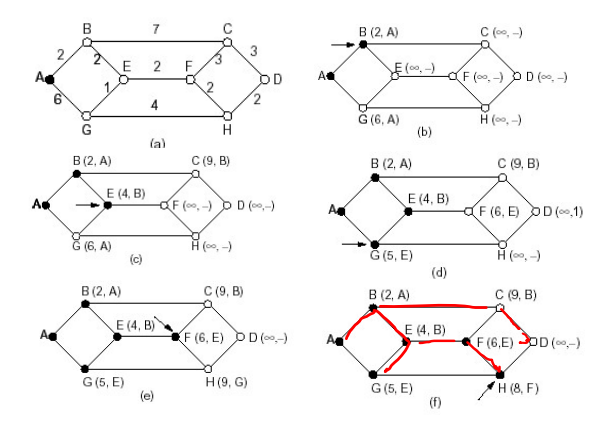
Dijkstra 算法的例子
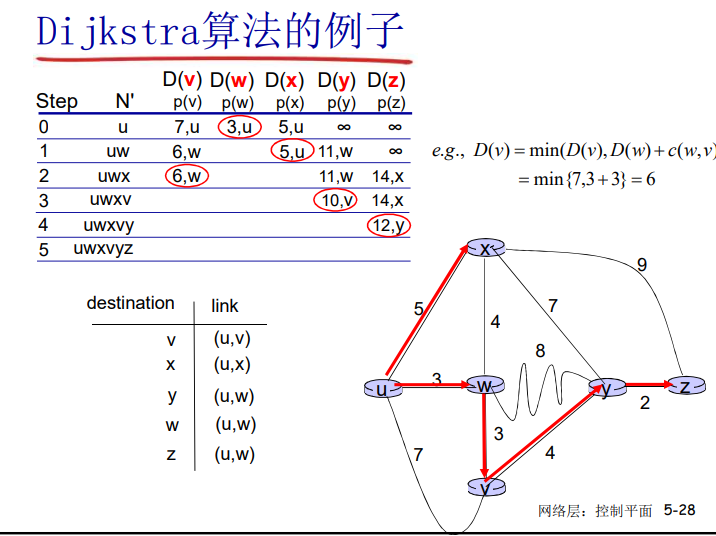
Dijkstra 算法的讨论
算法复杂度:n 节点
- 每一次迭代:需要检查所有不在永久集合 N 中节点
- n(n+1) / 2 次比较:O(n^2)
- 由很有效的视线:O(nlogn)
可能得震荡:
e.g. ,链路代价 = 链路承载的流量:
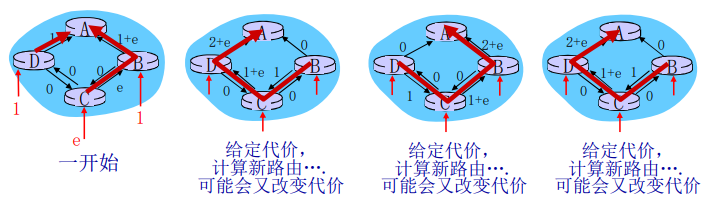
距离矢量路由选择-distance vector
距离矢量路由选择(distance vector)
动态路由算法之一
DV 算法历史及应用情况

距离矢量路由选择的基本思想
各路由器维护一张路由表,结构如图(其他代价)
各路由器与相邻路由器交换路由表(持续)
根据获得的路由信息,更新路由表(持续)
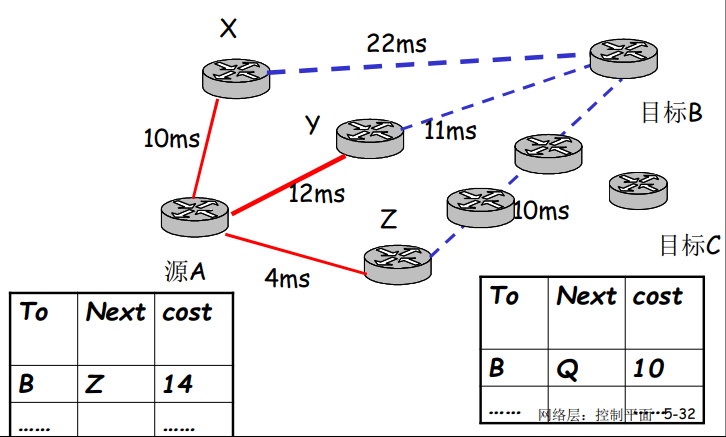
- 代价及相邻节点键代价的获得
- 跳数(hops),延迟(delay),队列长度
- 相邻节点间代价的获得:通过实测
- 路由信息的更新
- 根据实测,得到本节点 A 到相邻站点的代价(如:延迟)
- 根据各相邻站点声称它们到目标站点 B 的代价
- 找到一个最小的代价,和响应的 下一个节点Z,到达节点 B 经过此节点Z,并且代价为 A-Z-B的代价
- 其他所有的目标节点一个计算法